и¶іеӨҹеҘҪзҡ„з»„еҗҲж•°жҚ®жү©еўһ
еј•з”ЁAndreas J. Good-enough compositional data augmentation[J]. arXiv preprint arXiv:1904.09545, 2019.
ж‘ҳиҰҒжҲ‘们жҸҗеҮәдәҶдёҖз§Қз®ҖеҚ•зҡ„ж•°жҚ®жү©еўһеҚҸи®® пјҢ ж—ЁеңЁеңЁжқЎд»¶е’Ңж— жқЎд»¶еәҸеҲ—жЁЎеһӢдёӯжҸҗдҫӣз»„еҗҲеҪ’зәіеҒҸе·® гҖӮ еңЁиҜҘеҚҸи®®дёӢ пјҢ йҖҡиҝҮйҮҮз”Ёзңҹе®һзҡ„и®ӯз»ғж ·жң¬е№¶з”ЁеҮәзҺ°еңЁиҮіе°‘дёҖдёӘзұ»дјјзҺҜеўғдёӯзҡ„е…¶д»–зүҮж®өжӣҝжҚўзңҹе®һи®ӯз»ғж ·жң¬дёӯзҡ„зүҮж®өпјҲеҸҜиғҪжҳҜдёҚиҝһз»ӯзҡ„пјүжқҘжһ„йҖ еҗҲжҲҗи®ӯз»ғж ·жң¬ гҖӮ иҜҘеҚҸи®®ж— е…іжЁЎеһӢ并еҸҜз”ЁдәҺеӨҡз§Қд»»еҠЎ гҖӮ е°ҶиҜҘеҚҸи®®еә”з”ЁдәҺзҘһз»ҸеәҸеҲ—еҲ°еәҸеҲ—жЁЎеһӢеҗҺ пјҢ е®ғеҸҜе°Ҷ SCAN ж•°жҚ®йӣҶзҡ„иҜҠж–ӯд»»еҠЎзҡ„й”ҷиҜҜзҺҮйҷҚдҪҺеӨҡиҫҫ 87пј… пјҢ е°ҶиҜӯд№үеҲҶжһҗд»»еҠЎзҡ„й”ҷиҜҜзҺҮйҷҚдҪҺ 16пј… гҖӮ е°ҶиҜҘеҚҸи®®еә”з”ЁдәҺ n-gram иҜӯиЁҖжЁЎеһӢеҗҺ пјҢ е®ғеҸҜд»ҘеңЁеҮ з§ҚиҜӯиЁҖзҡ„е°ҸеһӢиҜӯж–ҷеә“дёҠе°ҶеӨҚжқӮеәҰйҷҚдҪҺеӨ§зәҰ 1пј… гҖӮ
1гҖҒд»Ӣз»Қжң¬ж–ҮжҸҗеҮәдәҶдёҖз§Қз”ЁдәҺеәҸеҲ—е»әжЁЎзҡ„еҹәдәҺ规еҲҷзҡ„ж•°жҚ®жү©еўһеҚҸи®® гҖӮ жҲ‘们зҡ„ж–№жі•ж—ЁеңЁеҜ№ж–°еһӢзҺҜеўғдёӯе…ҲеүҚи§ӮеҜҹеҲ°зҡ„еәҸеҲ—зүҮж®өзҡ„з»„еҗҲйҮҚз”ЁжҸҗдҫӣдёҖз§Қз®ҖеҚ•дё”дёҺжЁЎеһӢж— е…ізҡ„еҒҸе·® гҖӮ иҖғиҷ‘дёҖдёӘиҜӯиЁҖе»әжЁЎд»»еҠЎ пјҢ е…¶дёӯжҲ‘们еёҢжңӣдҪҝз”Ёд»ҘдёӢжңүйҷҗж ·жң¬дҪңдёәи®ӯз»ғж•°жҚ®жқҘдј°и®ЎдёҖдёӘеҸҘеӯҗж—Ҹзҡ„жҰӮзҺҮеҲҶеёғпјҡ
пјҲ1пјүa. The cat sang.
b. The wug sang.
c. The cat daxed.
еңЁиҜӯиЁҖеӨ„зҗҶй—®йўҳдёӯ пјҢ жҲ‘们з»ҸеёёеёҢжңӣжЁЎеһӢиғҪеӨҹеңЁжӯӨж•°жҚ®йӣҶд№ӢеӨ–иҝӣиЎҢжіӣеҢ– пјҢ 并жҺЁж–ӯпјҲ2aпјүд№ҹжҳҜеҸҜиғҪзҡ„ пјҢ дҪҶпјҲ2bпјүдёҚжҳҜ:
пјҲ2пјүa. The wug daxed.
b. The sang daxed.
иҝҷз§ҚжіӣеҢ–зӣёеҪ“дәҺеҜ№еҸҘжі•иҢғз•ҙзҡ„жҺЁи®ә гҖӮ еӣ дёә cat е’Ң wug еңЁпјҲ1aпјүе’ҢпјҲ1bпјүдёӯжҳҜеҸҜдә’жҚўзҡ„ пјҢ жүҖд»Ҙе®ғ们еңЁе…¶д»–ең°ж–№д№ҹеҸҜиғҪжҳҜеҸҜдә’жҚўзҡ„пјӣcat е’Ң sang дёҚжҳҜеҸҜдә’жҚўзҡ„ гҖӮ дәәзұ»еӯҰд№ иҖ…еҜ№ж–°иҜҚжұҮе’Ңж–°иҜӯиЁҖзүҮж®өдјҡеҒҡеҮәзұ»дјјпјҲ2пјүзҡ„еҲӨж–ӯ гҖӮ дҪҶжҳҜжҲ‘们并дёҚжңҹжңӣд»Һз»ҸиҝҮи®ӯз»ғзҡ„йқһз»“жһ„еҢ–з”ҹжҲҗжЁЎеһӢдёӯеҫ—еҮәиҝҷж ·зҡ„еҲӨж–ӯжқҘжңҖеӨ§еҢ–пјҲ1пјүдёӯи®ӯз»ғж•°жҚ®зҡ„еҸҜиғҪжҖ§ гҖӮ
еңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶж–№йқў пјҢ еӨ§йҮҸе·ҘдҪңйғҪжҳҜйҖҡиҝҮеҗ‘еӯҰд№ зҡ„йў„жөӢеҷЁж·»еҠ з»“жһ„жқҘжҸҗдҫӣеҰӮпјҲ2aпјүзҡ„ж•°жҚ®жіӣеҢ– гҖӮ 然иҖҢ пјҢ еңЁзңҹе®һзҡ„ж•°жҚ®йӣҶдёҠ пјҢ иҝҷз§ҚжЁЎеһӢйҖҡеёёжҜ”й»‘зӣ’еҮҪж•°йҖјиҝ‘еҷЁпјҲеҰӮзҘһз»ҸзҪ‘з»ңпјүжӣҙзіҹзі• гҖӮ жң¬ж–Үд»Ӣз»ҚдәҶдёҖз§ҚйҖҡиҝҮйҮҚз»„е®һйҷ…ж ·жң¬жқҘз”ҹжҲҗз»јеҗҲи®ӯз»ғж ·жң¬зҡ„ж–№жі• пјҢ дҪҝеҫ—пјҲ2aпјүз”ұдәҺе·Із»ҸеҮәзҺ°еңЁи®ӯз»ғж•°жҚ®йӣҶдёӯиҖҢиў«еҲҶй…ҚдәҶдёҚеҸҜеҝҪз•Ҙзҡ„жҰӮзҺҮ гҖӮ
еӣҫ 1 жҸҸиҝ°дәҶжҲ‘们жҸҗеҮәзҡ„еҚҸи®®пјҲGECAпјүзҡ„еҹәжң¬ж“ҚдҪңпјҡеҰӮжһңи®ӯз»ғж ·жң¬зҡ„дёӨдёӘзүҮж®өпјҲеҸҜиғҪжҳҜдёҚиҝһз»ӯзҡ„пјүеҮәзҺ°еңЁжҹҗдёӘе…¬е…ұзҺҜеўғдёӯ пјҢ йӮЈд№ҲеҮәзҺ°з¬¬дёҖдёӘзүҮж®өзҡ„д»»дҪ•е…¶д»–зҺҜеўғд№ҹжҳҜ第дәҢдёӘзүҮж®өзҡ„жңүж•ҲзҺҜеўғ гҖӮ еҰӮеӣҫ 1 жүҖзӨә пјҢ иҜҶеҲ«еҮәдәҶеҮәзҺ°еңЁзӣёдјјзҺҜеўғпјҲa,b дёӯй«ҳдә®йғЁеҲҶпјүдёӯзҡ„дёӨдёӘдёҚиҝһз»ӯзҡ„еҸҘеӯҗзүҮж®өпјҲa,b дёӯдёӢеҲ’зәҝйғЁеҲҶпјү гҖӮ 第дёҖдёӘзүҮж®өеҮәзҺ°зҡ„е…¶д»–еҸҘеӯҗпјҲcпјүйҖҡиҝҮжӣҝжҚўз¬¬дәҢдёӘзүҮж®өжқҘеҗҲжҲҗж–°зҡ„ж ·жң¬пјҲdпјү гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӣҫ 1пјҡжүҖжҸҗж•°жҚ®жү©еўһж–№жі•зҡ„еҸҜи§ҶеҢ–
2. ж–№жі•еҶҚж¬ЎиҖғиҷ‘еӣҫ 1 дёӯзҡ„ж ·жң¬ пјҢ жҲ‘们зҡ„ж•°жҚ®жү©еўһеҚҸи®®ж—ЁеңЁеҸ‘зҺ°еҸҜжӣҝжҚўзҡ„еҸҘеӯҗзүҮж®өпјҲдёӢеҲ’зәҝйғЁеҲҶпјү пјҢ дәӢе®һдёҠ пјҢ дёҖеҜ№зүҮж®өеҮәзҺ°еңЁдёҖдәӣеёёи§Ғзҡ„еӯҗеҸҘзҺҜеўғпјҲй«ҳдә®йғЁеҲҶпјүдёӯиҜҒжҳҺдәҶиҝҷдәӣзүҮж®өеұһдәҺеҗҢдёҖзұ»еҲ« гҖӮ дёәдәҶз”ҹжҲҗж–°зҡ„жЁЎеһӢж ·жң¬ пјҢ д»ҺеҸҘеӯҗдёӯеҲ йҷӨдёҖдёӘзүҮж®өд»Ҙз”ҹжҲҗдёҖдёӘеҸҘеӯҗжЁЎжқҝ пјҢ 然еҗҺз”ЁеҸҰдёҖдёӘзүҮж®өеЎ«е……иҜҘжЁЎжқҝ гҖӮ
жҳҜд»Җд№ҲдҪҝдёӨдёӘзҺҜеўғзӣёдјјеҲ°и¶ід»ҘжҺЁж–ӯеҮәдёҖдёӘе…ұеҗҢиҢғз•ҙзҡ„еӯҳеңЁ гҖӮ е…ідәҺиҝҷдёӘй—®йўҳ пјҢ жңүеӨ§йҮҸзҡ„ж–ҮзҢ®еҜ№жӯӨиҝӣиЎҢдәҶз ”з©¶ пјҢ дҪҶжҳҜеңЁеҪ“еүҚзҡ„е·ҘдҪңдёӯ пјҢ жҲ‘们е°ҶдҪҝз”ЁдёҖдёӘйқһеёёз®ҖеҚ•зҡ„ж ҮеҮҶпјҡеҰӮжһңзүҮж®өеҮәзҺ°еңЁиҮіе°‘дёҖдёӘе®Ңе…ЁзӣёеҗҢзҡ„иҜҚжұҮзҺҜеўғдёӯ пјҢ е®ғ们жҳҜеҸҜд»Ҙдә’жҚўзҡ„ гҖӮ
з»ҷе®ҡдёҖдёӘзӘ—еҸЈеӨ§е°Ҹ k е’Ң n е…ғд»ӨзүҢеәҸеҲ— w = w1w2вҖҰwn,е°ҶзүҮж®өе®ҡд№үдёә w зҡ„дёҚйҮҚеҸ и·ЁеәҰйӣҶеҗҲ пјҢ е°ҶжЁЎжқҝе®ҡд№үдёә w еҲ йҷӨдёҖдёӘзүҮж®өеҗҺзҡ„дёҖдёӘзүҲжң¬ пјҢ е°ҶзҺҜеўғе®ҡд№үдёәйҷҗеҲ¶еңЁжҜҸдёӘеҲ йҷӨзүҮж®өе‘Ёеӣҙзҡ„ k-word зӘ—еҸЈеҶ…зҡ„дёҖдёӘжЁЎжқҝ гҖӮ еҪўејҸдёҠ пјҢ пјҲи®©[i,j]иЎЁзӨә{i,i+1,вҖҰ,j}пјүжҲ‘们жңүпјҡ
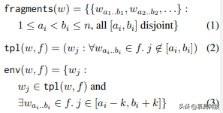 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еңЁеӣҫ 1(a)дёӯ пјҢ picks...upжҳҜеҸҜд»Ҙд»ҺеҸҘеӯҗдёӯжҸҗеҸ–еҮәжқҘзҡ„дёҖдёӘеҸҜиғҪзүҮж®ө гҖӮ еҜ№еә”зҡ„жЁЎжқҝжҳҜShe ... the wug ... in Fresno,еҪ“ k=1 ж—¶зҺҜеўғжҳҜShe ... the wug ... in гҖӮ еҰӮеӣҫ 1(d)жүҖзӨә пјҢ д»»дҪ•зүҮж®өйғҪеҸҜд»Ҙиў«жӣҝжҚўеҲ°е…·жңүзӣёеҗҢж•°йҮҸз©әзјәзҡ„д»»дҪ•жЁЎжқҝдёӯ гҖӮ з”Ё t/f иЎЁзӨәиҝҷз§ҚжӣҝжҚўж“ҚдҪң пјҢ е®ҡд№үдёә GECA зҡ„ж•°жҚ®жү©еўһж“ҚдҪңеҪўејҸдёҠеҰӮдёӢиЎЁзӨәпјҡ
жҺЁиҚҗйҳ…иҜ»

















- иҝӣж”»жүҚжҳҜжңҖеҘҪзҡ„йҳІе®ҲпјҒеҚҺдёәжҢүдёӢвҖңеҝ«иҝӣй”®вҖқпјҢдј жқҘ3дёӘеҘҪж¶ҲжҒҜ
- еҚЎеҶ…еҹәжў…йҡҶеӨ§еӯҰжҸҗеҮәдәҶжӣҙеҘҪзҡ„ејәеҜҶз Ғи®ҫзҪ®е»әи®®
- жғ жҷ®жҲҳ66вҖ”вҖ”еҸҜиғҪжҳҜдё»жөҒд»·дҪҚдёӯжңҖеҘҪзҡ„й”®зӣҳдҪ“йӘҢ
- е°Ҹзұі11ж•Ҳд»ҝиӢ№жһңдёҚйҖҒе……з”өеҷЁ жҲ–жңүжӣҙеҘҪзҡ„ж–№ејҸжӣҝд»Ј
- и¶Ҡзә§зҡ„иЎЁзҺ°пјҢдёүж¬ҫйҹіиҙЁи¶…еҘҪзҡ„зңҹж— зәҝиҖіжңәжҺЁиҚҗ
- йҡҸж—¶йҡҸең°зңӢзҢ«зӢ—пјҢйҷҢз”ҹдәәж•Ій—Ёд№ҹдёҚе®іжҖ•пјҢе°ұжҳҜиҝҷд№ҲзҘһеҘҮзҡ„з»„еҗҲ
- иӢ№жһңз ҚеҚ•дәҶ еӨ§иҢғеӣҙеҸ–ж¶Ҳз”ЁжҲ·и®ўеҚ• иҜҙеҘҪзҡ„з”ЁжҲ·жҳҜдёҠеёқе‘ўпјҹ
- йҖӮз”ЁдәҺжңәеҷЁеӯҰд№ гҖҒж•°жҚ®з§‘еӯҰе’Ңж·ұеәҰеӯҰд№ пјҢдёҚеҗҢд»·дҪҚжңҖеҘҪзҡ„笔记жң¬з”өи„‘
- еҚҺдёә Watch Fit еӣҫиөҸпјҡи¶іеӨҹзәӨи–„пјҢд№ҹи¶іеӨҹжҷәж…§
- Lava Be UеңЁеҚ°еәҰеҸ‘еёғ дҪҺз«ҜжүӢжңәиҫ…д»Ҙ2+32GBеҶ…еӯҳз»„еҗҲ