史上最全Python反爬虫方案汇总( 三 )
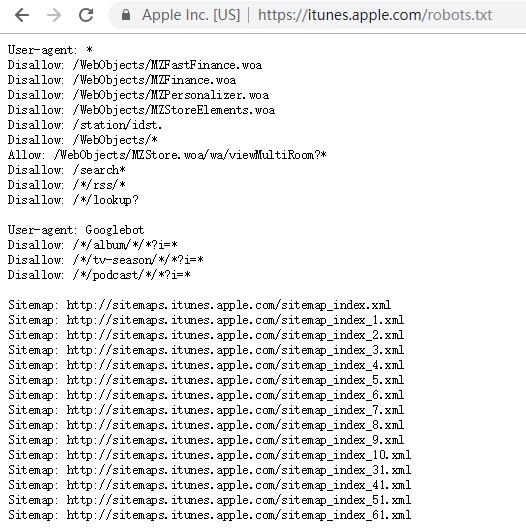
robots.txt协议并不是一个规范 , 而只是约定俗成的 , 所以并不能保证网站的隐私 。 注意robots.txt是用字符串比较来确定是否获取URL , 所以目录末尾有与没有斜杠“/”表示的是不同的URL 。 robots.txt允许使用类似"Disallow: *.gif"这样的通配符 。
itunes的robots.txt
 文章插图
文章插图
缺点:只是一个君子协议 , 对于良好的爬虫比如搜索引擎有效果 , 对于有目的性的爬虫不起作用
爬虫方法:如果使用scrapy框架 , 只需将settings文件里的ROBOTSTXT_OBEY 设置值为 False
实现难度:★数据动态加载python的requests库只能爬取静态页面 , 爬取不了动态加载的页面 。 使用JS加载数据方式 , 能提高爬虫门槛 。
爬虫方法:
- 抓包获取数据url
示例:
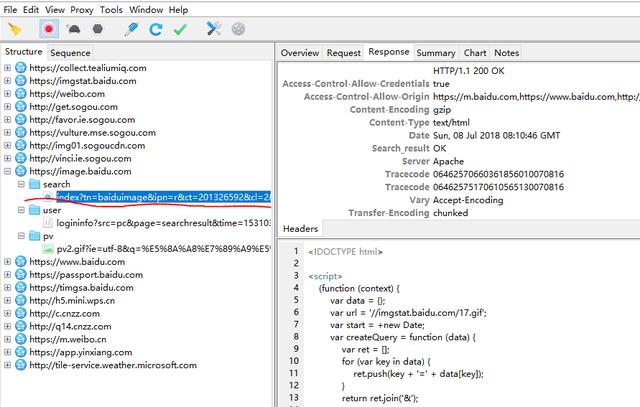
- 看这部分的包 。 可以看到 , 这部分包里面 , search下面的那个 url和我们访问的地址完全是一样的 , 但是它的response却包含了js代码 。
 文章插图
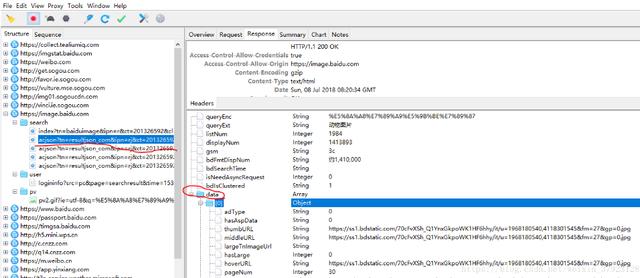
文章插图2. 当在动物图片首页往下滑动页面 , 想看到更多的时候 , 更多的包出现了 。 从图片可以看到 , 下滑页面后得到的是一连串json数据 。 在data里面 , 可以看到thumbURL等字样 。 它的值是一个url 。 这个就是图片的链接 。
 文章插图
文章插图3. 打开一个浏览器页面 , 访问thumbURL=",4118301545&fm=27&gp=0.jpg" 发现搜索结果里的图片 。
4. 根据前面的分析 , 就可以知道 , 请求
URL="/search/acjsontn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%8A%A8%E7%89%A9%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf8&oe=utf8&adpicid=&st=-1&z=&ic=0&word=%E5%8A%A8%E7%89%A9%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=30&rn=30&gsm=1e&1531038037275=" , 用浏览器访问这个链接确定他是公开的 。
5. 最后就可以寻找URL的规律 , 对URL进行构造便可获取所有照片 。
- 使用selenium
缺点:如果数据API没做加密处理 , 容易曝光接口 , 让爬虫用户更容易获取数据 。
实现难度:★数据加密-使用加密算法
- 前端加密
- 服务器端加密
爬虫方法:JS加密破解方式 , 就是要找到JS的加密代码 , 然后使用第三方库js2py在Python中运行JS代码 , 从而得到相应的编码 。
缺点:加密算法明文写在JS里 , 爬虫用户还是可以分析出来 。
实现难度:★★★数据加密-使用字体文件映射服务器端根据字体映射文件先将客户端查询的数据进行变换再传回前端 , 前端根据字体文件进行逆向解密 。
映射方式可以是数字乱序显示 , 这样爬虫可以爬取数据 , 但是数据是错误的 。
破解方式:
其实 , 如果能看懂JS代码 , 这样的方式还是很容易破解的 , 所以需要做以下几个操作来加大破解难度 。
推荐阅读















- 计算机专业大一下学期,该选择学习Java还是Python
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 2021年Java和Python的应用趋势会有什么变化?
- 非计算机专业的本科生,想利用寒假学习Python,该怎么入手
- 用Python制作图片验证码,这三行代码完事儿
- 史上最短命Windows系统!盖茨研发 都是差评
- 历时 1 个月,做了 10 个 Python 可视化动图,用心且精美...
- 为何在人工智能研发领域Python应用比较多
- 对于非计算机专业的同学来说,该选择学习Python还是C