利用反义数据扩增技术来降低语法形态丰富语言中的性别偏见( 二 )
 文章插图
文章插图
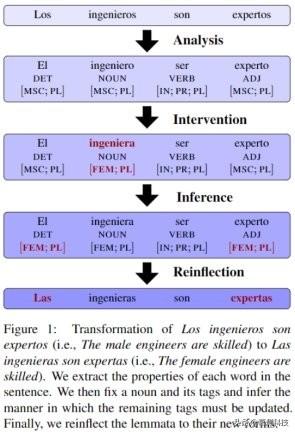
本文的方法:本文的目标是将句子
(1)转换为句子(2) , 反之亦然 。 据本文所知 , 这个转换以前没有人研究过 。 事实上 , 目前也没有一个标注成对句子用来训练监督模型的语料库 。 基于此 , 本文运用一种无监督的方法 , 利用依存树、词目、词性(POS)标注与来源于 Universal Dependencies(UD)语料库的词性句法标注 。 简而言之 , 本文提出了以下四个步骤 。
- 分析句子(包括语法分析、词形分析与词形还原)
- 干预一个表示性别的词
- 推理出新的形态句法标签
- 替换成新词干
 文章插图
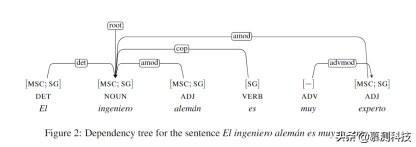
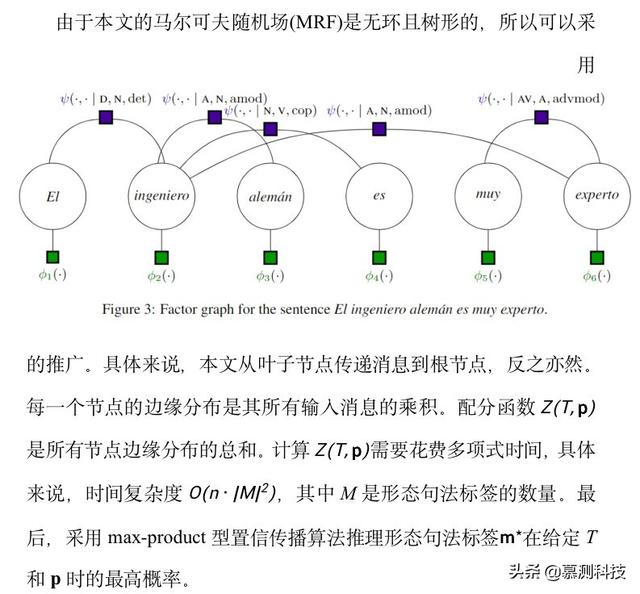
文章插图3 一种用于形态与句法的马尔可夫随机场【利用反义数据扩增技术来降低语法形态丰富语言中的性别偏见】在这一节 , 本文采用一个用于形态与句法的马尔可夫随机场(MRF) , 该模型定义了一个对形态句法标记序列的联合分布 , 且被训练于一个被标注词性标签的依存树 。 如果更换了一个表示性别的词 , 本文可以使用这个模型对哪些单词需要更新进行推断 , 以保持形态与句法的一致 。
一个句子的依存树(例子如图 2)是一组有序三元组(i ,j ,l) , i 和 j 是
 文章插图
文章插图 文章插图
文章插图 文章插图
文章插图3.1 参数化
 文章插图
文章插图 文章插图
文章插图3.2 推理
 文章插图
文章插图3.3 参数估计
 文章插图
文章插图4 干预手段
 文章插图
文章插图 文章插图
文章插图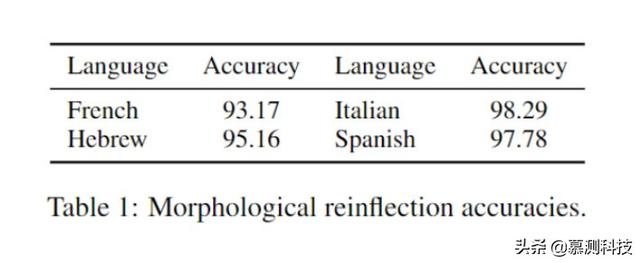 文章插图
文章插图5 实验
 文章插图
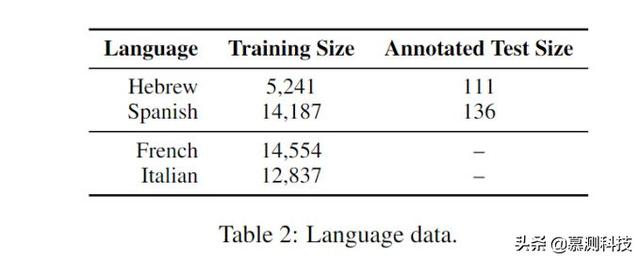
文章插图5.1 内部评估就目前所知 , 这个任务以前没有被研究过 。 因此 , 不存在一个被标注的成对句子语料库作为准确的基准 。 因此本文自己标注西班牙语和希伯来语句子 , 同时每种语言的母语者对句子进行注释 。 具体来说 , 对于每种语言 , 本文从 UD treebank 中提取包含有灵名词的句子 。 被提取的句子的平均长度是 37 个单词 。 本文手动检查每个句子 , 对有灵名词的性别进行干预 , 然后句子进行重新屈折 。 本文选择了西班牙语与希伯来语 , 因为不同语言的性别变换语法不同 。 本文在表 2 的前两行中提供了这两种语言的语料库统计数据 。
 文章插图
文章插图 文章插图
文章插图
推荐阅读















- 西部数据在CES 2021推出多款4TB容量的旗舰级SSD
- WhatsApp收集用户数据新政惹众怒,“删除WhatsApp”在土耳其上热搜
- 大一非计算机专业的学生,如何利用寒假自学C语言
- TikTok推出首个利用iPhone 12 Pro LiDAR技术的AR特效
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露