定义|反向传播算法:定义,概念,可视化
定义
向前传播
通常,当我们使用神经网络时,我们输入某个向量x,然后网络产生一个输出y,这个输入向量通过每一层隐含层,直到输出层。这个方向的流动叫做正向传播。
在训练阶段,输入最后可以计算出一个代价标量J(θ)。
反向传播算法
然后,代价通过反向算法返回到网络中,调整权重并计算梯度。未完待续……
分析
可能是你们在学校里做过用代数的方法来分析反向传播。对于普通函数,这很简单。但当解析法很困难时,我们通常尝试数值微分。
数值微分
由于代数操作很困难,在数值方法中,我们通常使用计算量大的方法,因此经常需要用到计算机。一般有两种方法,一种是利用近邻点,另一种是利用曲线拟合。
随机梯度下降法
负责“学习”的算法。它使用了由反向传播算法产生的梯度。
反向传播算法
然后,反向传播算法返回到网络中,调整权重来计算梯度。一般来说,反向传播算法不仅仅适用于多层感知器。它是一个通用的数值微分算法,可以用来找到任何函数的导数,只要给定函数是可微的。
该算法最重要的特点之一是,它使用了一个相对简单和廉价的程序来计算微分,提高效率。
如何计算一个代价函数的梯度
给定一个函数f,我们想要找到梯度:
x是一组我们需要它的导数的变量,y是额外的变量,我们不需要它的导数。
为了使网络继续学习,我们想要找到代价函数的梯度。
损失函数
这个函数通常应用于一个数据点,寻找预测点和实际点之间的距离。大多数情况下,这是距离的平方损失。
代价函数
这个函数是所有损失函数的组合,它不总是一个和。但有时是平均值或加权平均值。例如: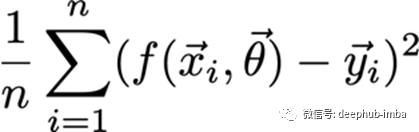
文章图片
如何计算一个代价函数的梯度
给定一个函数f,我们想要找到梯度:
x是一组我们需要它的导数的变量,y是额外的变量,我们不需要它的导数。
为了网络的学习,我们想要找到代价函数的梯度。
微积分链式法则
假设x是实数,f和g都是实数到实数的映射函数。此外,
根据链式法则,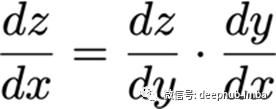
文章图片
多变量链式法则
已知x和y是不同维数的向量,
g和f也是从一个维度映射到另一个维度的函数,
文章图片
或者说,
?y /?x是g的n×m雅可比矩阵。
梯度
而导数或微分是沿一个轴的变化率。梯度是一个函数沿多个轴的斜率矢量。
雅可比矩阵
【 定义|反向传播算法:定义,概念,可视化】有时我们需要找出输入和输出都是向量的函数的所有偏导数。包含所有这些偏导数的矩阵就是雅可比矩阵。
有函数
雅可比矩阵J为:
张量的链式法则
我们大部分时间都在处理高维数据,例如图像和视频。所以我们需要将链式法则扩展到张量。
想象一个三维张量,
z值对这个张量的梯度是,
对于这个张量, i?? 指数给出一个向量,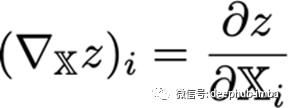
文章图片
所以考虑到这一点,
张量的链式法则是,
概念
计算图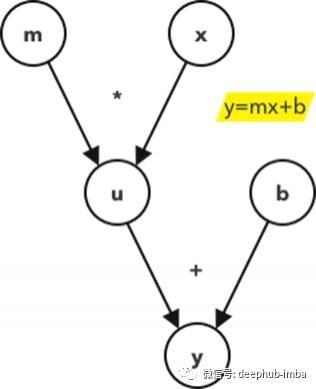
文章图片
这是一个关于直线方程的计算图的例子。开始节点是你将在方程中看到的,为了计算图的方便,总是需要为中间节点定义额外的变量,在这个例子中是节点u。节点“u”等价于“mx”。
我们引入这个概念来说明复杂的计算流程的支撑算法。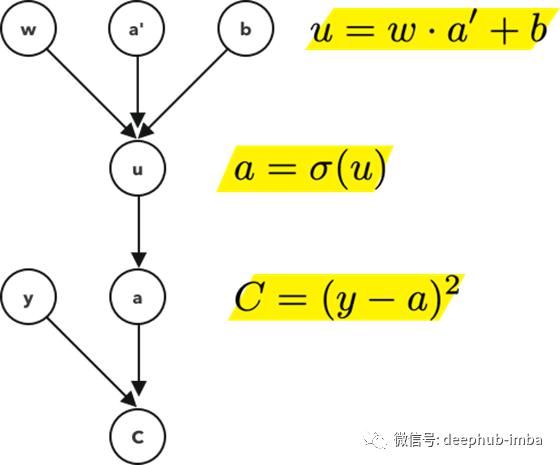
文章图片
还记得之前,当我们把损失函数定义为差的平方,这就是我们在计算图的最后一层使用的。其中y是实际值a是预测值。
请注意,我们的损失值严重依赖于最后的激活值,而最后的激活值又依赖于前一个激活值,再依赖于前一个激活值,以此类推。
在神经网络的前进过程中,我们最终得到一个预测值a。在训练阶段,我们有一个额外的信息,这就是网络应该得到的实际结果,y。我们的损失函数就是这些值之间的距离。当我们想要最小化这个距离时,我们首先要更新最后一层的权重。但这最后一层依赖于它的前一层,因此我们更新它们。所以从这个意义上说,我们是在向后传递神经网络并更新每一层。
敏感性改变
当x的一个小变化导致函数f的一个大变化时,我们说函数对x非常敏感如果x的一个小变化导致f的一个小变化,我们说它不是很敏感。
例如,一种药物的有效性可用f来衡量,而x是所使用的剂量。灵敏度表示为:
为了进一步扩展,我们假设现在的函数是多变量的。
函数f可以对每个输入有不同的敏感度。举个例子,也许仅仅进行数量分析是不够的,所以我们把药物分解成3种活性成分,然后考虑每种成分的剂量。
最后一点扩展,如果其中一个输入值,比如x也依赖于它自己的输入。我们可以用链式法则来找出敏感性。同样的例子,也许x被分解成它在身体里的组成部分,所以我们也要考虑这个。
推荐阅读















- 特朗普|福奇谈白宫“超级传播事件”
- 病毒|美国养殖场约10000只水貂死于新冠 由人传播给动物
- Google|谷歌开的这场轻量级发布会,重新定义了什么是旗舰机
- 传播|5G 赋能未来传播:变革的前瞻
- 传播|美政府仍寻求群体免疫?专家警告:这是个危险的想法
- 新冠|美疾控中心承认新冠病毒可经气溶胶传播
- 霍尊|中国好声音:匹诺曹六人合力都不及霍尊,反向证明了原唱的强大
- |意大利1周新增新冠传播链逾900处 近千学校现疫情
- 西瓜|《街舞3》队长吃瓜:王一博反向劝退王嘉尔,张艺兴脸都吃没了
- 传播|高通侯明娟:让高质量内容与领先技术相结合,更好地服务消费者