随着人工智能技术的发展与应用,版权成为这个领域非常重要的问题 。它和现在的数据,包括算力、深度学习或者深度伪造等很多问题,之间存在着非常直接密切的关联 。
近日,中国版权协会远集坊就“人工智能生成内容版权问题”进行研讨,邀请了司法界、科技界以及数字内容产业的众位嘉宾做分享 。

文章插图
数字时代的底层逻辑究竟是什么?
人类逐渐感知到数字时代带给社会生活、社会关系生产方式、生活方式的冲击,数字时代的法律变革是人类历史上的第二次根本性的变革 。
数字时代的底层逻辑究竟是什么?中国法学会副会长甘藏春认为,主要有由传统法治的二元结构转向三维结构,有虚有实、虚实同构的数字社会关系形成,以及数字人、数据权利等新的法律基础概念等几个特点 。
在数字时代,人除了自然人的属性以外,还有一个属性叫数字人,同样一个生物人可能有多重的数字身份发生着各种社会关系 。人类无法找到纯粹的物理时空和生物行为,数字化的元素、数字化的场景、数字化的表达等将成为未来社会一个基本的色调 。整个法律的底层逻辑已经发生了变化,人们需要研究与应对这些底层基本逻辑 。

文章插图
数字法治带来的是整个法律制度的变革 。在版权保护领域、知识产权领域、反垄断领域都要利益平衡 。在数字时代,成为透明人的人类将面临人权将如何保护 。
如何界定与保护数字化作品的版权?
对外经济贸易大学法学院教授卢海君认为在探讨数据挖掘的过程中,怎样去解决版权授权付费的问题,并不是任何东西都是可版权的,其中包括很多数字化作品 。
ChatGPT 用的是全网抓取的数据,那么这些数据当中存在有版权保护的作品,和没有版权保护的作品 。如果都需要通过版权这个路径来解决,就会存在很多的坎坷 。
GPT 所生成的内容,它的创作者是人吗?有意识吗?有思想吗?有感情吗?创作出来的东西是不是思想情感的外在表现?现行著作权法的回答仅是这个东西可能还不能够完全的嵌入到著作权法当中,可以在正确认知数据二元性基础上来寻求人工智能数据挖掘问题的解决方案 。

文章插图
数据具有二元性,它之上可能有个人信息、公共利益、版权保护的作品、科学的数据、商业机密等在内,都可以受到一定程度的保护 。比如说专利权、商业秘密权还有版权的保护,但是它跟数据本身之间有区别,数据是它的载体 。
从数据的二元性本身的认识出发,解决人工智能数据挖掘当中的问题,可能是更加可行的一个方案 。从作品的版权保护的角度来去衡量这个问题很难解决,包括很多数字化作品是没有版权保护,而不是在于说数据上承载的这个作品有没有版权 。
卢海君教授强调人工智能产业发展是大势所趋,不应为人工智能产业的发展设置太多的障碍,在人工智能数据挖掘的问题上,应关注数据本身,而不是数据上承载的内容,企业可根据数据的价值付费,如果想有更优质的数据,开发者可以购买各种数据包,以开发出更具有竞争力的人工智能产品 。他同时建议权利人和产业界加强对技术保护措施的运用 。
大模型推动下的数智化场景应用
澜舟科技创始人兼CEO、中国计算机学会副理事长周明认为,以ChatGPT为标志的大模型产品,代表着语言理解、多轮对话、问题求解进入了一个可实用的时代,有效解决了自然语言处理中任务碎片化的问题,大幅度提高研发效率,标志着自然语言处理进入工业化实施阶段 。
但目前生成式人工智能产品在专业领域的落地使用并不是简单的事,在它的构想中,需要进行三个层次大模型——通用大模型、行业大模型、任务大模型的训练 。生成式人工智能产品才有可能逐渐从通用走向专用,大幅度提升个人和企业的工作效率 。
数传集团CEO施其明结合人工智能在数传集团发展中的一些经验和做法,谈了他对生成式人工智能版权价值的看法 。
AIGC 在图书的服务领域运用的场景还是非常非常多的 。在各类的内容生成,用户之间的交互、机器人和人之间的交互当中,很多读者在通过智能化服务之后,会产生的后续的付费、阅读的满足感、阅读的延展性阅读,这其中的 90%都是AIGC 的机器人在与读者做互相的交互 。
推荐阅读



![[紫米]紫米创始人张峰兼任小米笔记本总经理](http://ttbs.guangsuss.com/image/29003ccae4701a03cbf81719eac8ab51)





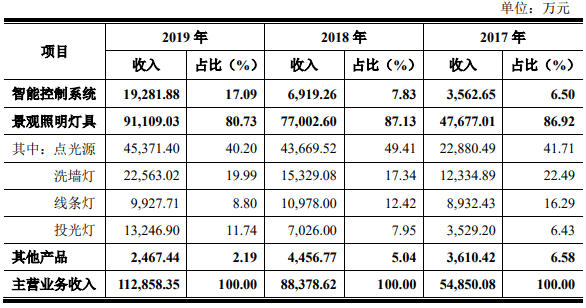




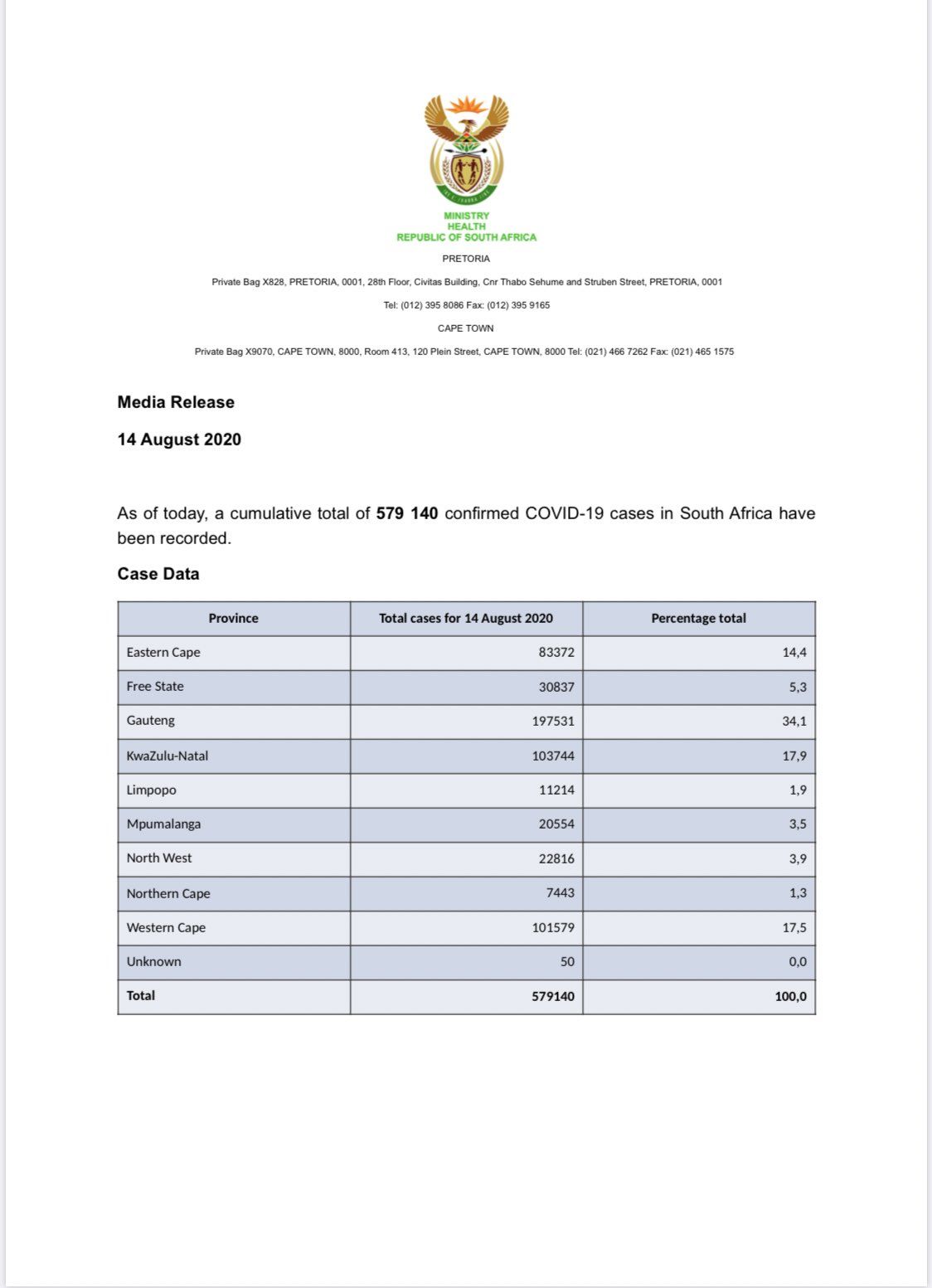

![[赵忠祥]哈文、董浩、刘晓庆、杨澜等发文悼念赵忠祥,1月20日在](http://res.cjrbapp.cjn.cn/a/10001/202001/4cd4e60c0a15815d038b6f52cd48e47e.jpeg)

- AI抢不走人类“饭碗”?爱彼迎掌门人:AI有望催生数百万家创企
- 程序员越“老”就越看不上 AI 辅助编程工具?Stack Overflow 2023 开发者调查 AI 特别报告
- AI和大数据是一对 “孪生兄弟”
- 2022十大网络歌曲排行榜
- 2023年劳动法:在这“3种情况”下让员工离职,可要公司赔钱给你
- “我23岁,包里装满了纸尿裤”: “新型毒品”正在榨干中国女孩!
- 《长风渡》告诉我们,当“丫鬟”太惊艳时,女主可以去打酱油了
- 佟大为吃水煮菜显老引争议,我看到一种“病态现象”在娱乐圈蔓延
- 网红还原古代妆造,网友:原来“老祖宗”的审美是这样的
- 袁弘晒父亲节礼物,调侃可镇宅,为报复儿子,晒“抠屁股”照