зҫҺеӣўеӨ–еҚ–е®һж—¶ж•°д»“е»әи®ҫе®һи·ө( дәҢ )
еҰӮдёҠеӣҫжүҖзӨә пјҢ жӢҝеҲ°ж•°жҚ®жәҗеҗҺ пјҢ дјҡз»ҸиҝҮж•°жҚ®жё…жҙ— пјҢ жү©з»ҙ пјҢ йҖҡиҝҮStormжҲ–FlinkиҝӣиЎҢдёҡеҠЎйҖ»иҫ‘еӨ„зҗҶ пјҢ жңҖеҗҺзӣҙжҺҘиҝӣиЎҢдёҡеҠЎиҫ“еҮә гҖӮ жҠҠиҝҷдёӘзҺҜиҠӮжӢҶејҖжқҘзңӢ пјҢ ж•°жҚ®жәҗз«ҜдјҡйҮҚеӨҚеј•з”ЁзӣёеҗҢзҡ„ж•°жҚ®жәҗ пјҢ еҗҺйқўиҝӣиЎҢжё…жҙ—гҖҒиҝҮж»ӨгҖҒжү©з»ҙзӯүж“ҚдҪң пјҢ йғҪиҰҒйҮҚеӨҚеҒҡдёҖйҒҚ пјҢ е”ҜдёҖдёҚеҗҢзҡ„жҳҜдёҡеҠЎзҡ„д»Јз ҒйҖ»иҫ‘жҳҜдёҚдёҖж ·зҡ„ пјҢ еҰӮжһңдёҡеҠЎиҫғе°‘ пјҢ иҝҷз§ҚжЁЎејҸиҝҳеҸҜд»ҘжҺҘеҸ— пјҢ дҪҶеҪ“еҗҺз»ӯдёҡеҠЎйҮҸдёҠеҺ»еҗҺ пјҢ дјҡеҮәзҺ°и°ҒејҖеҸ‘и°Ғиҝҗз»ҙзҡ„жғ…еҶө пјҢ з»ҙжҠӨе·ҘдҪңйҮҸдјҡи¶ҠжқҘи¶ҠеӨ§ пјҢ дҪңдёҡж— жі•еҪўжҲҗз»ҹдёҖз®ЎзҗҶ гҖӮ иҖҢдё”жүҖжңүдәәйғҪеңЁз”іиҜ·иө„жәҗ пјҢ еҜјиҮҙиө„жәҗжҲҗжң¬жҖҘйҖҹиҶЁиғҖ пјҢ иө„жәҗдёҚиғҪйӣҶзәҰжңүж•ҲеҲ©з”Ё пјҢ еӣ жӯӨиҰҒжҖқиҖғеҰӮдҪ•д»Һж•ҙдҪ“жқҘиҝӣиЎҢе®һж—¶ж•°жҚ®зҡ„е»әи®ҫ гҖӮ
04
ж•°жҚ®зү№зӮ№дёҺеә”з”ЁеңәжҷҜ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
йӮЈд№ҲеҰӮдҪ•жқҘжһ„е»әе®һж—¶ж•°д»“е‘ўпјҹ
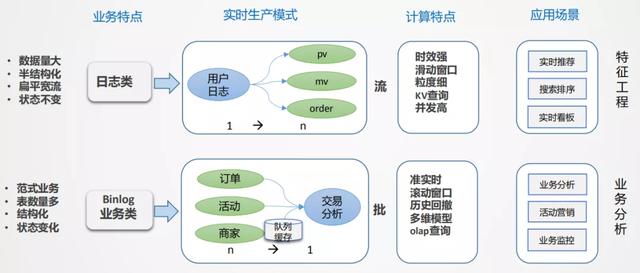
йҰ–е…ҲиҰҒиҝӣиЎҢжӢҶи§Ј пјҢ жңүе“Әдәӣж•°жҚ® пјҢ жңүе“ӘдәӣеңәжҷҜ пјҢ иҝҷдәӣеңәжҷҜжңүе“Әдәӣе…ұеҗҢзү№зӮ№ пјҢ еҜ№дәҺеӨ–еҚ–еңәжҷҜжқҘиҜҙдёҖе…ұжңүдёӨеӨ§зұ» пјҢ ж—Ҙеҝ—зұ»е’ҢдёҡеҠЎзұ» гҖӮ
- ж—Ҙеҝ—зұ»пјҡж•°жҚ®йҮҸзү№еҲ«еӨ§ пјҢ еҚҠз»“жһ„еҢ– пјҢ еөҢеҘ—жҜ”иҫғж·ұ гҖӮ ж—Ҙеҝ—зұ»зҡ„ж•°жҚ®жңүдёӘеҫҲеӨ§зҡ„зү№зӮ№ пјҢ ж—Ҙеҝ—жөҒдёҖж—ҰеҪўжҲҗжҳҜдёҚдјҡеҸҳзҡ„ пјҢ йҖҡиҝҮеҹӢзӮ№зҡ„ж–№ејҸ收йӣҶе№іеҸ°жүҖжңүзҡ„ж—Ҙеҝ— пјҢ з»ҹдёҖиҝӣиЎҢйҮҮйӣҶеҲҶеҸ‘ пјҢ е°ұеғҸдёҖйў—ж ‘ пјҢ ж ‘ж №йқһеёёеӨ§ пјҢ жҺЁеҲ°еүҚз«Ҝеә”з”Ёзҡ„ж—¶еҖҷ пјҢ зӣёеҪ“дәҺд»Һж ‘ж №еҲ°ж ‘жһқеҲҶеҸүзҡ„иҝҮзЁӢпјҲд»Һ1еҲ°nзҡ„еҲҶи§ЈиҝҮзЁӢпјү пјҢ еҰӮжһңжүҖжңүзҡ„дёҡеҠЎйғҪд»Һж №дёҠжүҫж•°жҚ® пјҢ зңӢиө·жқҘи·Ҝеҫ„жңҖзҹӯ пјҢ дҪҶеҢ…иўұеӨӘйҮҚ пјҢ ж•°жҚ®жЈҖзҙўж•ҲзҺҮдҪҺ гҖӮ ж—Ҙеҝ—зұ»ж•°жҚ®дёҖиҲ¬з”ЁдәҺз”ҹдә§зӣ‘жҺ§е’Ңз”ЁжҲ·иЎҢдёәеҲҶжһҗ пјҢ ж—¶ж•ҲжҖ§иҰҒжұӮжҜ”иҫғй«ҳ пјҢ ж—¶й—ҙзӘ—еҸЈдёҖиҲ¬жҳҜ5minжҲ–10minжҲ–жҲӘжӯўеҲ°еҪ“еүҚзҡ„дёҖдёӘзҠ¶жҖҒ пјҢ дё»иҰҒзҡ„еә”з”ЁжҳҜе®һж—¶еӨ§еұҸе’Ңе®һж—¶зү№еҫҒ пјҢ дҫӢеҰӮз”ЁжҲ·жҜҸдёҖж¬ЎзӮ№еҮ»иЎҢдёәйғҪиғҪеӨҹз«ӢеҲ»ж„ҹзҹҘеҲ°зӯүйңҖжұӮ гҖӮ
- дёҡеҠЎзұ»пјҡдё»иҰҒжҳҜдёҡеҠЎдәӨжҳ“ж•°жҚ® пјҢ дёҡеҠЎзі»з»ҹдёҖиҲ¬жҳҜиҮӘжҲҗдҪ“зі»зҡ„ пјҢ д»ҘBinlogж—Ҙеҝ—зҡ„еҪўејҸеҫҖдёӢеҲҶеҸ‘ пјҢ дёҡеҠЎзі»з»ҹйғҪжҳҜдәӢеҠЎеһӢзҡ„ пјҢ дё»иҰҒйҮҮз”ЁиҢғејҸе»әжЁЎж–№ејҸ пјҢ зү№зӮ№жҳҜз»“жһ„еҢ–зҡ„ пјҢ дё»дҪ“йқһеёёжё…жҷ° пјҢ дҪҶж•°жҚ®иЎЁиҫғеӨҡ пјҢ йңҖиҰҒеӨҡиЎЁе…іиҒ”жүҚиғҪиЎЁиҫҫе®Ңж•ҙдёҡеҠЎ пјҢ еӣ жӯӨжҳҜдёҖдёӘnеҲ°1зҡ„йӣҶжҲҗеҠ е·ҘиҝҮзЁӢ гҖӮ
- дёҡеҠЎзҡ„еӨҡзҠ¶жҖҒжҖ§пјҡдёҡеҠЎиҝҮзЁӢд»ҺејҖе§ӢеҲ°з»“жқҹжҳҜдёҚж–ӯеҸҳеҢ–зҡ„ пјҢ жҜ”еҰӮд»ҺдёӢеҚ•->ж”Ҝд»ҳ->й…ҚйҖҒ пјҢ дёҡеҠЎеә“жҳҜеңЁеҺҹе§ӢеҹәзЎҖдёҠиҝӣиЎҢеҸҳжӣҙзҡ„ пјҢ binlogдјҡдә§з”ҹеҫҲеӨҡеҸҳеҢ–зҡ„ж—Ҙеҝ— гҖӮ иҖҢдёҡеҠЎеҲҶжһҗжӣҙеҠ е…іжіЁжңҖз»ҲзҠ¶жҖҒ пјҢ з”ұжӯӨдә§з”ҹж•°жҚ®еӣһж’Өи®Ўз®—зҡ„й—®йўҳ пјҢ дҫӢеҰӮ10зӮ№дёӢеҚ• пјҢ 13зӮ№еҸ–ж¶Ҳ пјҢ дҪҶеёҢжңӣеңЁ10зӮ№еҮҸжҺүеҸ–ж¶ҲеҚ• гҖӮ
- дёҡеҠЎйӣҶжҲҗпјҡдёҡеҠЎеҲҶжһҗж•°жҚ®дёҖиҲ¬ж— жі•йҖҡиҝҮеҚ•дёҖдё»дҪ“иЎЁиҫҫ пјҢ еҫҖеҫҖжҳҜеҫҲеӨҡиЎЁиҝӣиЎҢе…іиҒ” пјҢ жүҚиғҪеҫ—еҲ°жғіиҰҒзҡ„дҝЎжҒҜ пјҢ еңЁе®һж—¶жөҒдёӯиҝӣиЎҢж•°жҚ®зҡ„еҗҲжөҒеҜ№йҪҗ пјҢ еҫҖеҫҖйңҖиҰҒиҫғеӨ§зҡ„зј“еӯҳеӨ„зҗҶдё”еӨҚжқӮ гҖӮ
- еҲҶжһҗжҳҜжү№йҮҸзҡ„ пјҢ еӨ„зҗҶиҝҮзЁӢжҳҜжөҒејҸзҡ„пјҡеҜ№еҚ•дёҖж•°жҚ® пјҢ ж— жі•еҪўжҲҗеҲҶжһҗ пјҢ еӣ жӯӨеҲҶжһҗеҜ№иұЎдёҖе®ҡжҳҜжү№йҮҸзҡ„ пјҢ иҖҢж•°жҚ®еҠ е·ҘжҳҜйҖҗжқЎзҡ„ гҖӮ
05
е®һж—¶ж•°д»“жһ¶жһ„и®ҫи®Ў
1. е®һж—¶жһ¶жһ„пјҡжөҒжү№з»“еҗҲзҡ„жҺўзҙў
 ж–Үз« жҸ’еӣҫ
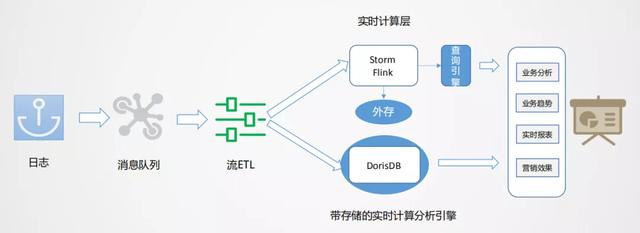
ж–Үз« жҸ’еӣҫеҹәдәҺд»ҘдёҠй—®йўҳ пјҢ жҲ‘们жңүиҮӘе·ұзҡ„жҖқиҖғ гҖӮ йҖҡиҝҮжөҒжү№з»“еҗҲзҡ„ж–№ејҸжқҘеә”еҜ№дёҚеҗҢзҡ„дёҡеҠЎеңәжҷҜ гҖӮ
еҰӮдёҠеӣҫжүҖзӨә пјҢ ж•°жҚ®д»Һж—Ҙеҝ—з»ҹдёҖйҮҮйӣҶеҲ°ж¶ҲжҒҜйҳҹеҲ— пјҢ еҶҚеҲ°ж•°жҚ®жөҒзҡ„ETLиҝҮзЁӢ пјҢ дҪңдёәеҹәзЎҖж•°жҚ®жөҒзҡ„е»әи®ҫжҳҜз»ҹдёҖзҡ„ гҖӮ д№ӢеҗҺеҜ№дәҺж—Ҙеҝ—зұ»е®һж—¶зү№еҫҒ пјҢ е®һж—¶еӨ§еұҸзұ»еә”з”Ёиө°е®һж—¶жөҒи®Ўз®— гҖӮ еҜ№дәҺBinlogзұ»дёҡеҠЎеҲҶжһҗиө°е®һж—¶OLAPжү№еӨ„зҗҶ гҖӮ
жөҒејҸеӨ„зҗҶеҲҶжһҗдёҡеҠЎзҡ„з—ӣзӮ№пјҹеҜ№дәҺиҢғејҸдёҡеҠЎ пјҢ Stormе’ҢFlinkйғҪйңҖиҰҒеҫҲеӨ§зҡ„еӨ–еӯҳ пјҢ жқҘе®һзҺ°ж•°жҚ®жөҒд№Ӣй—ҙзҡ„дёҡеҠЎеҜ№йҪҗ пјҢ йңҖиҰҒеӨ§йҮҸзҡ„и®Ўз®—иө„жәҗ гҖӮ дё”з”ұдәҺеӨ–еӯҳзҡ„йҷҗеҲ¶ пјҢ еҝ…йЎ»иҝӣиЎҢзӘ—еҸЈзҡ„йҷҗе®ҡзӯ–з•Ҙ пјҢ жңҖз»ҲеҸҜиғҪж”ҫејғдёҖдәӣж•°жҚ® гҖӮ и®Ўз®—д№ӢеҗҺ пјҢ дёҖиҲ¬жҳҜеӯҳеҲ°RedisйҮҢеҒҡжҹҘиҜўж”Ҝж’‘ пјҢ дё”KVеӯҳеӮЁеңЁеә”еҜ№еҲҶжһҗзұ»жҹҘиҜўеңәжҷҜдёӯд№ҹжңүиҫғеӨҡеұҖйҷҗ гҖӮ
жҺЁиҚҗйҳ…иҜ»













- жһң然пјҢзҫҺеӣўеҸҲеҮәдәӢе„ҝдәҶвҖҰвҖҰ
- дёҖжіўжңӘе№ідёҖжіўеҸҲиө·пјҢжҲ‘д№°дёӘиҸңе°ұж¬ дәҶдёҖ笔иҙ·ж¬ҫпјҹзҫҺеӣўиҝҷж¬ЎеҪ»еә•жІЎиҜқиҜҙ
- ж¶Ҳиҙ№иҖ…жҠҘе‘Ҡ | зҫҺеӣўе……з”өе®қз”өйҮҸдёҚи¶ід№ҹжүЈиҙ№пјҢжҳҜиҙЁйҮҸй—®йўҳиҝҳжҳҜзі»з»ҹзјәйҷ·пјҹ
- зҫҺеӣўиҮҙжӯүпјҡеҝғжҖҖеҜ№еҺҶеҸІзҡ„敬з•Ҹ жҳҜеҒҡеҘҪдә§е“Ғзҡ„еүҚжҸҗ
- зҺӢе…ҙиғҢеҗҺжңҖйҮҚиҰҒзҡ„еҘідәәпјҡеҢ—еӨ§жҜ•дёҡпјҢеҰӮд»ҠжҳҜзҫҺеӣўвҖң第дёүеҸ·вҖқдәәзү©
- зәӘеҝөйҰҶ|зҫҺеӣўе°ұвҖңж Үзӯҫй—ЁвҖқйҒ“жӯүпјҢ敬з•ҸеҺҶеҸІжҳҜеҒҡдә§е“Ғзҡ„еүҚжҸҗ
- ж•°жҚ®жқҖзҶҹгҖҒеұҸи”ҪеҜ№жүӢпјҒйў‘йў‘вҖңжғ№дәӢвҖқзҡ„зҫҺеӣўйҒӯеҸҚеһ„ж–ӯиҜүи®ј
- жҜ«ж— 敬з•Ҹд№ӢеҝғпјҒеҚ—дә¬еӨ§еұ жқҖйҒҮйҡҫеҗҢиғһзәӘеҝөйҰҶиў«ж Ү"дј‘й—ІеЁұд№җеҘҪеҺ»еӨ„"пјҢзҫҺеӣўпјҡз«ӢеҚіж”№жӯЈ
- иҝҷдәӣең°ж–№з«ҹж ҮжіЁвҖңе®ӨеҶ…зҺ©д№җвҖқгҖҒвҖңдј‘й—ІеЁұд№җзҡ„еҘҪеҺ»еӨ„вҖқпјҹзҫҺеӣўзҙ§жҖҘиҮҙжӯү
- зҫҺеӣўе°ұд№ұиҙҙж ҮзӯҫйҒ“жӯүпјҢ敬з•ҸеҺҶеҸІжҳҜеҒҡдә§е“Ғзҡ„еүҚжҸҗ