spark on hive дјҳеҢ–?
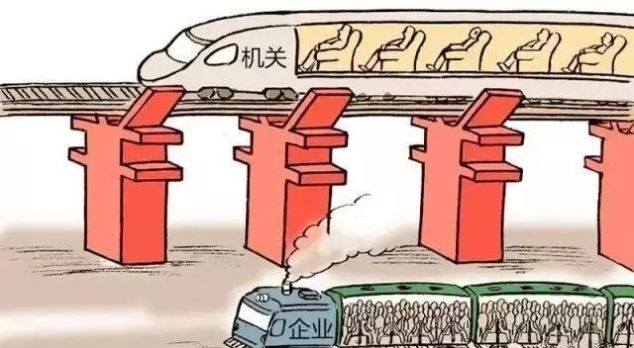
жҲ‘жқҘжҠӣз –еј•зҺүдёҖдёӢеҗ§гҖӮйҰ–е…ҲпјҢжҲ‘们иҰҒжҗһжё…жҘҡ瓶йўҲеңЁе“ӘйҮҢпјҢеҶ…еӯҳиҝҳжҳҜCPUгҖӮйҖҡеёёжқҘиҜҙпјҢеҰӮжһңжҳҜжңәеҷЁеӯҰд№ д№Ӣзұ»зҡ„еә”з”ЁпјҢ瓶йўҲдёҖиҲ¬еңЁCPUпјҢеҰӮжһңжҳҜETLпјҢ瓶йўҲеңЁI/Oзҡ„еҸҜиғҪжҖ§иҰҒеӨ§дёҖзӮ№гҖӮеҰӮдҪ•е®ҡйҮҸзҡ„еҲӨж–ӯ瓶йўҲеңЁе“ӘйҮҢе‘ўпјҢSparkзҡ„web UIжҸҗдҫӣдәҶеҫҲеӨҡдҝЎжҒҜпјҢжҜ”еҰӮеҶ…еӯҳеҚ з”ЁзҺҮзӯүзӯүпјҢеҸҰеӨ–жҲ‘们дҪҝз”Ёзҡ„sparkдёҖиҲ¬йғҪжҳҜжҹҗдёӘеҺӮе•ҶжҸҗдҫӣзҡ„еҸ‘иЎҢзүҲзҡ„дёҖйғЁеҲҶпјҢжҜ”еҰӮClouderaпјҢMapRзӯүзӯүпјҢиҝҷдәӣеҸ‘иЎҢзүҲдјҡжҸҗдҫӣеҫҲиҜҰз»Ҷзҡ„IOжҢҮж ҮгҖӮеҸҜд»Ҙеё®еҠ©дҪ зЎ®и®ӨжҳҜеҗҰжңүI/O瓶йўҲгҖӮи§ЈеҶіI/O瓶йўҲзҡ„ж–№жі•жңүеҫҲеӨҡпјҢеёёи§Ғзҡ„йҒҝе…ҚдҪҝз”ЁgroupByKeyпјҢз”ЁreduceByKey жҲ–иҖ…combineByKeyд»Јжӣҝз”ЁKryoеәҸеҲ—еҢ–д»ЈжӣҝjavaиҮӘе·ұзҡ„еәҸеҲ—еҢ–еҸӮиҖғиҝҷйҮҢ https://spark.apache.org/docs/1.3.1/tuning.htmlеҸҰеӨ–жҺЁиҚҗдҪ еҚҮзә§еҲ°spark 1.3д»ҘдёҠзүҲжң¬пјҢз”Ёdataframeд»ЈжӣҝRDDпјҢж №жҚ®benchmarkпјҢdataframeеҸҜд»ҘеёҰжқҘеҫҲеӨ§зҡ„жҖ§иғҪжҸҗеҚҮпјҲеӣ дёәsparkзҡ„DFдјҳеҢ–еҷЁеҸҜд»ҘеҲ©з”Ёdata sourceзҡ„SchemaеҜ№execution planзҡ„дјҳеҢ–пјҢеӨ§еӨ§еҮҸе°‘I/OйңҖжұӮпјүгҖӮеҸӮиҖғиҝҷйҮҢ http://www.slideshare.net/databricks/introducing-dataframes-in-spark-for-large-scale-data-scienceгҖӮ
в– зҪ‘еҸӢ
з”Ёimpalaеҗ§
в– зҪ‘еҸӢ
еҜ№дәҺеҚғдёҮзә§еҲ«зҡ„第дәҢзұ»жҹҘиҜўпјҢspark sql 20-50sзҡ„response timeж„ҹи§үжҜ”иҫғжӯЈеёёе•ҠгҖӮиҮідәҺи®ёеӨҡ第дәҢзұ»жҹҘиҜўеҜјиҮҙзі»з»ҹеҸҳж…ўзҡ„й—®йўҳпјҡпјҲ1пјү еҰӮжһңжҳҜcpu瓶йўҲпјҢеҸҜд»ҘйҖҡиҝҮеўһеҠ # nodesпјҢеҗҢж—¶дёәзӣёеә”spark appй…ҚзҪ®жӣҙеӨҡexecutorsпјҢд»ҘеҸҠеўһеҠ жҜҸдёӘexecutorзҡ„coreж•°йҮҸпјӣ пјҲ2пјү еҰӮжһң瓶йўҲеңЁI/O, жңҖеҘҪдёҠSSDпјӣ ж„ҹи§үиҝҳеҸҜд»Ҙдёәspark й…ҚзҪ®Tachyonпјӣ жҲ–иҖ…еҰӮжһңж•°жҚ®жҳҜйқҷжҖҒзҡ„пјҢе®Ңе…ЁеҸҜд»ҘзӣҙжҺҘcache table.
жҺЁиҚҗйҳ…иҜ»







![[жҷЁиҙўз»Ҹ]дёӨеӨ§дҝЎеҸ·жҡ—зӨәжӢҗзӮ№е°Ҷиҝ‘пјҢеҺҶеҸІжҖ§еҲәжҝҖеҰӮдҪ•еҪұе“ҚAиӮЎиө°еҠҝпјҹ](https://imgcdn.toutiaoyule.com/20200405/20200405142630880907a_t.jpeg)









- |еҫҗе·һеёӮеҮәеҸ°гҖҠе…ідәҺдјҳеҢ–еҲӣж–°еҲӣдёҡз”ҹжҖҒзі»з»ҹ жҸҗеҚҮеҢәеҹҹ科жҠҖеҲӣж–°жҙ»еҠӣзҡ„е®һж–Ҫж„Ҹи§ҒгҖӢеҸҠе®һж–Ҫз»ҶеҲҷ
- жұҪиҪҰ|еӨҡйЎ№еҠҹиғҪиҝӣиЎҢдјҳеҢ– еҗүеҲ©жҳҹз‘һжҺЁеҮә第дәҢж¬ЎFOTAеҚҮзә§
- иҗҘй”ҖеһӢеӨ–иҙёзҪ‘з«ҷз”Ёе“Әз§Қе»әз«ҷзЁӢеәҸе’ҢиҜӯиЁҖжҜ”иҫғеҘҪе‘ўдё»иҰҒжҳҜйҖӮеҗҲдјҳеҢ–пјҢеҸҜжү©еұ•е…је®№жҖ§пјҢе®үе…ЁжҖ§пјҢеҗҺжңҹзҪ‘з«ҷжү©еұ•еҚҮзә§
- иҪҰеҪұиҒҡеҠӣ|е…Ёж–°йўҶе…Ӣ01жӯЈејҸдёҠеёӮпјҢ17.98дёҮе…ғиө·пјҢеҶ…йҘ°дјҳеҢ–еӨ§еҠЁеҠӣжҳҜдә®зӮ№
- иҗҘе•ҶзҺҜеўғ|вҖңж”ҫз®ЎжңҚвҖқж”№йқ©иө°еҗ‘зәөж·ұ ж— й”Ў3.0зүҲиҗҘе•ҶзҺҜеўғдјҳеҢ–жҸҗжЎЈиҝҺвҖңеӣҪиҖғвҖқ
- и¶ЈеӨҙжқЎ|еҶ…йҘ°зІҫиҮҙж—¶е°ҡ еӨ–и§ӮдјҳеҢ–еҚҮзә§ Jeepж–°ж¬ҫжҢҮеҚ—иҖ…жӯЈејҸдёӢзәҝ
- ModelзЎ®е®ҡд№ӢеҗҺпјҢеңЁTrainе’ҢDeployйҳ¶ж®өпјҢ Caffeжңүе“Әдәӣең°ж–№еҸҜд»ҘиҝӣдёҖжӯҘдјҳеҢ–д»ҘжҸҗй«ҳйҖҹеәҰ
- еҸҢйҮҚforеҫӘзҺҜжҖҺж ·дјҳеҢ–ж•ҲзҺҮ
- еҫ®е•Ҷе’ӢеҒҡжҺЁе№ҝ
- |гҖҠжұҹиӢҸзңҒдјҳеҢ–иҗҘе•ҶзҺҜеўғжқЎдҫӢгҖӢжқҘдәҶ