利用反义数据扩增技术来降低语法形态丰富语言中的性别偏见( 四 )
 文章插图
文章插图
对于每个包含有灵名词的句子 , 本文创建了副本 , 对有灵名词进行干预 , 然后使用本文的方法对句子进行转换 。 对于那些包含不止一个有灵名词的句子 , 本文为每一种性别组合都生成一个单独的句子 。 因此 , 选择复制哪个句子是一项困难的任务 , 例如 alem ?an 在西班牙语中有德国男人或者德国语言的意思 。 Jahan 等人提出的多语种有灵名词检测可能有助于本文应对这个困难 , 指代信息也可能提供额外的帮助 。
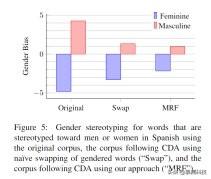
对于每种语言 , 本文分别采用原始语料库(Original)、CDA 中只是灵名词交换的语料库(Swap)与 CDA 采用本文的方法的语料库(MRF)对 BPE-RNNLM 开放式词典的基准语言模型进行训练 。 然后本文计算了上述模型的性别偏见和语法性 。 本文在表 5 中提供了一些例句 , 本文在附录 C 中提供了更广泛的例句列表 。
 文章插图
文章插图
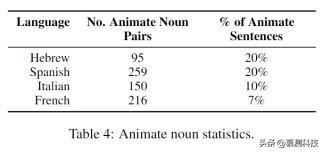
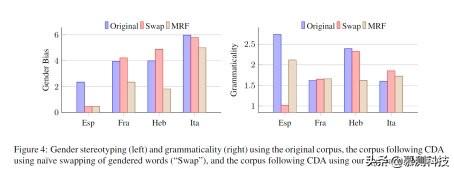
结果:图 4 展示了每种语言的在三种语料库训练下性别偏见和语法性的情况 , 显而易见的是 , 本文的方法降低了性别偏见 。 就平均而言 , 本文的方法将性别偏见减小到原来的 40%(减少最多的为西班牙语变成原来的 20% , 最少的是意大利语为原来的 83.3%) 。 本文预计单纯替换性别单词的方法也能降低性别偏见 。 事实上 , 这种朴素的降低性别偏见的方法只适用于一些并不是所有语言 。 对于西班牙语 , 本文也检测了性别偏见是偏向男性或者女性 。 如果一个词中同一种性别占到了 75%以上 , 本文定义这个词为性别偏见词 。 图 5 表明 , 本文的方法使得针对具体词汇的男性或者女性的性别偏见明显降低 。
 文章插图
文章插图
 文章插图
文章插图
不同语言的语法性在本文的方法下表现不同 , 也就是除了希伯来语 , 本文的方法牺牲的语法性比单纯替换要少 , 而且有时还能提高语法性且超过原始语料库的语法性 。 因为本文知道这个模型在希伯来语中准确率不高(如表 3 所示) , 所以这一发现并不令人惊讶 。
6 相关工作相较于以前的工作 , 本文更聚焦于减轻那些语法形态丰富的语言的性别偏见 , 特别是那些存在性别协议的语言 。 时至今日 , NLP 社区主要集中于英语中的性别偏见的检测和降低方法研究 。 例如 Bolukbasi 等人提出了一种减轻在词嵌入中的性别偏见并且同时保留词义的方法 。 Lu 等人研究了在语言模型中的性别偏见 。 Rudinger 等人介绍了一种新奇的 Winograd Schema 挑战 , 并且用于评估指代消解中的性别偏见 。 与本文的研究最相关的是 Zhao 等人使用 CDA 减轻指代消解中的性别偏见 , 然而 , 他们的方法运用在语法形态丰富的语言时会产生不符合语法的句子 。 本文的方法是专门为了应用于此类语言时 , 产生符合语法的句子 。 Habash 等人也聚焦于语法形态丰富的语言 , 特别是阿拉伯语 , 但是在基于机器翻译的性别识别的背景下 。
7 结论本文提出了一种运用于语法形态丰富的语言中转换男性屈折与女性屈折名词短语的新方法 。 为了实现此方法 , 本文介绍了一种可选神经参数化的马尔可夫随机场 , 用来推理当改变了特定名词语法性别时 , 句子中哪些部分需要改变以保持形态句法不变 。 就目前所知 , 这个任务以前没有被研究过 。 因此 , 不存在一个被标注的成对句子语料库作为准确的基准 。 尽管存在此局限性 , 本文还是对本文的方法进行了内部和外部的评估 , 并取得了可喜的结果 。 例如 , 本文证明了本文的方法有效降低了神经语言模型中的性别偏见 。 最后 , 本文还确定了未来的工作路径 , 例如 , 在本文的方法中包括指代信息 。
推荐阅读
















- 西部数据在CES 2021推出多款4TB容量的旗舰级SSD
- WhatsApp收集用户数据新政惹众怒,“删除WhatsApp”在土耳其上热搜
- 大一非计算机专业的学生,如何利用寒假自学C语言
- TikTok推出首个利用iPhone 12 Pro LiDAR技术的AR特效
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露