苹果|人类已经阻止不了苹果翻译了?( 二 )
Google 翻译用到的是 Seq2Seq (Sequence to Sequence) 模型 , Seq2Seq 由两个循环神经网络模型协力组成 , 一个用于对输入序列进行编码 , 一个用于对输出序列进行解码 。
当输入中文“知识就是力量”时 , 编码模型把每个字都标上一个矢量 , 其中每个矢量代表到目前为止已读取的所有字的含义 。 在整个句子编码结束后 , 解码器即会开始生成对应的英语句子 。
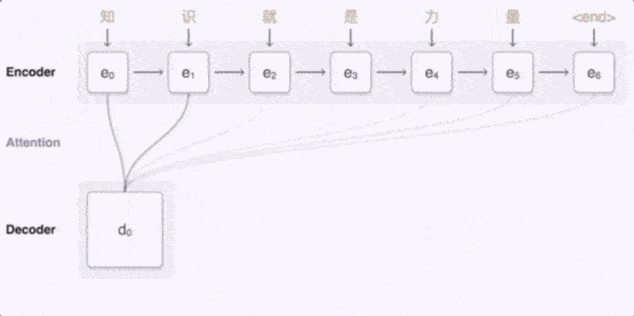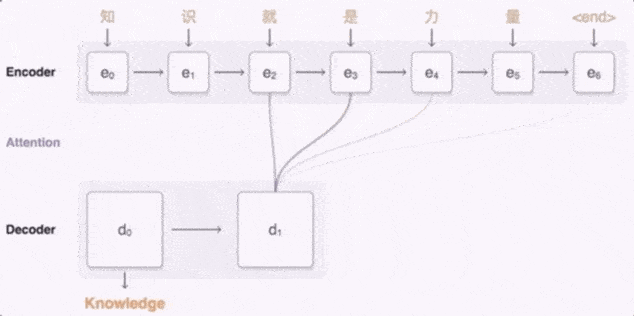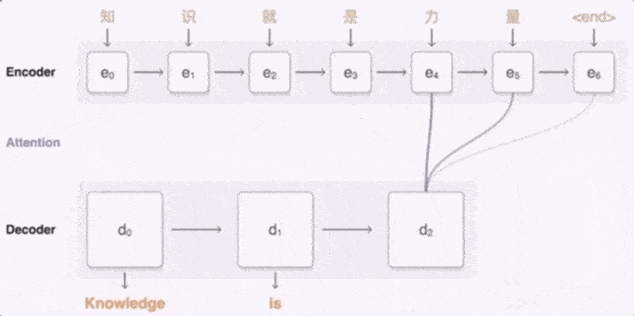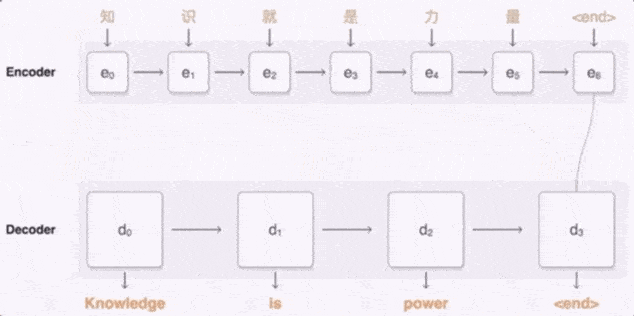
文章图片
通过分析大量的语料数据 , 模型能自动从中学习出相应的语法规则 , 也就是说 , 工程师教给模型什么 , 模型就学会什么 。 因此 , 苹果的工程师可能为苹果翻译 feed 了太多网络平行语料 , 导致苹果翻译被网络用语“污染” , 而识别不出文本原来的含义 。
苹果翻译出现失误的另一个可能性是 , 苹果翻译引入了知识图谱 。
知识图谱是 Google 于 2012 年提出的概念 , 本质上是一种基于图的数据结构 。 在知识图谱中 , 每个名词(又叫实体)都是一个节点 , 每个节点间又有逻辑关系线相连 。 通过这种知识图谱 , 神经网络能更好地理解上下文之间的关联 。
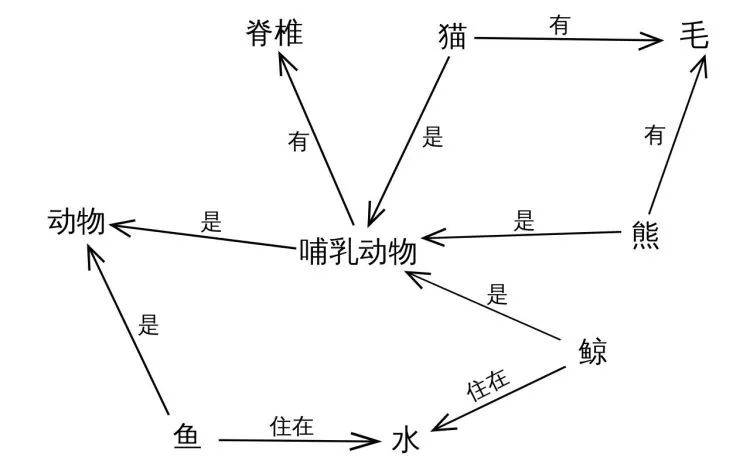
文章图片
▲ 一种知识图谱示意图
也许在苹果翻译构建的知识图谱中 , “五五开”被链接到“卢本伟”这个实体 , 而这个实体又可以被翻译为“Lu Benwei” , 同理 , “滚筒洗衣机”也可能被链接到了“工藤新一”这个实体 。
因为网络平行语料和知识图谱的存在 , 翻译模型在面对独立的名词时很容易翻车 。 比如说“瓜皮” , 苹果直接按方言理解 , 翻译成“笨蛋” 。

文章图片
▲ "方言本当上手"
不过 , 根据我们对它原理的判断 , 想要更准确的翻译 , 解决方法之一就是在苹果翻译出现错误时 , 我们可以尝试为文本添加上下文 , 来帮助模型更好地理解 。
比如把“瓜皮”改成“我不吃瓜皮” , 把“滚筒洗衣机”改成“滚筒洗衣机多少钱” 。

文章图片
苹果的这些翻译确实带来了很多乐趣 , 但当人们真的需要用它来完成跨语言沟通时 , 又不由得捏一把汗 。
现在问题来了 , 这样的苹果翻译你喜欢吗?
_原题为 《人类已经阻止不了苹果翻译了》
阅读原文
推荐阅读














- 下饭视频|金。卡戴珊穿衣太斗胆! “电光蓝”皮裤已经安排上, 尽显曼妙身材
- 陕西|百名主播入百企助销陕西苹果
- 陕西苹果产业|宝鸡苹果产业“千阳模式” 推动苹果产业高质量发展
- 上游新闻|美国爆发水貂新冠疫情,上万只水貂被人类传染后死亡
- 牛头人|魔兽世界中已经被遗忘的有趣设定,风怒无限触发,牛头人没有坐骑
- 巴基斯坦|印军称已经做好空袭准备,底气在哪?5架阵风战机够用吗
- 诺贝尔|孩子问诺贝尔奖成果有多牛?影响人类生活的十大诺奖成果,一定要讲给孩子|特别关注
- 科学|人类能挖穿地球吗?前苏联挖到了12263米,发现了大量黄金和钻石
- 科学|人类能把地球凿穿吗?前苏联用了24年实验最终得出结论
- 三农|消费扶贫e起来 百名主播入百企 助推陕西苹果销售活动启动