史上最全Python反爬虫方案汇总( 二 )
1. 图片验证码
- 复杂型
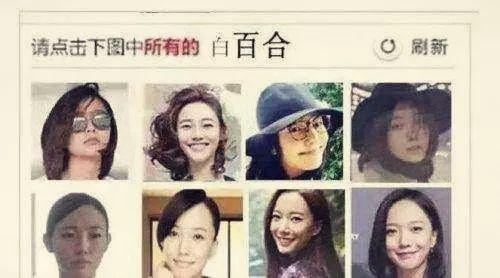 文章插图
文章插图打码平台雇佣了人力 , 专门帮人识别验证码 。 识别完把结果传回去 。 总共的过程用不了几秒时间 。 这样的打码平台还有记忆功能 。 图片被识别为“锅铲”之后 , 那么下次这张图片再出现的时候 , 系统就直接判断它是“锅铲” 。 时间一长 , 图片验证码服务器里的图片就被标记完了 , 机器就能自动识别了 。
- 简单型
 文章插图
文章插图 文章插图
文章插图上面两个不用处理直接可以用OCR识别技术(利用python第三方库--tesserocr)来识别 。
 文章插图
文章插图背景比较糊
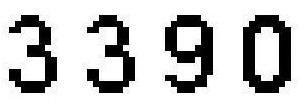 文章插图
文章插图清晰可见
经过灰度变换和二值化后,由模糊的验证码背景变成清晰可见的验证码 。
 文章插图
文章插图容易迷惑人的图片验证码
对于在这种验证码,语言一般自带图形库,添加上扭曲就成了这个样子,我们可以利用9万张图片进行训练,完成类似人的精准度,到达识别验证码的效果
2. 短信验证码用Webbrowser技术 , 模拟用户打开短信的行为,最终获取短信验证码 。
3. 计算题图片验证码
 文章插图
文章插图把所有可能出现的汉字都人工取出来 , 保存为黑白图片,把验证码按照字体颜色二值化 , 去除噪点,然后将所有图片依次与之进行像素对比,计算出相似值,找到最像的那张图片
4. 滑动验证码
 文章插图
文章插图对于滑动验证码
我们可以利用图片的像素作为线索,确定好基本属性值,查看位置的差值,对于差值超过基本属性值,我们就可以确定图片的大概位置 。
5. 图案验证码对于这种每次拖动的顺序不一样,结果就不一样,我们怎么做来识别呢?
- 利用机器学习所有的拖动顺序,利用1万张图片进行训练,完成类似人的操作,最终将其识别
- 利用selenium技术来模拟人的拖动顺序,穷尽所有拖动方式,这样达到是别的效果
 文章插图
文章插图我们不妨分析下:对于汉字而言,有中华五千年庞大的文字库,加上文字的不同字体、文字的扭曲和噪点,难度更大了 。
方法:首先点击前两个倒立的文字,可确定7个文字的坐标 ,验证码中7个汉字的位置是确定的 , 只需要提前确认每个字所在的坐标并将其放入列表中 , 然后人工确定倒立文字的文字序号 , 将列表中序号对应的坐标即可实现成功登录 。
爬虫方法:接入第三方验证码平台 , 实时破解网站的验证码 。
缺点:影响正常的用户体验操作 , 验证码越复杂 , 网站体验感越差 。
实现难度:★★通过robots.txt来限制爬虫robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件 , 它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛) , 此网站中的哪些内容是不应被搜索引擎的漫游器获取的 , 哪些是可以被漫游器获取的 。 因为一些系统中的URL是大小写敏感的 , 所以robots.txt的文件名应统一为小写 。 robots.txt应放置于网站的根目录下 。 如果想单独定义搜索引擎的漫游器访问子目录时的行为 , 那么可以将自定的设置合并到根目录下的robots.txt , 或者使用robots元数据(Metadata , 又称元数据) 。
推荐阅读















- 计算机专业大一下学期,该选择学习Java还是Python
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 2021年Java和Python的应用趋势会有什么变化?
- 非计算机专业的本科生,想利用寒假学习Python,该怎么入手
- 用Python制作图片验证码,这三行代码完事儿
- 史上最短命Windows系统!盖茨研发 都是差评
- 历时 1 个月,做了 10 个 Python 可视化动图,用心且精美...
- 为何在人工智能研发领域Python应用比较多
- 对于非计算机专业的同学来说,该选择学习Python还是C