еҰӮд»Ҡ пјҢ жңәеҷЁе·Із»ҸиғҪеӨҹеңЁзҗҶи§ЈгҖҒиҜҶеҲ«еӣҫеғҸдёӯзҡ„зү№еҫҒе’ҢеҜ№иұЎзӯүйўҶеҹҹе®һзҺ°99пј…зә§еҲ«зҡ„еҮҶзЎ®зҺҮ гҖӮ з”ҹжҙ»дёӯ пјҢ жҲ‘们жҜҸеӨ©йғҪдјҡиҝҗз”ЁеҲ°иҝҷдёҖзӮ№ пјҢ жҜ”еҰӮ пјҢ жҷәиғҪжүӢжңәжӢҚз…§зҡ„ж—¶еҖҷиғҪеӨҹиҜҶеҲ«и„ёйғЁгҖҒеңЁзұ»дјјдәҺи°·жӯҢжҗңеӣҫдёӯжҗңзҙўзү№е®ҡз…§зүҮгҖҒд»ҺжқЎеҪўз Ғжү«жҸҸж–Үжң¬жҲ–жү«жҸҸд№ҰзұҚзӯү гҖӮ йҖ е°ұжңәеҷЁиғҪеӨҹиҺ·еҫ—еңЁиҝҷдәӣи§Ҷи§үж–№йқўеҸ–еҫ—дјҳејӮжҖ§иғҪеҸҜиғҪжҳҜжәҗдәҺдёҖз§Қзү№е®ҡзұ»еһӢзҡ„зҘһз»ҸзҪ‘з»ңвҖ”вҖ”еҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјҲCNNпјү гҖӮ еҰӮжһңдҪ жҳҜдёҖдёӘж·ұеәҰеӯҰд№ зҲұеҘҪиҖ… пјҢ дҪ еҸҜиғҪж—©е·Іеҗ¬иҜҙиҝҮиҝҷз§ҚзҘһз»ҸзҪ‘з»ң пјҢ 并且еҸҜиғҪе·Із»ҸдҪҝз”ЁдёҖдәӣж·ұеәҰеӯҰд№ жЎҶжһ¶жҜ”еҰӮcaffeгҖҒTensorFlowгҖҒpytorchе®һзҺ°дәҶдёҖдәӣеӣҫеғҸеҲҶзұ»еҷЁ гҖӮ 然иҖҢ пјҢ иҝҷд»Қ然еӯҳеңЁдёҖдёӘй—®йўҳпјҡж•°жҚ®жҳҜеҰӮдҪ•еңЁдәәе·ҘзҘһз»ҸзҪ‘з»ңдј йҖҒд»ҘеҸҠи®Ўз®—жңәжҳҜеҰӮдҪ•д»ҺдёӯеӯҰд№ зҡ„ гҖӮ дёәдәҶд»ҺеӨҙејҖе§ӢиҺ·еҫ—жё…жҷ°зҡ„и§Ҷи§’ пјҢ жң¬ж–Үе°ҶйҖҡиҝҮеҜ№жҜҸдёҖеұӮиҝӣиЎҢеҸҜи§ҶеҢ–д»Ҙж·ұе…ҘзҗҶи§ЈеҚ·з§ҜзҘһз»ҸзҪ‘з»ң гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҚ·з§ҜзҘһз»ҸзҪ‘з»ңеңЁеӯҰд№ еҚ·з§ҜзҘһз»ҸзҪ‘з»ңд№ӢеүҚ пјҢ йҰ–е…ҲиҰҒдәҶи§ЈзҘһз»ҸзҪ‘з»ңзҡ„е·ҘдҪңеҺҹзҗҶ гҖӮ зҘһз»ҸзҪ‘з»ңжҳҜжЁЎд»ҝдәәзұ»еӨ§и„‘жқҘи§ЈеҶіеӨҚжқӮй—®йўҳ并еңЁз»ҷе®ҡж•°жҚ®дёӯжүҫеҲ°жЁЎејҸзҡ„дёҖз§Қж–№жі• гҖӮ еңЁиҝҮеҺ»еҮ е№ҙдёӯ пјҢ иҝҷдәӣзҘһз»ҸзҪ‘з»ңз®—жі•е·Із»Ҹи¶…и¶ҠдәҶи®ёеӨҡдј з»ҹзҡ„жңәеҷЁеӯҰд№ е’Ңи®Ўз®—жңәи§Ҷи§үз®—жі• гҖӮ вҖңзҘһз»ҸзҪ‘з»ңвҖқжҳҜз”ұеҮ еұӮжҲ–еӨҡеұӮз»„жҲҗ пјҢ дёҚеҗҢеұӮдёӯе…·жңүеӨҡдёӘзҘһз»Ҹе…ғ гҖӮ жҜҸдёӘзҘһз»ҸзҪ‘з»ңйғҪжңүдёҖдёӘиҫ“е…Ҙе’Ңиҫ“еҮәеұӮ пјҢ ж №жҚ®й—®йўҳзҡ„еӨҚжқӮжҖ§еўһеҠ йҡҗи—ҸеұӮзҡ„дёӘж•° гҖӮ дёҖж—Ұе°Ҷж•°жҚ®йҖҒе…ҘзҪ‘з»ңдёӯ пјҢ зҘһз»Ҹе…ғе°ұдјҡеӯҰд№ е№¶иҝӣиЎҢжЁЎејҸиҜҶеҲ« гҖӮ дёҖж—ҰзҘһз»ҸзҪ‘з»ңжЁЎеһӢиў«и®ӯз»ғеҘҪеҗҺ пјҢ жЁЎеһӢе°ұиғҪеӨҹйў„жөӢжөӢиҜ•ж•°жҚ® гҖӮ
еҸҰдёҖж–№йқў пјҢ CNNжҳҜдёҖз§Қзү№ж®Ҡзұ»еһӢзҡ„зҘһз»ҸзҪ‘з»ң пјҢ е®ғеңЁеӣҫеғҸйўҶеҹҹдёӯиЎЁзҺ°еҫ—йқһеёёеҘҪ гҖӮ иҜҘзҪ‘з»ңжҳҜз”ұYanLeCunnеңЁ1998е№ҙжҸҗеҮәзҡ„ пјҢ иў«еә”з”ЁдәҺж•°еӯ—жүӢеҶҷдҪ“иҜҶеҲ«д»»еҠЎдёӯ гҖӮ е…¶е®ғеә”з”ЁйўҶеҹҹеҢ…жӢ¬иҜӯйҹіиҜҶеҲ«гҖҒеӣҫеғҸеҲҶеүІе’Ңж–Үжң¬еӨ„зҗҶзӯү гҖӮ еңЁCNNиў«еҸ‘жҳҺд№ӢеүҚ пјҢ еӨҡеұӮж„ҹзҹҘжңәпјҲMLPпјүиў«з”ЁдәҺжһ„е»әеӣҫеғҸеҲҶзұ»еҷЁ гҖӮ еӣҫеғҸеҲҶзұ»д»»еҠЎжҳҜжҢҮд»ҺеӨҡжіўж®өпјҲеҪ©иүІгҖҒй»‘зҷҪпјүе…үж …еӣҫеғҸдёӯжҸҗеҸ–дҝЎжҒҜзұ»зҡ„д»»еҠЎ гҖӮ MLPйңҖиҰҒжӣҙеӨҡзҡ„ж—¶й—ҙе’Ңз©әй—ҙжқҘжҹҘжүҫеӣҫзүҮдёӯзҡ„дҝЎжҒҜ пјҢ еӣ дёәжҜҸдёӘиҫ“е…Ҙе…ғзҙ йғҪдёҺдёӢдёҖеұӮдёӯзҡ„жҜҸдёӘзҘһз»Ҹе…ғиҝһжҺҘ гҖӮ иҖҢCNNйҖҡиҝҮдҪҝз”Ёз§°дёәеұҖйғЁиҝһжҺҘзҡ„жҰӮеҝөйҒҝе…Қиҝҷдәӣ пјҢ е°ҶжҜҸдёӘзҘһз»Ҹе…ғиҝһжҺҘеҲ°иҫ“е…Ҙзҹ©йҳөзҡ„еұҖйғЁеҢәеҹҹ гҖӮ иҝҷйҖҡиҝҮе…Ғи®ёзҪ‘з»ңзҡ„дёҚеҗҢйғЁеҲҶдё“й—ЁеӨ„зҗҶиҜёеҰӮзә№зҗҶжҲ–йҮҚеӨҚжЁЎејҸзҡ„й«ҳзә§зү№еҫҒжқҘжңҖе°ҸеҢ–еҸӮж•°зҡ„ж•°йҮҸ гҖӮ дёӢйқўйҖҡиҝҮжҜ”иҫғиҜҙжҳҺдёҠиҝ°иҝҷдёҖзӮ№ гҖӮ
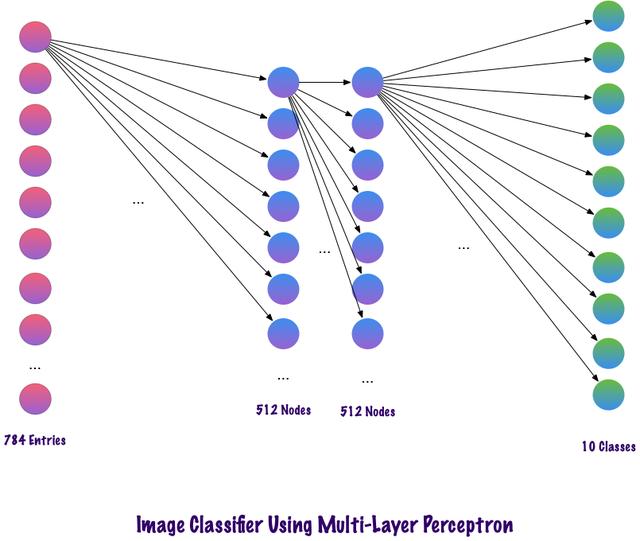
жҜ”иҫғMLPе’ҢCNNеӣ дёәиҫ“е…ҘеӣҫеғҸзҡ„еӨ§е°Ҹдёә28x28=784пјҲMNISTж•°жҚ®йӣҶпјү пјҢ MLPзҡ„иҫ“е…ҘеұӮзҘһз»Ҹе…ғжҖ»ж•°е°Ҷдёә784 гҖӮ зҪ‘з»ңйў„жөӢз»ҷе®ҡиҫ“е…ҘеӣҫеғҸдёӯзҡ„ж•°еӯ— пјҢ иҫ“еҮәж•°еӯ—иҢғеӣҙжҳҜ0-9 гҖӮ еңЁиҫ“еҮәеұӮ пјҢ дёҖиҲ¬иҝ”еӣһзҡ„жҳҜзұ»еҲ«еҲҶж•° пјҢ жҜ”еҰӮиҜҙз»ҷе®ҡиҫ“е…ҘжҳҜж•°еӯ—вҖң3вҖқзҡ„еӣҫеғҸ пјҢ йӮЈд№ҲеңЁиҫ“еҮәеұӮдёӯ пјҢ зӣёеә”зҡ„зҘһз»Ҹе…ғвҖң3вҖқдёҺе…¶е®ғзҘһз»Ҹе…ғзӣёжҜ”е…·жңүжӣҙй«ҳзҡ„зұ»еҲ«еҲҶж•° гҖӮ иҝҷйҮҢеҸҲдјҡеҮәзҺ°дёҖдёӘй—®йўҳ пјҢ жЁЎеһӢйңҖиҰҒеҢ…еҗ«еӨҡе°‘дёӘйҡҗи—ҸеұӮ пјҢ жҜҸеұӮеә”иҜҘеҢ…еҗ«еӨҡе°‘зҘһз»Ҹе…ғпјҹиҝҷдәӣйғҪжҳҜйңҖиҰҒдәәдёәи®ҫзҪ®зҡ„ пјҢ дёӢйқўжҳҜдёҖдёӘжһ„е»әMLPжЁЎеһӢзҡ„дҫӢеӯҗпјҡ
Num_classes = 10Model = Sequntial()Model.add(Dense(512, activation=вҖҷreluвҖҷ, input_shape=(784, )))Model.add(Dropout(0.2))Model.add(Dense(512, activation=вҖҷreluвҖҷ))Model.add(Dropout(0.2))Model.add(Dense(num_classes, activation=вҖҷsoftmaxвҖҷ))дёҠйқўзҡ„д»Јз ҒзүҮж®өжҳҜдҪҝз”ЁKerasжЎҶжһ¶е®һзҺ°пјҲжҡӮж—¶еҝҪз•ҘиҜӯжі•й”ҷиҜҜпјү пјҢ иҜҘд»Јз ҒиЎЁжҳҺ第дёҖдёӘйҡҗи—ҸеұӮдёӯжңү512дёӘзҘһз»Ҹе…ғ пјҢ иҝһжҺҘеҲ°з»ҙеәҰдёә784зҡ„иҫ“е…ҘеұӮ гҖӮ йҡҗи—ҸеұӮеҗҺйқўеҠ дёҖдёӘdropoutеұӮ пјҢ дёўејғжҜ”дҫӢи®ҫзҪ®дёә0.2 пјҢ иҜҘж“ҚдҪңеңЁдёҖе®ҡзЁӢеәҰдёҠе…ӢжңҚиҝҮжӢҹеҗҲзҡ„й—®йўҳ гҖӮ д№ӢеҗҺеҶҚж¬Ўж·»еҠ 第дәҢдёӘйҡҗи—ҸеұӮ пјҢ д№ҹе…·жңү512и°·жӯҢзҘһз»Ҹе…ғ пјҢ 然еҗҺеҶҚж·»еҠ дёҖдёӘdropoutеұӮ гҖӮ жңҖеҗҺ пјҢ дҪҝз”ЁеҢ…еҗ«10дёӘзұ»зҡ„иҫ“еҮәеұӮе®ҢжҲҗжЁЎеһӢжһ„е»ә гҖӮ е…¶иҫ“еҮәзҡ„еҗ‘йҮҸдёӯе…·жңүжңҖеӨ§еҖјзҡ„иҜҘзұ»е°ҶжҳҜжЁЎеһӢзҡ„йў„жөӢз»“жһң гҖӮ
иҝҷз§ҚеӨҡеұӮж„ҹзҹҘеҷЁзҡ„дёҖдёӘзјәзӮ№жҳҜеұӮдёҺеұӮд№Ӣй—ҙе®Ңе…ЁиҝһжҺҘ пјҢ иҝҷеҜјиҮҙжЁЎеһӢйңҖиҰҒиҠұиҙ№жӣҙеӨҡзҡ„и®ӯз»ғж—¶й—ҙе’ҢеҸӮж•°з©әй—ҙ гҖӮ 并且 пјҢ MLPеҸӘжҺҘеҸ—еҗ‘йҮҸдҪңдёәиҫ“е…Ҙ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»


















- дёүжҳҹеҸ‘еёғж–°з”өи§Ҷпјҡ99.99%еұҸеҚ жҜ” 8Kиҫ“еҮә
- Facebook Messenger收йӣҶзҡ„ж•°жҚ®йҮҸжңүеӨҡеҗ“дәәпјҹеҸҜи§ҶеҢ–еҜ№жҜ”еӣҫе‘ҠиҜүдҪ
- ж•°жҚ®еҸҜи§ҶеҢ–дёүиҠӮиҜҫд№ӢдәҢпјҡеҸҜи§ҶеҢ–зҡ„дҪҝз”Ё
- еҺҶж—¶ 1 дёӘжңҲпјҢеҒҡдәҶ 10 дёӘ Python еҸҜи§ҶеҢ–еҠЁеӣҫпјҢз”Ёеҝғдё”зІҫзҫҺ...
- е…¬зүӣжҺЁеҮәз”өз«һе……з”өеҷЁпјҢ1A1CеҸҢиҫ“еҮәпјҢйӣҶжҲҗиғҪйҮҸе‘јеҗёзҒҜ
- еңЁLinuxзі»з»ҹдёӯе®үиЈ…ж·ұеәҰеӯҰд№ жЎҶжһ¶Pytorch
- дёәдҪ•еӯҰд№ зј–зЁӢеҫҖеҫҖйғҪжҳҜд»Һзј–еҶҷиҫ“еҮәHelloWorldзҡ„зЁӢеәҸејҖе§Ӣ
- MOMAXжҺЁеҮә20W 1A1C PDе……з”өеҷЁпјҢж”ҜжҢҒеҸҢеҸЈиҫ“еҮә
- ж•°жҚ®|еҚ—ж–№з”өзҪ‘и¶…й«ҳеҺӢе…¬еҸёжҲҗеҠҹдёҫеҠһйҰ–еұҠж•°жҚ®еҸҜи§ҶеҢ–еҲҶжһҗеӨ§иөӣ
- 30иЎҢPythonд»Јз Ғе®һзҺ°3Dж•°жҚ®еҸҜи§ҶеҢ–пјҒйқһеёёжғҠиүі