ж·ұеәҰеҚ·з§Ҝ|ж·ұе…ҘеҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјҡй«ҳзә§еҚ·з§ҜеұӮеҺҹзҗҶе’Ңи®Ўз®—зҡ„еҸҜи§ҶеҢ–
еңЁж·ұеәҰи®Ўз®—жңәи§Ҷи§үйўҶеҹҹдёӯпјҢжңүеҮ з§Қзұ»еһӢзҡ„еҚ·з§ҜеұӮдёҺжҲ‘们з»ҸеёёдҪҝз”Ёзҡ„еҺҹе§ӢеҚ·з§ҜеұӮдёҚеҗҢгҖӮеңЁи®Ўз®—жңәи§Ҷи§үзҡ„ж·ұеәҰеӯҰд№ з ”з©¶ж–№йқўпјҢи®ёеӨҡжөҒиЎҢзҡ„й«ҳзә§еҚ·з§ҜзҘһз»ҸзҪ‘з»ңе®һзҺ°йғҪдҪҝз”ЁдәҶиҝҷдәӣеұӮгҖӮиҝҷдәӣеұӮдёӯзҡ„жҜҸдёҖеұӮйғҪжңүдёҚеҗҢдәҺеҺҹе§ӢеҚ·з§ҜеұӮзҡ„жңәеҲ¶пјҢиҝҷдҪҝеҫ—жҜҸз§Қзұ»еһӢзҡ„еұӮйғҪжңүдёҖдёӘзү№еҲ«зү№ж®Ҡзҡ„еҠҹиғҪгҖӮ
еңЁиҝӣе…Ҙиҝҷдәӣй«ҳзә§зҡ„еҚ·з§ҜеұӮд№ӢеүҚпјҢи®©жҲ‘们е…Ҳеҝ«йҖҹеӣһйЎҫдёҖдёӢеҺҹе§Ӣзҡ„еҚ·з§ҜеұӮжҳҜеҰӮдҪ•е·ҘдҪңзҡ„гҖӮ
еҺҹе§ӢеҚ·з§ҜеұӮ
еңЁеҺҹе§Ӣзҡ„еҚ·з§ҜеұӮдёӯпјҢжҲ‘们жңүдёҖдёӘеҪўзҠ¶дёәWxHxCзҡ„иҫ“е…ҘпјҢе…¶дёӯWе’ҢHжҳҜжҜҸдёӘfeature mapзҡ„е®ҪеәҰе’Ңй«ҳеәҰпјҢCжҳҜchannelзҡ„ж•°йҮҸпјҢеҹәжң¬дёҠе°ұжҳҜfeature mapзҡ„жҖ»ж•°гҖӮеҚ·з§ҜеұӮдјҡжңүдёҖе®ҡж•°йҮҸзҡ„ж ёпјҢж ёдјҡеҜ№иҝҷдёӘиҫ“е…ҘиҝӣиЎҢеҚ·з§Ҝж“ҚдҪңгҖӮеҶ…ж ёзҡ„ж•°йҮҸе°ҶзӯүдәҺиҫ“еҮәfeature mapдёӯжүҖйңҖйҖҡйҒ“зҡ„ж•°йҮҸгҖӮеҹәжң¬дёҠпјҢжҜҸдёӘеҶ…ж ёйғҪеҜ№еә”дәҺиҫ“еҮәдёӯзҡ„дёҖдёӘзү№е®ҡзҡ„feature mapпјҢ并且жҜҸдёӘfeature mapйғҪжҳҜдёҖдёӘйҖҡйҒ“гҖӮ
ж ёзҡ„й«ҳеәҰе’Ңе®ҪеәҰжҳҜз”ұжҲ‘们еҶіе®ҡзҡ„пјҢйҖҡеёёпјҢжҲ‘们дҝқжҢҒ3x3гҖӮжҜҸдёӘеҶ…ж ёзҡ„ж·ұеәҰе°ҶзӯүдәҺиҫ“е…Ҙзҡ„йҖҡйҒ“ж•°гҖӮеӣ жӯӨпјҢеҜ№дәҺдёӢйқўзҡ„дҫӢеӯҗпјҢжҜҸдёӘеҶ…ж ёзҡ„еҪўзҠ¶е°ҶжҳҜ(wxhx3)пјҢе…¶дёӯwе’ҢhжҳҜеҶ…ж ёзҡ„е®ҪеәҰе’Ңй«ҳеәҰпјҢж·ұеәҰжҳҜ3пјҢеӣ дёәеңЁиҝҷз§Қжғ…еҶөдёӢпјҢиҫ“е…Ҙжңү3дёӘйҖҡйҒ“гҖӮ
ж–Үз« еӣҫзүҮ
еңЁжң¬дҫӢдёӯпјҢиҫ“е…Ҙжңү3дёӘйҖҡйҒ“пјҢиҫ“еҮәжңү16дёӘйҖҡйҒ“гҖӮеӣ жӯӨеңЁиҝҷдёҖеұӮе…ұжңү16дёӘеҶ…ж ёпјҢжҜҸдёӘеҶ…ж ёзҡ„еҪўзҠ¶жҳҜ(wxhx3)гҖӮ
й«ҳзә§зҡ„еҚ·з§ҜеұӮ
жҲ‘们е°ҶеңЁжң¬ж•ҷзЁӢдёӯж¶өзӣ–зҡ„й«ҳзә§еҚ·з§ҜеұӮзҡ„еҲ—иЎЁеҰӮдёӢ:
ж·ұеәҰеҸҜеҲҶзҰ»зҡ„еҚ·з§Ҝ
еҸҚеҚ·з§Ҝ
з©әжҙһеҚ·з§Ҝ
еҲҶз»„еҚ·з§Ҝ
ж·ұеәҰеҸҜеҲҶзҰ»зҡ„еҚ·з§ҜеұӮ
еңЁж·ұеәҰеҸҜеҲҶзҰ»еҚ·з§ҜеұӮдёӯпјҢжҲ‘们иҜ•еӣҫжһҒеӨ§ең°еҮҸе°‘еңЁжҜҸдёӘеҚ·з§ҜеұӮдёӯжү§иЎҢзҡ„и®Ўз®—ж•°йҮҸгҖӮиҝҷдёҖж•ҙеұӮе®һйҷ…дёҠиў«еҲҶдёәдёӨйғЁеҲҶ:
i)ж·ұеәҰеҚ·з§Ҝ
ii)йҖҗзӮ№еҚ·з§Ҝ
ж·ұеәҰеҚ·з§Ҝ
ж·ұеәҰеҚ·з§Ҝзҡ„е…ій”®зӮ№еңЁдәҺпјҢжҜҸдёӘж ёеҮҪж•°йғҪжҳҜеә”з”ЁеңЁеҚ•дёӘиҫ“е…ҘйҖҡйҒ“дёҠпјҢиҖҢдёҚжҳҜеҗҢж—¶еә”з”ЁжүҖжңүзҡ„иҫ“е…ҘйҖҡйҒ“гҖӮеӣ жӯӨпјҢжҜҸдёӘеҶ…ж ёйғҪжҳҜеҪўзҠ¶(w*h*1)зҡ„пјҢеӣ дёәе®ғе°Ҷеә”з”ЁдәҺеҚ•дёӘйҖҡйҒ“гҖӮеҶ…ж ёзҡ„ж•°йҮҸе°ҶзӯүдәҺиҫ“е…ҘйҖҡйҒ“зҡ„ж•°йҮҸпјҢеӣ жӯӨпјҢеҰӮжһңжҲ‘们жңүW*H*3еӨ§е°Ҹзҡ„иҫ“е…ҘпјҢжҲ‘们е°Ҷжңү3дёӘеҚ•зӢ¬зҡ„W*H*1еҶ…ж ёпјҢжҜҸдёӘеҶ…ж ёе°Ҷеә”з”ЁдәҺиҫ“е…Ҙзҡ„еҚ•дёӘйҖҡйҒ“гҖӮеӣ жӯӨпјҢиҫ“еҮәд№ҹе°Ҷе…·жңүдёҺиҫ“е…ҘзӣёеҗҢж•°йҮҸзҡ„йҖҡйҒ“пјҢеӣ дёәжҜҸдёӘеҶ…ж ёе°Ҷиҫ“еҮәеҚ•дёӘfeature mapгҖӮи®©жҲ‘们зңӢзңӢж·ұеәҰеҚ·з§ҜйғЁеҲҶжҳҜеҰӮдҪ•е·ҘдҪңзҡ„:
ж–Үз« еӣҫзүҮ
еҰӮжһңжҲ‘们жңүдёҖдёӘCйҖҡйҒ“зҡ„иҫ“е…ҘпјҢйӮЈд№ҲиҝҷдёҖеұӮзҡ„ж·ұеәҰеҚ·з§ҜйғЁеҲҶзҡ„иҫ“еҮәд№ҹдјҡжңүCйҖҡйҒ“гҖӮжҺҘдёӢжқҘжҳҜдёӢдёҖйғЁеҲҶгҖӮиҝҷдёҖйғЁеҲҶзҡ„зӣ®зҡ„жҳҜж”№еҸҳйў‘йҒ“зҡ„ж•°йҮҸпјҢеӣ дёәйҡҸзқҖжҲ‘们ж·ұе…ҘдәҶи§ЈCNNпјҢжҲ‘们з»ҸеёёеёҢжңӣеўһеҠ жҜҸдёҖеұӮиҫ“еҮәзҡ„йў‘йҒ“ж•°йҮҸгҖӮ
йҖҗзӮ№еҚ·з§Ҝ
йҖҗзӮ№еҚ·з§Ҝе°ҶжҠҠж·ұеәҰеҚ·з§Ҝзҡ„дёӯй—ҙCйҖҡйҒ“иҫ“еҮәиҪ¬жҚўдёәе…·жңүдёҚеҗҢж•°йҮҸйҖҡйҒ“зҡ„feature mapгҖӮдёәдәҶеҒҡеҲ°иҝҷдёҖзӮ№пјҢжҲ‘们жңүеҮ дёӘ1\s*1зҡ„еҶ…ж ёпјҢе®ғ们еңЁиҝҷдёӘдёӯй—ҙfeature mapеқ—зҡ„жүҖжңүйҖҡйҒ“дёҠиҝӣиЎҢеҚ·з§ҜгҖӮеӣ жӯӨпјҢжҜҸдёӘ1*1еҶ…ж ёд№ҹе°ҶжңүCйҖҡйҒ“гҖӮжҜҸдёӘеҶ…ж ёе°Ҷиҫ“еҮәдёҖдёӘеҚ•зӢ¬зҡ„feature mapпјҢеӣ жӯӨжҲ‘们е°Ҷеҫ—еҲ°зҡ„еҶ…ж ёж•°йҮҸдёҺжҲ‘们еёҢжңӣиҫ“еҮәзҡ„йҖҡйҒ“ж•°йҮҸзӣёзӯүгҖӮи®©жҲ‘们зңӢзңӢиҝҷжҳҜеҰӮдҪ•е·ҘдҪңзҡ„гҖӮ
ж–Үз« еӣҫзүҮ
иҝҷе°ұжҳҜж·ұеәҰеҸҜеҲҶзҰ»еҚ·з§ҜеұӮзҡ„ж•ҙдёӘиҝҮзЁӢгҖӮеҹәжң¬дёҠпјҢеңЁж·ұеәҰеҚ·з§Ҝзҡ„第дёҖжӯҘпјҢжҜҸдёӘиҫ“е…ҘйҖҡйҒ“йғҪжңүдёҖдёӘж ёеҮҪ数然еҗҺе°Ҷе®ғ们дёҺиҫ“е…ҘиҝӣиЎҢеҚ·з§ҜгҖӮиҝҷж ·зҡ„з»“жһңиҫ“еҮәе°ҶжҳҜдёҖдёӘfeature mapеқ—пјҢе®ғе…·жңүдёҺиҫ“е…ҘзӣёеҗҢж•°йҮҸзҡ„йҖҡйҒ“гҖӮеңЁйҖҗзӮ№еҚ·з§Ҝзҡ„第дәҢжӯҘдёӯпјҢжҲ‘们жңүеҮ дёӘ1*1зҡ„ж ёпјҢ并е°Ҷе®ғ们дёҺдёӯй—ҙзү№еҫҒжҳ е°„еқ—иҝӣиЎҢеҚ·з§ҜгҖӮжҲ‘们е°Ҷж №жҚ®жҲ‘们еёҢжңӣиҫ“еҮәзҡ„йҖҡйҒ“ж•°йҮҸжқҘйҖүжӢ©еҶ…ж ёзҡ„ж•°йҮҸгҖӮ
иҝҷдёҖеұӮжҜ”еҺҹжқҘзҡ„еҚ·з§ҜеұӮиҰҒиҪ»йҮҸеҫ—еӨҡгҖӮиҝҷжҳҜеӣ дёәпјҢеңЁз¬¬дёҖжӯҘдёӯпјҢжҲ‘们没жңүдҪҝз”Ёе·ЁеӨ§зҡ„еҚ·з§ҜеңЁжүҖжңүиҫ“е…ҘйҖҡйҒ“дёҠзҡ„еҶ…ж ёпјҢиҖҢжҳҜдҪҝз”ЁеҚ•йҖҡйҒ“зҡ„еҶ…ж ёпјҢиҝҷе°Ҷдјҡе°Ҹеҫ—еӨҡгҖӮ然еҗҺеңЁдёӢдёҖжӯҘпјҢеҪ“жҲ‘们иҜ•еӣҫж”№еҸҳйҖҡйҒ“зҡ„ж•°йҮҸж—¶пјҢжҲ‘们дҪҝз”ЁдәҶеҜ№жүҖжңүйҖҡйҒ“иҝӣиЎҢеҚ·з§Ҝзҡ„еҶ…ж ёпјҢдҪҶжҳҜиҝҷдәӣеҶ…ж ёжҳҜ1*1зҡ„пјҢеӣ жӯӨе®ғ们д№ҹиҰҒе°Ҹеҫ—еӨҡгҖӮжң¬иҙЁдёҠпјҢжҲ‘们еҸҜд»ҘжҠҠж·ұеәҰеҸҜеҲҶзҰ»еҚ·з§ҜзңӢдҪңжҳҜжҠҠеҺҹжқҘзҡ„еҚ·з§ҜеұӮеҲҶжҲҗдёӨйғЁеҲҶгҖӮ第дёҖйғЁеҲҶдҪҝз”Ёе…·жңүиҫғеӨ§з©әй—ҙеҢәеҹҹ(е®ҪеәҰе’Ңй«ҳеәҰ)дҪҶеҸӘжңүдёҖдёӘйҖҡйҒ“зҡ„еҶ…ж ёпјҢ第дәҢйғЁеҲҶдҪҝз”Ёи·Ёи¶ҠжүҖжңүйҖҡйҒ“зҡ„еҶ…ж ёпјҢдҪҶе®ғ们жңүиҫғе°Ҹзҡ„з©әй—ҙеҢәеҹҹгҖӮ
ж·ұеәҰеҸҜеҲҶзҰ»зҡ„еҚ·з§ҜеұӮеңЁз§»еҠЁзҪ‘з»ңдёӯдҪҝз”ЁпјҢеӣ дёәиҝҷж ·CNNжңүжӣҙе°‘зҡ„еҸӮж•°пјҢд»Ҙдҫҝ他们еҸҜд»ҘеңЁз§»еҠЁи®ҫеӨҮдёҠдҪҝз”ЁгҖӮе®ғ们д№ҹиў«з”ЁдәҺXception CNNжһ¶жһ„дёӯгҖӮ
еҸҚеҚ·з§ҜеұӮ
йҖҡеёёеңЁеҚ·з§ҜеұӮдёӯпјҢfeature mapsзҡ„з©әй—ҙйқўз§Ҝ(width and height)еңЁжҜҸеұӮд№ӢеҗҺдјҡеҮҸе°ҸжҲ–дҝқжҢҒдёҚеҸҳгҖӮдҪҶжңүж—¶жҲ‘们жғіеўһеҠ з©әй—ҙйқўз§ҜгҖӮиҝҷдәӣеўһеҠ з©әй—ҙйқўз§ҜиҖҢдёҚжҳҜеҮҸе°‘з©әй—ҙйқўз§Ҝзҡ„зү№ж®ҠеұӮз§°дёәеҸҚеҚ·з§ҜеұӮгҖӮжңүдёӨз§Қдё»иҰҒзұ»еһӢзҡ„еҸҚеҚ·з§ҜеұӮ:
иҪ¬зҪ®еҚ·з§Ҝ
дёҠйҮҮж ·
дёӨиҖ…еңЁжҹҗдәӣж–№йқўжҳҜзӣёдјјзҡ„пјҢдҪҶд№ҹжңүдёҖдәӣе·®ејӮгҖӮжң¬иҙЁдёҠпјҢе…¶зӣ®зҡ„жҳҜеңЁеә”з”ЁеҚ·з§Ҝд№ӢеүҚпјҢйҖҡиҝҮеңЁfeature mapдёӯеј•е…ҘжӣҙеӨҡзҡ„еғҸзҙ жқҘеўһеҠ з©әй—ҙйқўз§ҜгҖӮеЎ«е……иҝҷдәӣж–°еғҸзҙ еҖјзҡ„ж–№ејҸеҪўжҲҗдәҶиҪ¬зҪ®еҚ·з§Ҝе’ҢдёҠйҮҮж ·д№Ӣй—ҙзҡ„дё»иҰҒеҢәеҲ«гҖӮж·»еҠ ж–°еғҸзҙ зҡ„ж–№ејҸеҰӮдёӢ: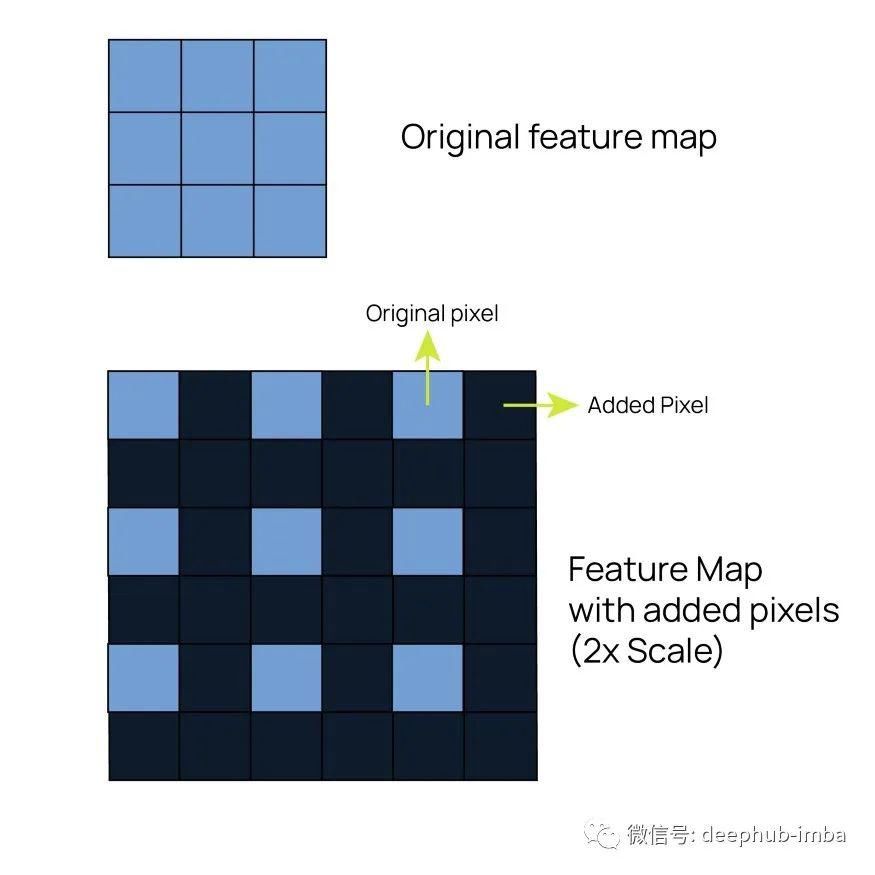
ж–Үз« еӣҫзүҮ
еңЁи°ғж•ҙfeature mapзҡ„еӨ§е°Ҹж—¶пјҢжҲ‘们еҸҜд»Ҙж”№еҸҳжү©е……жҜ”дҫӢпјҢдҪҶйҖҡеёёжғ…еҶөдёӢпјҢжҲ‘们еҒҡзҡ„жҳҜ2еҖҚзҡ„жү©е……гҖӮиҝҷж ·пјҢfeature mapзҡ„й«ҳеәҰе’Ңе®ҪеәҰдјҡзҝ»еҖҚпјҢеӣ жӯӨеғҸзҙ зҡ„жҖ»ж•°жҳҜеҺҹе§Ӣfeature mapзҡ„4еҖҚгҖӮ
иҪ¬зҪ®еҚ·з§Ҝ
еңЁиҪ¬зҪ®еҚ·з§ҜдёӯпјҢжҲ‘们еҸӘжҳҜз”Ё0зҡ„еҖјеЎ«е……жүҖжңүеўһеҠ зҡ„еғҸзҙ гҖӮиҝҷжңүзӮ№еғҸеңЁfeature mapзҡ„еҺҹе§ӢеғҸзҙ д№Ӣй—ҙж·»еҠ еЎ«е……гҖӮ
жҺЁиҚҗйҳ…иҜ»


![[еқҰиЁҖ]收е…ҘжҸҗй«ҳдәҶпјҹж»ҙж»ҙеҸёжңәеқҰиЁҖпјҡеӣ дёәе№іеҸ°иҝҷжіўж“ҚдҪңпјҢзҺ°еңЁж”¶е…Ҙ](/renwen/images/defaultpic.gif)














- жҙҫеҮәжүҖ|жі°е®үеёӮе…¬е®үеұҖеІұеІіеҲҶеұҖзҘқйҳіжҙҫеҮәжүҖж·ұе…ҘйӣҶеёӮејҖеұ•е®үе…ЁйҳІиҢғе®Јдј
- еҶңдёҡ科жҠҖзӨҫдјҡеҢ–жңҚеҠЎ|ж”ҝеәңеҠ ејәеҶңдёҡ科жҠҖзӨҫдјҡеҢ–жңҚеҠЎдҪ“зі»е»әи®ҫ 2020еҶңдёҡ科жҠҖиЎҢдёҡеёӮеңәж·ұеәҰеҲҶжһҗ
- жҷәиғҪ硬件|жӯҢе°”иӮЎд»Ҫж·ұеәҰи§ЈжһҗпјҡTWSиҖіжңәж”ҫйҮҸеј•йўҶеўһй•ҝпјҢзІҫеҜҶеҲ¶йҖ еҶ…еҠҹй“ёе°ұжҲҗй•ҝ
- е№ҝиҘҝиҙөжёҜжёҜеҚ—еҢәжЈҖеҜҹйҷўж·ұе…Ҙд№Ўжқ‘ејҖеұ•зҰҒжҜ’е®Јдј
- дёӯиҖҒе№ҙ|ж·ұеәҰпјҡдёӯиҖҒе№ҙиә«дҪ“жңәиғҪеҸҳеҢ–еӮ¬з”ҹж•°еҚғдәҝдёӯиҖҒе№ҙжңҚиЈ…еёӮеңәпјҒ
- е…үзјҶдә§йҮҸе…үзәӨе…үзјҶ|2020дёҠеҚҠе№ҙе…ЁеӣҪе…үзјҶдә§йҮҸ1.32дәҝиҠҜеҚғзұі 2020е…үзәӨе…үзјҶжқҗж–ҷиЎҢдёҡеёӮеңәж·ұеәҰеҲҶжһҗ
- ж•°еӯ—йҹід№җдёӯеӣҪйҹід№җеҚҺиҜӯж•°еӯ—йҹід№җ|2020е№ҙж•°еӯ—йҹід№җиЎҢдёҡеёӮеңәж·ұеәҰеҲҶжһҗ жҖ»дҪ“й”Җе”®йўқзӘҒз ҙ3дәҝе…ғеӨ§е…і
- и§Ҷйў‘еңЁзәҝи§Ҷйў‘зҪ‘з»ңи§Ҷйў‘|2020е№ҙеңЁзәҝи§Ҷйў‘иЎҢдёҡеёӮеңәж·ұеәҰеҲҶжһҗ зҪ‘з»ңи§Ҷйў‘зӣёе…ідјҒдёҡжіЁеҶҢйҮҸдёә4.2дёҮ家
- жҷәиғҪй—ЁзҰҒдәәи„ёиҜҶеҲ«жҷәж…§еҹҺеёӮ|2020жҷәиғҪй—ЁзҰҒиЎҢдёҡеёӮеңәеҸ‘еұ•и¶ӢеҠҝж·ұеәҰеҲҶжһҗ дәәи„ёиҜҶеҲ«жҲҗдёәжҷәиғҪй—ЁзҰҒдёҖеӨ§и¶ӢеҠҝ
- ж”»з•Ҙ|ж— ж·ұеәҰдёҚдә‘еҚ—вҖ”вҖ”дёҪжұҹе·ҙжӢүзҘһеұұеҫ’жӯҘз©ҝи¶Ҡж”»з•Ҙ