и¶іеӨҹеҘҪзҡ„з»„еҗҲж•°жҚ®жү©еўһ( еӣӣ )
еҲҶжһҗпјҡж•°жҚ®йӣҶз»ҹи®Ў е°Ҷ GECA еә”з”ЁдәҺ GEOQUERY ж•°жҚ®е°ҶдёӨз§ҚиҜӯиЁҖдёӯзҡ„й—®йўҳеҲҶеүІзҡ„ full example overlapпјҲеңЁз¬¬ 3 иҠӮжң«е°ҫжҸҸиҝ°пјүеўһеҠ дәҶ 5% пјҢ е°ҶдҪҝз”ЁйҖ»иҫ‘иЎЁеҚ•зҡ„жҹҘиҜўеҲҶеүІеўһеҠ дәҶ 6% пјҢ е°ҶдҪҝз”Ё SQL иЎЁиҫҫејҸзҡ„жҹҘиҜўеҲҶеүІеўһеҠ дәҶ 9% пјҢ дёҺд»ҘдёӢи§ӮеҜҹз»“жһңдёҖиҮҙпјҡжҹҘиҜўеҲҶеүІзҡ„еҮҶзЎ®жҖ§жҸҗй«ҳжҜ”й—®йўҳеҲҶеүІжӣҙеӨ§ гҖӮ еңЁжүҖжңүжқЎд»¶дёӢ пјҢ жү©еўһйғҪдјҡдҪҝд»ӨзүҢе…ұзҺ°йҮҚеҸ еўһеҠ 3-4пј… гҖӮ
еңЁеҜ№жқҘиҮӘжҹҘиҜўеҲҶеүІзҡ„ 100 дёӘеҗҲжҲҗж ·жң¬зҡ„еӨ§и§„жЁЎдәәе·ҘеҲҶжһҗдёӯ пјҢ иҜ„дј°е®ғ们зҡ„иҜӯжі•жҖ§е’ҢеҮҶзЎ®жҖ§пјҲиҮӘ然иҜӯиЁҖжҳҜеҗҰжҚ•иҺ·йҖ»иҫ‘еҪўејҸзҡ„иҜӯд№үпјү пјҢ жҲ‘们еҸ‘зҺ° 96%жҳҜиҜӯжі•жӯЈзЎ®зҡ„ пјҢ 98%жҳҜиҜӯд№үеҮҶзЎ®зҡ„ гҖӮ
иҙҹйқўз»“жһң жҲ‘们еңЁ Iyer зӯүдәәзҡ„ SCHOLAR text-to-SQL ж•°жҚ®йӣҶдёҠиҝӣиЎҢдәҶзӣёеә”зҡ„е®һйӘҢ гҖӮ иҜҘж•°жҚ®йӣҶеңЁеӨ§е°Ҹ пјҢ еӨҡж ·жҖ§е’ҢеӨҚжқӮжҖ§ж–№йқўдёҺ GEOQUERY зұ»дјј гҖӮ 然иҖҢ пјҢ дёҺ GEOQUERY зӣёжҜ” пјҢ GECA еңЁ SCHOLAR дёӯзҡ„еә”用并没жңүеёҰжқҘд»»дҪ•ж”№иҝӣ гҖӮ еңЁжҹҘиҜўеҲҶеүІдёҠ пјҢ SQL еӯҗжҹҘиҜўзҡ„з»„еҗҲйҮҚз”Ёжңүйҷҗ гҖӮ зӣёеә”ең° пјҢ жү©еўһеҗҺзҡ„ full example overlap дҝқжҢҒдёә 0% пјҢ д»ӨзүҢе…ұзҺ°йҮҚеҸ д»…еўһеҠ 1% гҖӮ иҝҷдәӣз»“жһңиЎЁжҳҺ пјҢ еҪ“ GECA иғҪеӨҹеўһеҠ и®ӯз»ғйӣҶе’ҢжөӢиҜ•йӣҶдёӯеҚ•иҜҚе…ұзҺ°з»ҹи®Ўзҡ„зӣёдјјеәҰ пјҢ д»ҘеҸҠеҪ“иҫ“е…Ҙж•°жҚ®йӣҶиЎЁзҺ°еҮәй«ҳеәҰзҡ„йҖ’еҪ’жҖ§ж—¶ пјҢ GECA жҳҜжңҖжҲҗеҠҹзҡ„ гҖӮ
5гҖҒдҪҺиө„жәҗиҜӯиЁҖе»әжЁЎеүҚйқўзҡ„дёӨдёӘйғЁеҲҶйғҪз ”з©¶дәҶжқЎд»¶жЁЎеһӢ гҖӮдёҺзӨәдҫӢпјҲ4пјүдёҖиҮҙ пјҢ GECA жҸҗеҸ–е’ҢйҮҚз”Ёзҡ„зүҮж®өе®һиҙЁдёҠжҳҜеҗҢжӯҘиҜҚе…ёжқЎзӣ® гҖӮ жҲ‘们жңҖеҲқжҳҜз”ЁеҚ•иҜӯй—®йўҳжқҘжҝҖеҠұ GECA зҡ„ пјҢ еңЁиҝҷдәӣй—®йўҳдёӯ пјҢ жҲ‘们еҸӘжҳҜеёҢжңӣж”№е–„е…ідәҺж јејҸжӯЈзЎ®жҖ§зҡ„жЁЎеһӢеҲӨж–ӯ пјҢ еӣ жӯӨжҲ‘们д»ҘдёҖз»„иҜӯиЁҖе»әжЁЎе®һйӘҢдҪңдёәз»“жқҹ гҖӮ
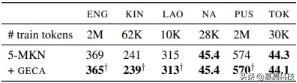
жҲ‘们еңЁдә”з§ҚиҜӯиЁҖ(Kinyarwanda, Lao, Pashto, Tok Pisin, and a subset of English Wikipedia)дёҠдҪҝз”Ё Wikipedia dumps пјҢ д»ҘеҸҠ Adams зӯүдәәзҡ„ Na ж•°жҚ®йӣҶ гҖӮ иҝҷдәӣиҜӯиЁҖеұ•зӨәдәҶ GECA еңЁеҗ„з§ҚеҪўжҖҒеӨҚжқӮжҖ§ж–№йқўзҡ„иЎЁзҺ°пјҡдҫӢеҰӮ пјҢ Kinyarwanda жңүдёҖдёӘеӨҚжқӮзҡ„еҗҚиҜҚзұ»зі»з»ҹ пјҢ Pashto жңүдё°еҜҢзҡ„жҙҫз”ҹиҜҚжі• пјҢ иҖҢ Lao е’Ң Tok Pisin еңЁеҪўжҖҒдёҠзӣёеҜ№з®ҖеҚ• гҖӮ и®ӯз»ғж•°жҚ®йӣҶд»Һ 10K еҲ° 2M д»ӨзүҢдёҚзӯү гҖӮ дёҺ Adams зӯүдәәдёҖж · пјҢ жҲ‘们еҸ‘зҺ° 5-gram modified Kneser-Ney иҜӯиЁҖжЁЎеһӢдјҳдәҺеҮ з§Қ RNN иҜӯиЁҖжЁЎеһӢ пјҢ еӣ жӯӨжҲ‘们е°Ҷ GECA е®һйӘҢе»әз«ӢеңЁ n-gram жЁЎеһӢдёҠ гҖӮ жҲ‘们дҪҝз”Ё KenLM дёӯжҸҗдҫӣзҡ„е®һзҺ° гҖӮ
жҲ‘们жҸҗеҸ–ж— й—ҙйҡҷдё”жңҖеӨ§еӨ§е°Ҹдёә 2 дёӘд»ӨзүҢзҡ„зүҮж®ө пјҢ зҺҜеўғиў«и§Ҷдёәеӣҙз»•жүҖжҸҗеҸ–зүҮж®өзҡ„ 2 дёӘд»ӨзүҢзӘ—еҸЈ гҖӮ ж–°з”Ёжі•д»…й’ҲеҜ№ж•°жҚ®дёӯеҮәзҺ°ж¬Ўж•°е°‘дәҺ 20 ж¬Ўзҡ„зүҮж®өз”ҹжҲҗ гҖӮ еңЁ Kinyarwanda иҜӯиЁҖдёӯ пјҢ еҹәжң¬ж•°жҚ®йӣҶеҢ…еҗ« 3358 дёӘеҸҘеӯҗ гҖӮ GECA дҪҝз”Ё 913 дёӘдёҚеҗҢзҡ„жЁЎжқҝе’Ң 199 дёӘдёҚеҗҢзҡ„зүҮж®өз”ҹжҲҗйўқеӨ–зҡ„ 913 дёӘж ·жң¬ гҖӮ
жҲ‘们еҸ‘зҺ°жңҖеҘҪзҡ„жҖ§иғҪжқҘиҮӘдәҺеңЁеҺҹе§Ӣж•°жҚ®йӣҶе’Ңжү©еўһж•°жҚ®йӣҶдёҠи®ӯз»ғдёҖдёӘиҜӯиЁҖжЁЎеһӢ пјҢ 然еҗҺжҸ’еҖје®ғ们зҡ„жңҖз»ҲжҰӮзҺҮ пјҢ иҖҢдёҚжҳҜеғҸеүҚйқўзҡ„з« иҠӮйӮЈж ·зӣҙжҺҘеңЁжү©еўһж•°жҚ®йӣҶдёҠи®ӯз»ғиҜӯиЁҖжЁЎеһӢ гҖӮ жӯӨжҸ’еҖјзҡ„жқғйҮҚеңЁйӘҢиҜҒж•°жҚ®йӣҶдёҠзЎ®е®ҡ пјҢ 并йҖүжӢ© 0.05гҖҒ0.1 е’Ң 0.5 дёӯзҡ„дёҖдёӘ гҖӮ
з»“жһңи§ҒиЎЁ 4 гҖӮ ж”№иҝӣдёҚжҳҜжҷ®йҒҚзҡ„ пјҢ 并且жҜ”еүҚеҮ иҠӮиҰҒжё©е’Ң гҖӮ дҪҶжҳҜ пјҢ GECA еҸҜд»ҘеҮҸе°‘еӨҡз§ҚиҜӯиЁҖд№Ӣй—ҙзҡ„еӣ°жғ‘еәҰ пјҢ иҖҢдёҚдјҡдҪҝе…¶еўһеҠ гҖӮ иҝҷдәӣз»“жһңиЎЁжҳҺ пјҢ еҚідҪҝеңЁжқЎд»¶д»»еҠЎе’ҢзҘһз»ҸжЁЎеһӢд№ӢеӨ– пјҢ GECA иғҢеҗҺзҡ„жӣҝжҚўеҺҹзҗҶд№ҹжҳҜдёҖз§Қйј“еҠұеҗҲжҲҗзҡ„жңүз”ЁжңәеҲ¶ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иЎЁ 4пјҡEnglishпјҲENGпјү пјҢ KinyarwandaпјҲKINпјү пјҢ Lao пјҢ Na пјҢ PashtoпјҲPUSпјүе’Ң Tok PisinпјҲTOKпјүзҡ„дҪҺиө„жәҗиҜӯиЁҖе»әжЁЎеӣ°жғ‘еәҰ гҖӮ
еҲҶжһҗпјҡж ·жң¬е’Ңз»ҹи®Ў еңЁиҜӯиЁҖе»әжЁЎдёӯ пјҢ GECA дҪңдёәдёҖз§Қе№іж»‘ж–№жЎҲпјҡе®ғзҡ„дё»иҰҒдҪңз”ЁжҳҜе°ҶеӨ§йҮҸж•°жҚ®з§»еҗ‘еҸҜд»ҘеҮәзҺ°еңЁз”ҹдә§жҖ§дёҠдёӢж–Үдёӯзҡ„ n-grams гҖӮ д»ҺиҝҷдёӘж„Ҹд№үдёҠиҜҙ пјҢ GECA зҡ„дҪңз”Ёзұ»дјјдәҺжүҖжңү LM е®һйӘҢдёӯдҪҝз”Ёзҡ„ Kneser-Ney е№іж»‘жі• гҖӮ дёҺ Kneser-Ney дёҚеҗҢзҡ„жҳҜ пјҢ GECA зҡ„вҖңдёҠдёӢж–ҮвҖқжҰӮеҝөж—ўеҸҜд»Ҙеҗ‘еүҚзңӢ пјҢ д№ҹеҸҜд»Ҙеҗ‘еҗҺзңӢ пјҢ 并且еҸҜд»ҘжҚ•жҚүжӣҙй•ҝж—¶й—ҙзҡ„дә’еҠЁдҪңз”Ё гҖӮ
еҗҲжҲҗеҸҘеӯҗзҡ„дҫӢеӯҗеҰӮеӣҫ 5 жүҖзӨә гҖӮ еӨ§еӨҡж•°еҸҘеӯҗйғҪжҳҜиҜӯжі•жҖ§зҡ„ пјҢ и®ёеӨҡжӣҝжҚўйЎ№дҝқз•ҷдәҶзӣёе…ізҡ„иҜӯд№үзұ»еһӢдҝЎжҒҜпјҲз”Ё locations д»Јжӣҝ locations пјҢ з”Ё times д»Јжӣҝ times зӯүпјү пјҢ дҪҶиҝҳжҳҜдјҡз”ҹжҲҗдёҖдәӣж јејҸй”ҷиҜҜзҡ„еҸҘеӯҗ гҖӮ
жҺЁиҚҗйҳ…иҜ»







![[и…ҫи®Ҝ科жҠҖ]дәҡ马йҖҠд»“еә“еҸӘиҝӣеҝ…йңҖе“ҒпјҢиҙ·ж¬ҫзј иә«зҡ„еҚ–家дёҡеҠЎеҸ—жҚҹгҖҒеІҢеІҢеҸҜеҚұ](http://ttbs.guangsuss.com/image/5f41d7bbff536ef727029b8fdf70c7a9)






- иҝӣж”»жүҚжҳҜжңҖеҘҪзҡ„йҳІе®ҲпјҒеҚҺдёәжҢүдёӢвҖңеҝ«иҝӣй”®вҖқпјҢдј жқҘ3дёӘеҘҪж¶ҲжҒҜ
- еҚЎеҶ…еҹәжў…йҡҶеӨ§еӯҰжҸҗеҮәдәҶжӣҙеҘҪзҡ„ејәеҜҶз Ғи®ҫзҪ®е»әи®®
- жғ жҷ®жҲҳ66вҖ”вҖ”еҸҜиғҪжҳҜдё»жөҒд»·дҪҚдёӯжңҖеҘҪзҡ„й”®зӣҳдҪ“йӘҢ
- е°Ҹзұі11ж•Ҳд»ҝиӢ№жһңдёҚйҖҒе……з”өеҷЁ жҲ–жңүжӣҙеҘҪзҡ„ж–№ејҸжӣҝд»Ј
- и¶Ҡзә§зҡ„иЎЁзҺ°пјҢдёүж¬ҫйҹіиҙЁи¶…еҘҪзҡ„зңҹж— зәҝиҖіжңәжҺЁиҚҗ
- йҡҸж—¶йҡҸең°зңӢзҢ«зӢ—пјҢйҷҢз”ҹдәәж•Ій—Ёд№ҹдёҚе®іжҖ•пјҢе°ұжҳҜиҝҷд№ҲзҘһеҘҮзҡ„з»„еҗҲ
- иӢ№жһңз ҚеҚ•дәҶ еӨ§иҢғеӣҙеҸ–ж¶Ҳз”ЁжҲ·и®ўеҚ• иҜҙеҘҪзҡ„з”ЁжҲ·жҳҜдёҠеёқе‘ўпјҹ
- йҖӮз”ЁдәҺжңәеҷЁеӯҰд№ гҖҒж•°жҚ®з§‘еӯҰе’Ңж·ұеәҰеӯҰд№ пјҢдёҚеҗҢд»·дҪҚжңҖеҘҪзҡ„笔记жң¬з”өи„‘
- еҚҺдёә Watch Fit еӣҫиөҸпјҡи¶іеӨҹзәӨи–„пјҢд№ҹи¶іеӨҹжҷәж…§
- Lava Be UеңЁеҚ°еәҰеҸ‘еёғ дҪҺз«ҜжүӢжңәиҫ…д»Ҙ2+32GBеҶ…еӯҳз»„еҗҲ