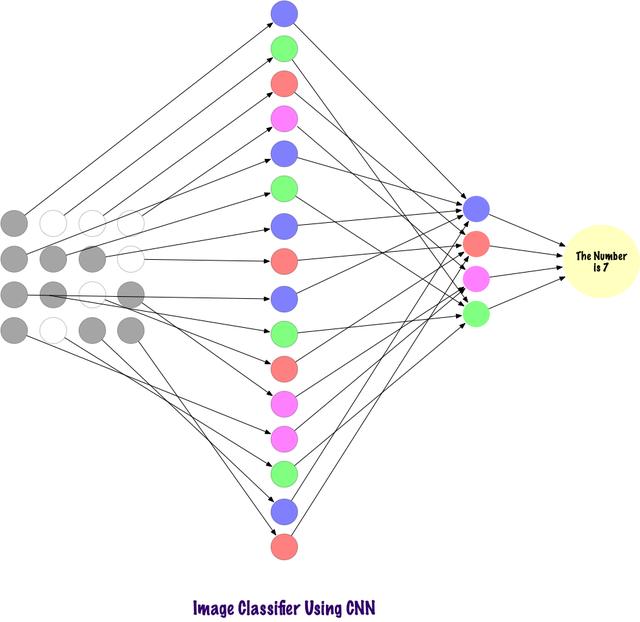
еҚ·з§ҜдҪҝз”ЁзЁҖз–ҸиҝһжҺҘзҡ„еұӮ пјҢ 并且其иҫ“е…ҘеҸҜд»ҘжҳҜзҹ©йҳө пјҢ дјҳдәҺMLP гҖӮ иҫ“е…Ҙзү№еҫҒиҝһжҺҘеҲ°еұҖйғЁзј–з ҒиҠӮзӮ№ гҖӮ еңЁMLPдёӯ пјҢ жҜҸдёӘиҠӮзӮ№йғҪжңүиғҪеҠӣеҪұе“Қж•ҙдёӘзҪ‘з»ң гҖӮ иҖҢCNNе°ҶеӣҫеғҸеҲҶи§ЈдёәеҢәеҹҹпјҲеғҸзҙ зҡ„е°ҸеұҖйғЁеҢәеҹҹпјү пјҢ жҜҸдёӘйҡҗи—ҸиҠӮзӮ№дёҺиҫ“еҮәеұӮзӣёе…і пјҢ иҫ“еҮәеұӮе°ҶжҺҘ收зҡ„ж•°жҚ®иҝӣиЎҢз»„еҗҲд»ҘжҹҘжүҫзӣёеә”зҡ„жЁЎејҸ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
и®Ўз®—жңәеҰӮдҪ•жҹҘзңӢиҫ“е…Ҙзҡ„еӣҫеғҸпјҹзңӢзқҖеӣҫзүҮ并解йҮҠе…¶еҗ«д№ү пјҢ иҝҷеҜ№дәҺдәәзұ»жқҘиҜҙеҫҲз®ҖеҚ•зҡ„дёҖ件дәӢжғ… гҖӮ жҲ‘们з”ҹжҙ»еңЁдё–з•ҢдёҠ пјҢ жҲ‘们дҪҝз”ЁиҮӘе·ұзҡ„дё»иҰҒж„ҹи§үеҷЁе®ҳпјҲеҚізңјзқӣпјүжӢҚж‘„зҺҜеўғеҝ«з…§ пјҢ 然еҗҺе°Ҷе…¶дј йҖ’еҲ°и§ҶзҪ‘иҶң гҖӮ иҝҷдёҖеҲҮзңӢиө·жқҘйғҪеҫҲжңүи¶Ј гҖӮ зҺ°еңЁи®©жҲ‘们жғіиұЎдёҖеҸ°и®Ўз®—жңәд№ҹеңЁеҒҡеҗҢж ·зҡ„дәӢжғ… гҖӮ
еңЁи®Ўз®—жңәдёӯ пјҢ дҪҝз”ЁдёҖз»„дҪҚдәҺ0еҲ°255иҢғеӣҙеҶ…зҡ„еғҸзҙ еҖјжқҘи§ЈйҮҠеӣҫеғҸ гҖӮ и®Ўз®—жңәжҹҘзңӢиҝҷдәӣеғҸзҙ еҖје№¶зҗҶи§Је®ғ们 гҖӮ д№ҚдёҖзңӢ пјҢ е®ғ并дёҚзҹҘйҒ“еӣҫеғҸдёӯжңүд»Җд№Ҳзү©дҪ“ пјҢ д№ҹдёҚзҹҘйҒ“е…¶йўңиүІ гҖӮ е®ғеҸӘиғҪиҜҶеҲ«еҮәеғҸзҙ еҖј пјҢ еӣҫеғҸеҜ№дәҺи®Ўз®—жңәжқҘиҜҙе°ұзӣёеҪ“дәҺдёҖз»„еғҸзҙ еҖј гҖӮ д№ӢеҗҺ пјҢ йҖҡиҝҮеҲҶжһҗеғҸзҙ еҖј пјҢ е®ғдјҡж…ўж…ўдәҶи§ЈеӣҫеғҸжҳҜзҒ°еәҰеӣҫиҝҳжҳҜеҪ©иүІеӣҫ гҖӮ зҒ°еәҰеӣҫеҸӘжңүдёҖдёӘйҖҡйҒ“ пјҢ еӣ дёәжҜҸдёӘеғҸзҙ д»ЈиЎЁдёҖз§ҚйўңиүІзҡ„ејәеәҰ гҖӮ 0иЎЁзӨәй»‘иүІ пјҢ 255иЎЁзӨәзҷҪиүІ пјҢ дәҢиҖ…д№Ӣй—ҙзҡ„еҖјиЎЁжҳҺе…¶е®ғзҡ„дёҚеҗҢзӯүзә§зҡ„зҒ°зҒ°иүІ гҖӮ еҪ©иүІеӣҫеғҸжңүдёүдёӘйҖҡйҒ“ пјҢ зәўиүІгҖҒз»ҝиүІе’Ңи“қиүІ пјҢ е®ғ们еҲҶеҲ«д»ЈиЎЁ3з§ҚйўңиүІпјҲдёүз»ҙзҹ©йҳөпјүзҡ„ејәеәҰ пјҢ еҪ“дёүиҖ…зҡ„еҖјеҗҢж—¶еҸҳеҢ–ж—¶ пјҢ е®ғдјҡдә§з”ҹеӨ§йҮҸйўңиүІ пјҢ зұ»дјјдәҺдёҖдёӘи°ғиүІжқҝ гҖӮ д№ӢеҗҺ пјҢ и®Ўз®—жңәиҜҶеҲ«еӣҫеғҸдёӯзү©дҪ“зҡ„жӣІзәҝе’ҢиҪ®е»“ гҖӮгҖӮ
дёӢйқўдҪҝз”ЁPyTorchеҠ иҪҪж•°жҚ®йӣҶ并еңЁеӣҫеғҸдёҠеә”з”ЁиҝҮж»ӨеҷЁпјҡ
# Load the librariesimport torchimport numpy as npfrom torchvision import datasetsimport torchvision.transforms as transforms# Set the parametersnum_workers = 0batch_size = 20# Converting the Images to tensors using Transformstransform = transforms.ToTensor()train_data = http://kandian.youth.cn/index/datasets.MNIST(root='data', train=True, download=True, transform=transform)test_data = http://kandian.youth.cn/index/datasets.MNIST(root='data', train=False, download=True, transform=transform)# Loading the Datatrain_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=num_workers)test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size,num_workers=num_workers)import matplotlib.pyplot as plt%matplotlib inline dataiter = iter(train_loader)images, labels = dataiter.next()images = images.numpy()# Peeking into datasetfig = plt.figure(figsize=(25, 4))for image in np.arange(20): ax = fig.add_subplot(2, 20/2, image+1, xticks=[], yticks=[]) ax.imshow(np.squeeze(images[image]), cmap='gray') ax.set_title(str(labels[image].item())) ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дёӢйқўзңӢзңӢеҰӮдҪ•е°ҶеҚ•дёӘеӣҫеғҸиҫ“е…ҘзҘһз»ҸзҪ‘з»ңдёӯпјҡ
img = np.squeeze(images[7])fig = plt.figure(figsize = (12,12)) ax = fig.add_subplot(111)ax.imshow(img, cmap='gray')width, height = img.shapethresh = img.max()/2.5for x in range(width): for y in range(height): val = round(img[x][y],2) if img[x][y] !=0 else 0 ax.annotate(str(val), xy=(y,x), color='white' if img[x][y]дёҠиҝ°д»Јз Ғе°Ҷж•°еӯ—'3'еӣҫеғҸеҲҶи§ЈдёәеғҸзҙ гҖӮ еңЁдёҖз»„жүӢеҶҷж•°еӯ—дёӯ пјҢ йҡҸжңәйҖүжӢ©вҖң3вҖқ гҖӮ 并且е°Ҷе®һйҷ…еғҸзҙ еҖјпјҲ0-255 пјүж ҮеҮҶеҢ– пјҢ 并е°Ҷе®ғ们йҷҗеҲ¶еңЁ0еҲ°1зҡ„иҢғеӣҙеҶ… гҖӮ еҪ’дёҖеҢ–зҡ„ж“ҚдҪңиғҪеӨҹеҠ еҝ«жЁЎеһӢи®ӯз»ғ收ж•ӣйҖҹеәҰ гҖӮ
жһ„е»әиҝҮж»ӨеҷЁ
гҖҗиҫ“еҮәеұӮ|PyTorchеҸҜи§ҶеҢ–зҗҶи§ЈеҚ·з§ҜзҘһз»ҸзҪ‘з»ңгҖ‘иҝҮж»ӨеҷЁ пјҢ йЎҫеҗҚжҖқд№ү пјҢ е°ұжҳҜиҝҮж»ӨдҝЎжҒҜ гҖӮ еңЁдҪҝз”ЁCNNеӨ„зҗҶеӣҫеғҸж—¶ пјҢ иҝҮж»ӨеғҸзҙ дҝЎжҒҜ гҖӮ дёәд»Җд№ҲйңҖиҰҒиҝҮж»Өе‘ў пјҢ и®Ўз®—жңәеә”иҜҘз»ҸеҺҶзҗҶи§ЈеӣҫеғҸзҡ„еӯҰд№ иҝҮзЁӢ пјҢ иҝҷдёҺеӯ©еӯҗеӯҰд№ иҝҮзЁӢйқһеёёзӣёдјј пјҢ дҪҶеӯҰд№ ж—¶й—ҙдјҡе°‘зҡ„еӨҡ гҖӮ з®ҖиҖҢиЁҖд№Ӣ пјҢ е®ғйҖҡиҝҮд»ҺеӨҙеӯҰд№ пјҢ 然еҗҺд»Һиҫ“е…ҘеұӮдј еҲ°иҫ“еҮәеұӮ гҖӮ еӣ жӯӨ пјҢ зҪ‘з»ңеҝ…йЎ»йҰ–е…ҲзҹҘйҒ“еӣҫеғҸдёӯзҡ„жүҖжңүеҺҹе§ӢйғЁеҲҶ пјҢ еҚіиҫ№зјҳгҖҒиҪ®е»“е’Ңе…¶е®ғдҪҺзә§зү№еҫҒ гҖӮ жЈҖжөӢеҲ°иҝҷдәӣдҪҺзә§зү№еҫҒд№ӢеҗҺ пјҢ дј йҖ’з»ҷеҗҺйқўжӣҙж·ұзҡ„йҡҗи—ҸеұӮ пјҢ жҸҗеҸ–жӣҙй«ҳзә§гҖҒжӣҙжҠҪиұЎзҡ„зү№еҫҒ гҖӮ иҝҮж»ӨеҷЁжҸҗдҫӣдәҶдёҖз§ҚжҸҗеҸ–з”ЁжҲ·йңҖиҰҒзҡ„дҝЎжҒҜзҡ„ж–№ејҸ пјҢ иҖҢдёҚжҳҜзӣІзӣ®ең°дј йҖ’ж•°жҚ® пјҢ еӣ дёәи®Ўз®—жңәдёҚдјҡзҗҶи§ЈеӣҫеғҸзҡ„з»“жһ„ гҖӮ еңЁеҲқе§Ӣжғ…еҶөдёӢ пјҢ еҸҜд»ҘйҖҡиҝҮиҖғиҷ‘зү№е®ҡиҝҮж»ӨеҷЁжқҘжҸҗеҸ–дҪҺзә§зү№еҫҒ пјҢ иҝҷйҮҢзҡ„ж»ӨжіўеҷЁд№ҹжҳҜдёҖз»„еғҸзҙ еҖј пјҢ зұ»дјјдәҺеӣҫеғҸ гҖӮ еҸҜд»ҘзҗҶи§ЈдёәиҝһжҺҘеҚ·з§ҜзҘһз»ҸзҪ‘з»ңдёӯзҡ„жқғйҮҚ гҖӮ иҝҷдәӣжқғйҮҚжҲ–ж»ӨжіўеҷЁдёҺиҫ“е…Ҙзӣёд№ҳд»Ҙеҫ—еҲ°дёӯй—ҙеӣҫеғҸ пјҢ жҸҸз»ҳдәҶи®Ўз®—жңәеҜ№еӣҫеғҸзҡ„йғЁеҲҶзҗҶи§Ј гҖӮ д№ӢеҗҺ пјҢ иҝҷдәӣдёӯй—ҙеұӮиҫ“еҮәе°ҶдёҺеӨҡдёӘиҝҮж»ӨеҷЁзӣёд№ҳд»Ҙжү©еұ•е…¶и§Ҷеӣҫ гҖӮ 然еҗҺжҸҗеҸ–еҲ°дёҖдәӣжҠҪиұЎзҡ„дҝЎжҒҜ пјҢ жҜ”еҰӮдәәи„ёзӯү гҖӮ
жҺЁиҚҗйҳ…иҜ»


















- дёүжҳҹеҸ‘еёғж–°з”өи§Ҷпјҡ99.99%еұҸеҚ жҜ” 8Kиҫ“еҮә
- Facebook Messenger收йӣҶзҡ„ж•°жҚ®йҮҸжңүеӨҡеҗ“дәәпјҹеҸҜи§ҶеҢ–еҜ№жҜ”еӣҫе‘ҠиҜүдҪ
- ж•°жҚ®еҸҜи§ҶеҢ–дёүиҠӮиҜҫд№ӢдәҢпјҡеҸҜи§ҶеҢ–зҡ„дҪҝз”Ё
- еҺҶж—¶ 1 дёӘжңҲпјҢеҒҡдәҶ 10 дёӘ Python еҸҜи§ҶеҢ–еҠЁеӣҫпјҢз”Ёеҝғдё”зІҫзҫҺ...
- е…¬зүӣжҺЁеҮәз”өз«һе……з”өеҷЁпјҢ1A1CеҸҢиҫ“еҮәпјҢйӣҶжҲҗиғҪйҮҸе‘јеҗёзҒҜ
- еңЁLinuxзі»з»ҹдёӯе®үиЈ…ж·ұеәҰеӯҰд№ жЎҶжһ¶Pytorch
- дёәдҪ•еӯҰд№ зј–зЁӢеҫҖеҫҖйғҪжҳҜд»Һзј–еҶҷиҫ“еҮәHelloWorldзҡ„зЁӢеәҸејҖе§Ӣ
- MOMAXжҺЁеҮә20W 1A1C PDе……з”өеҷЁпјҢж”ҜжҢҒеҸҢеҸЈиҫ“еҮә
- ж•°жҚ®|еҚ—ж–№з”өзҪ‘и¶…й«ҳеҺӢе…¬еҸёжҲҗеҠҹдёҫеҠһйҰ–еұҠж•°жҚ®еҸҜи§ҶеҢ–еҲҶжһҗеӨ§иөӣ
- 30иЎҢPythonд»Јз Ғе®һзҺ°3Dж•°жҚ®еҸҜи§ҶеҢ–пјҒйқһеёёжғҠиүі