и¶іеӨҹеҘҪзҡ„з»„еҗҲж•°жҚ®жү©еўһ( дёү )
еҲҶжһҗпјҡж•°жҚ®йӣҶз»ҹи®Ў дёәдәҶжӣҙж·ұеұӮж¬ЎзҗҶи§Ј GECA зҡ„иЎҢдёә пјҢ жҲ‘们иҝӣиЎҢдәҶжңҖеҗҺдёҖз»„еҲҶжһҗ пјҢ д»ҘйҮҸеҢ–еҗҲжҲҗж•°жҚ®е’Ңдҝқз•ҷж•°жҚ®д№Ӣй—ҙзҡ„йҮҚеҸ гҖӮ жҲ‘们йҰ–е…ҲжөӢйҮҸ full example overlap пјҢ еҚіеҮәзҺ°еңЁжү©еўһи®ӯз»ғйӣҶдёӯзҡ„жөӢиҜ•ж ·жң¬зҡ„жҜ”дҫӢпјҲж №жҚ®и®ҫи®Ў пјҢ жөӢиҜ•йӣҶдёҺеҺҹе§Ӣи®ӯз»ғйӣҶд№Ӣй—ҙдёҚеӯҳеңЁйҮҚеҸ пјү гҖӮ еә”з”Ё GECA еҗҺ пјҢ иҮӘеҠЁеҗҲжҲҗadd primitiveжқЎд»¶дёӢ 5%зҡ„жөӢиҜ•ж ·жң¬е’Ңadd templateжқЎд»¶дёӢ 1%зҡ„ж ·жң¬ гҖӮ жҺҘдёӢжқҘжҲ‘们жөӢйҮҸ token co-occurrence overlapпјҡжҲ‘们计算еңЁд»»дҪ•жөӢиҜ•ж ·жң¬дёӯдёҖиө·еҮәзҺ°зҡ„пјҲиҫ“е…ҘжҲ–иҫ“еҮәпјүд»ӨзүҢйӣҶ пјҢ 然еҗҺжөӢйҮҸеңЁжҹҗдәӣи®ӯз»ғж ·жң¬дёӯд№ҹдёҖиө·еҮәзҺ°зҡ„иҝҷдәӣеҜ№зҡ„жҜ”дҫӢ гҖӮ еҜ№дәҺadd primitiveжқЎд»¶ пјҢ GECA е°Ҷ token co-occurrence overlap д»Һ 83%жҸҗй«ҳеҲ° 96%пјӣеҜ№дәҺadd templateжқЎд»¶ пјҢ еҚідҪҝеңЁжү©еўһд№ӢеүҚ пјҢ е®ғд№ҹжҳҜ 100пј… гҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜ пјҢ GECA еҸӘзңӢеҲ°и®ӯз»ғйӣҶ пјҢ е®ғдёҚзҹҘйҒ“ж•°жҚ®зҡ„жҹҗдәӣеӯҗйӣҶеңЁиҜ„дј°ж—¶иў«жҢ‘йҖүеҮәжқҘиҝӣиЎҢжіӣеҢ–жөӢиҜ• гҖӮ ж•°жҚ®жү©еўһеҚҸи®®з”ҹжҲҗдәҶеӨ§йҮҸдёҺжңҹжңӣзҡ„жіӣеҢ–ж— е…ізҡ„дјӘи®ӯз»ғж ·жң¬пјҲеҰӮеӣҫ 3 дёӯзҡ„第дёҖдёӘж ·жң¬пјүпјӣ然иҖҢ пјҢ е®ғд№ҹз”ҹжҲҗдәҶи¶іеӨҹеӨҡзҡ„зӣ®ж ҮжҰӮеҝөзҡ„ж–°з”Ёжі• пјҢ дҪҝеҫ—еӯҰд№ иҖ…иғҪеӨҹжҲҗеҠҹең°иҝӣиЎҢжіӣеҢ– гҖӮ
4гҖҒиҜӯд№үи§ЈжһҗжҺҘдёӢжқҘжҲ‘们е°Ҷи®Ёи®әиҜӯд№үи§Јжһҗй—®йўҳ пјҢ е®ғд№ҹжҳҜдёҖдёӘе…ідәҺз»„еҗҲжҖ§гҖҒжіӣеҢ–е’Ңж•°жҚ®жү©еўһй—®йўҳзҡ„зғӯй—Ёз ”з©¶иҜҫйўҳ гҖӮ еҹәдәҺ第 2 иҠӮи®Ёи®әзҡ„еҺҹеӣ пјҢ жҲ‘们жңҹжңӣеңЁжІЎжңү SCAN еҸ—жҺ§иҜҚжұҮзҡ„жғ…еҶөдёӢ пјҢ иҝҷз§Қж–№жі•еңЁзңҹе®һиҜӯиЁҖж•°жҚ®дёҠзҡ„иЎҢдёәдјҡжңүиҙЁзҡ„дёҚеҗҢ гҖӮ
жҲ‘д»¬з ”з©¶дәҶ GEOQUERY ж•°жҚ®йӣҶзҡ„еӣӣдёӘзүҲжң¬ пјҢ е®ғеҢ…еҗ«дәҶ 880 дёӘе…ідәҺзҫҺеӣҪең°зҗҶзҡ„иӢұиҜӯй—®йўҳ пјҢ 并д»ҘйҖ»иҫ‘иЎЁиҫҫејҸжҲ– SQL жҹҘиҜўзҡ„еҪўејҸдёҺиҜӯд№үиЎЁзӨәиҝӣиЎҢй…ҚеҜ№ гҖӮ жӯӨж•°жҚ®йӣҶзҡ„ж ҮеҮҶи®ӯз»ғ-жөӢиҜ•еҲҶеүІзЎ®дҝқеңЁи®ӯз»ғйӣҶе’ҢжөӢиҜ•йӣҶд№Ӣй—ҙдёҚдјҡйҮҚеӨҚеҮәзҺ°иҮӘ然иҜӯиЁҖй—®йўҳ гҖӮ иҝҷеҸӘжҸҗдҫӣдәҶдёҖдёӘжңүйҷҗзҡ„жіӣеҢ–жөӢиҜ• пјҢ еӣ дёәи®ёеӨҡжөӢиҜ•ж ·жң¬е…·жңүдёҺи®ӯз»ғж•°жҚ®йҮҚеҸ зҡ„йҖ»иҫ‘еҪўејҸпјӣеӣ жӯӨеј•е…ҘдәҶжӣҙе…·жҢ‘жҲҳжҖ§зҡ„queryеҲҶеүІ пјҢ д»ҘзЎ®дҝқй—®йўҳе’ҢйҖ»иҫ‘еҪўејҸйғҪдёҚдјҡйҮҚеӨҚпјҲеҚідҪҝеңЁеҢҝеҗҚе‘ҪеҗҚе®һдҪ“д№ӢеҗҺпјү гҖӮ
жҲ‘们жҸҗеҸ–жңҖеӨҡжңү 2 дёӘй—ҙйҡҷе’ҢжңҖеӨҡ 12 дёӘд»ӨзүҢзҡ„зүҮж®ө гҖӮ еҜ№дәҺ SQL жҹҘиҜўеҲҶеүІ пјҢ еҺҹе§Ӣи®ӯз»ғйӣҶеҢ…еҗ« 695 дёӘж ·жң¬ гҖӮ GECA дҪҝз”Ё 839 дёӘдёҚеҗҢзҡ„жЁЎжқҝе’Ң 379 дёӘдёҚеҗҢзҡ„зүҮж®өз”ҹжҲҗйўқеӨ–зҡ„ 1055 дёӘж ·жң¬ гҖӮ еҜ№дәҺй—®йўҳеҲҶеүІ пјҢ жҲ‘们дҪҝз”ЁдәҶ Jia е’Ң LiangпјҲ2016пјүзҡ„еҹәзәҝжЁЎеһӢпјӣеҜ№дәҺжҹҘиҜўеҲҶеүІ пјҢ жҲ‘们дҪҝз”ЁдёҺ SCAN зӣёеҗҢзҡ„ sequence-to-sequence жЁЎеһӢ пјҢ 并引е…ҘдәҶ Finegan-Dollak зӯүдәәзҡ„зӣ‘зқЈеӨҚеҲ¶жңәеҲ¶ гҖӮ пјҲ2018 е№ҙпјү гҖӮ зҺҜеўғеҶҚж¬Ўиў«и§ҶдёәдёҺжЁЎжқҝзӣёеҗҢ гҖӮ
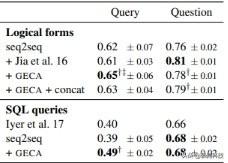
з»“жһңи§ҒиЎЁ 2 гҖӮ еҜ№дәҺ Jia е’Ң LiangпјҲ2016пјүжҠҘе‘Ҡз»“жһңзҡ„еҲҶеүІ пјҢ GECA еңЁиҫғејұзҡ„йўҶеҹҹеҒҮи®ҫдёӢе®һзҺ°дәҶеҮ д№ҺзӣёеҗҢзҡ„ж”№иҝӣ гҖӮ еҜ№дәҺе…¶дҪҷзҡ„еҲҶеүІ пјҢ е®ғжӣҙеҮҶзЎ® гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иЎЁ 2пјҡGEOQUERY ж•°жҚ®йӣҶзҡ„ж„Ҹд№үиЎЁзӨәзІҫзЎ®еҢ№й…ҚзІҫеәҰ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӣҫ 4пјҡз”ЁдәҺеңЁ GEOQUERY дёҠиҝӣиЎҢиҜӯд№үи§Јжһҗзҡ„еҗҲжҲҗж ·жң¬
еҲҶжһҗпјҡж ·жң¬ еӣҫ 4 жҳҫзӨәдәҶйҖ»иҫ‘е’Ң SQL иЎЁзӨәзҡ„еҗҲжҲҗж ·жң¬ гҖӮ е°Ҫз®Ў sequence-to-sequence жЁЎеһӢж—ўжІЎжңүдҪҝз”Ё gold entities пјҢ д№ҹжІЎжңүдҪҝз”Ёдё“й—Ёзҡ„е®һдҪ“й“ҫжҺҘжңәеҲ¶ пјҢ дҪҶжү©еўһиҝҮзЁӢжҲҗеҠҹең°е°ҶиҮӘ然иҜӯиЁҖе®һдҪ“еҗҚз§°дёҺе…¶йҖ»иҫ‘иЎЁзӨәеҜ№йҪҗ пјҢ 并еңЁе®һдҪ“йҖүжӢ©дёӯиҝӣиЎҢдәҶжіӣеҢ– гҖӮ жӯӨиҝҮзЁӢиҝҳдә§з”ҹдәҶеҸҜдҝЎдҪҶжңӘз»ҸиҜҒе®һзҡ„е®һдҪ“ пјҢ дҫӢеҰӮ пјҢ дёҖжқЎеҗҚеҸ« florida зҡ„жІіе’ҢдёҖдёӘеҗҚеҸ« west wyoming зҡ„е·һ гҖӮ
вҖңйҖ»иҫ‘еҪўејҸвҖқйғЁеҲҶзҡ„жңҖеҗҺдёҖдёӘдҫӢеӯҗзү№еҲ«жңүи¶Ј гҖӮ жҸҗеҸ–зҡ„зүҮж®өеңЁиҮӘ然иҜӯиЁҖж–№йқўеҢ…еҗ«жңҖдҪҺзҡ„дәәеҸЈеҜҶеәҰ пјҢ дҪҶеңЁйҖ»иҫ‘еҪўејҸж–№йқўд»…еҢ…еҗ«еҜҶеәҰ гҖӮ дҪҶжҳҜ пјҢ зҺҜеўғдјҡеңЁйҖӮеҪ“зҡ„жғ…еҶөдёӢйҷҗеҲ¶жӣҝжҚўзҡ„еҸ‘з”ҹпјҡд»…еҪ“зҺҜеўғдёӯе·Із»ҸеҢ…еҗ«еҝ…иҰҒзҡ„жңҖе°ҸеҖјж—¶ пјҢ жүҚдҪҝз”ЁжӯӨзүҮж®ө гҖӮ
жңүдәӣжӣҝжҚўеңЁиҜӯд№үдёҠеӯҳеңЁй—®йўҳ:дҫӢеҰӮ пјҢ еӣҫ 4 дёӯзҡ„жңҖеҗҺж•°жҚ®зӮ№иҜўй—®дёҖдёӘж•°еӯ—зҡ„жҖ»дҪ“ж•°йҮҸ(еӣ дёәжӣҝжҚўз”Ё area жӣҝжҚўдәҶ capital);зӣёеә”зҡ„ SQL иЎЁиҫҫејҸе°Ҷж— жі•жү§иЎҢ гҖӮ 然иҖҢ пјҢ йҷӨдәҶзұ»еһӢеҢ–й—®йўҳд№ӢеӨ– пјҢ иҜҘж ·жң¬еңЁиҜӯжі•дёҠжҳҜж јејҸиүҜеҘҪзҡ„ пјҢ 并жҸҗдҫӣдәҶе…ідәҺең°зҗҶйўҶеҹҹеҶ…зҡ„з»„жҲҗиҫ№з•ҢгҖҒи·Ҝзәҝе’ҢеұӮж¬Ўз»“жһ„зҡ„жӯЈзЎ®иҜҒжҚ® гҖӮ е…¶д»–еҗҲжҲҗж ·жң¬пјҲеҰӮеӣҫ 4 дёӯеҖ’数第дәҢдёӘпјүе…·жңүжӯЈзЎ®зҡ„еҗ«д№үиЎЁзӨә пјҢ дҪҶиҫ“е…Ҙзҡ„иҮӘ然иҜӯиЁҖдёҚз¬ҰеҗҲиҜӯжі• гҖӮ
жҺЁиҚҗйҳ…иҜ»







![[и…ҫи®Ҝ科жҠҖ]дәҡ马йҖҠд»“еә“еҸӘиҝӣеҝ…йңҖе“ҒпјҢиҙ·ж¬ҫзј иә«зҡ„еҚ–家дёҡеҠЎеҸ—жҚҹгҖҒеІҢеІҢеҸҜеҚұ](http://ttbs.guangsuss.com/image/5f41d7bbff536ef727029b8fdf70c7a9)






- иҝӣж”»жүҚжҳҜжңҖеҘҪзҡ„йҳІе®ҲпјҒеҚҺдёәжҢүдёӢвҖңеҝ«иҝӣй”®вҖқпјҢдј жқҘ3дёӘеҘҪж¶ҲжҒҜ
- еҚЎеҶ…еҹәжў…йҡҶеӨ§еӯҰжҸҗеҮәдәҶжӣҙеҘҪзҡ„ејәеҜҶз Ғи®ҫзҪ®е»әи®®
- жғ жҷ®жҲҳ66вҖ”вҖ”еҸҜиғҪжҳҜдё»жөҒд»·дҪҚдёӯжңҖеҘҪзҡ„й”®зӣҳдҪ“йӘҢ
- е°Ҹзұі11ж•Ҳд»ҝиӢ№жһңдёҚйҖҒе……з”өеҷЁ жҲ–жңүжӣҙеҘҪзҡ„ж–№ејҸжӣҝд»Ј
- и¶Ҡзә§зҡ„иЎЁзҺ°пјҢдёүж¬ҫйҹіиҙЁи¶…еҘҪзҡ„зңҹж— зәҝиҖіжңәжҺЁиҚҗ
- йҡҸж—¶йҡҸең°зңӢзҢ«зӢ—пјҢйҷҢз”ҹдәәж•Ій—Ёд№ҹдёҚе®іжҖ•пјҢе°ұжҳҜиҝҷд№ҲзҘһеҘҮзҡ„з»„еҗҲ
- иӢ№жһңз ҚеҚ•дәҶ еӨ§иҢғеӣҙеҸ–ж¶Ҳз”ЁжҲ·и®ўеҚ• иҜҙеҘҪзҡ„з”ЁжҲ·жҳҜдёҠеёқе‘ўпјҹ
- йҖӮз”ЁдәҺжңәеҷЁеӯҰд№ гҖҒж•°жҚ®з§‘еӯҰе’Ңж·ұеәҰеӯҰд№ пјҢдёҚеҗҢд»·дҪҚжңҖеҘҪзҡ„笔记жң¬з”өи„‘
- еҚҺдёә Watch Fit еӣҫиөҸпјҡи¶іеӨҹзәӨи–„пјҢд№ҹи¶іеӨҹжҷәж…§
- Lava Be UеңЁеҚ°еәҰеҸ‘еёғ дҪҺз«ҜжүӢжңәиҫ…д»Ҙ2+32GBеҶ…еӯҳз»„еҗҲ