R语言进行Twitter数据可视化
 文章插图
文章插图
概述对于这个项目 , 我们在2019年5月28-29日通过爬虫来使用Twitter的原始数据 。 此外 , 数据是CSV格式(逗号分隔) 。
它涉及两个主题 , 一个是包含关键字“Joko Widodo”的Joko Widodo的数据 , 另一个是带有关键字“Prabowo Subianto”的Prabowo Subianto的数据 。 其中包括几个变量和信息 , 以确定用户情绪 。 实际上 , 数据有16个变量或属性和1000多个观察值 。 表1列出了一些变量 。
# 导入库library(ggplot2)library(lubridate)# 加载Joko Widodo的数据data.jokowi.df = read.csv(file = 'data-joko-widodo.csv',header = TRUE,sep = ',')senti.jokowi = read.csv(file = 'sentiment-joko-widodo.csv',header = TRUE,sep = ',')# 加载Prabowo Subianto的数据data.prabowo.df = read.csv(file = 'data-prabowo-subianto.csv',header = TRUE,sep = ',')senti.prabowo = read.csv(file = 'sentiment-prabowo-subianto.csv',header = TRUE,sep = ',')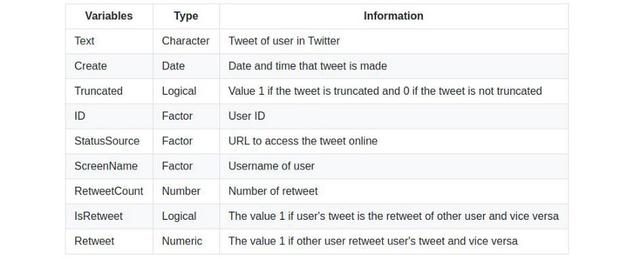 文章插图
文章插图
数据可视化数据探索旨在从Twitter数据中获取任何信息 。 应该指出的是 , 数据已经进行了文本预处理 。 我们对那些被认为是很有趣的变量进行探索 。。
# TWEETS的条形图-JOKO WIDODOdata.jokowi.df$created = ymd_hms(data.jokowi.df$created,tz = 'Asia/Jakarta')# 另一种制作“date”和“hour”变量的方法data.jokowi.df$date = date(data.jokowi.df$created)data.jokowi.df$hour = hour(data.jokowi.df$created)# 日期2019-05-29data.jokowi.date1 = subset(x = data.jokowi.df,date == '2019-05-29')data.hour.date1 = data.frame(table(data.jokowi.date1$hour))colnames(data.hour.date1) = c('Hour','Total.Tweets')# 创建数据可视化ggplot(data.hour.date1)+geom_bar(aes(x = Hour,y = Total.Tweets,fill = I('blue')),stat = 'identity',alpha = 0.75,show.legend = FALSE)+geom_hline(yintercept = mean(data.hour.date1$Total.Tweets),col = I('black'),size = 1)+geom_text(aes(fontface = 'italic',label = paste('Average:',ceiling(mean(data.hour.date1$Total.Tweets)),'Tweets per hour'),x = 8,y = mean(data.hour.date1$Total.Tweets)+20),hjust = 'left',size = 4)+labs(title = 'Total Tweets per Hours - Joko Widodo',subtitle = '28 May 2019',caption = 'Twitter Crawling 28 - 29 May 2019')+xlab('Time of Day')+ylab('Total Tweets')+scale_fill_brewer(palette = 'Dark2')+theme_bw()# TWEETS的条形图-PRABOWO SUBIANTOdata.prabowo.df$created = ymd_hms(data.prabowo.df$created,tz = 'Asia/Jakarta')# 另一种制作“date”和“hour”变量的方法data.prabowo.df$date = date(data.prabowo.df$created)data.prabowo.df$hour = hour(data.prabowo.df$created)# 日期2019-05-28data.prabowo.date1 = subset(x = data.prabowo.df,date == '2019-05-28')data.hour.date1 = data.frame(table(data.prabowo.date1$hour))colnames(data.hour.date1) = c('Hour','Total.Tweets')# 日期 2019-05-29data.prabowo.date2 = subset(x = data.prabowo.df,date == '2019-05-29')data.hour.date2 = data.frame(table(data.prabowo.date2$hour))colnames(data.hour.date2) = c('Hour','Total.Tweets')data.hour.date3 = rbind(data.hour.date1,data.hour.date2)data.hour.date3$Date = c(rep(x = '2019-05-28',len = nrow(data.hour.date1)),rep(x = '2019-05-29',len = nrow(data.hour.date2)))data.hour.date3$Labels = c(letters,'A','B')data.hour.date3$Hour = as.character(data.hour.date3$Hour)data.hour.date3$Hour = as.numeric(data.hour.date3$Hour)# 数据预处理for (i in 1:nrow(data.hour.date3)) {if (i%%2 == 0) {data.hour.date3[i,'Hour'] = ''}if (i%%2 == 1) {data.hour.date3[i,'Hour'] = data.hour.date3[i,'Hour']}}data.hour.date3$Hour = as.factor(data.hour.date3$Hour)# 数据可视化ggplot(data.hour.date3)+geom_bar(aes(x = Labels,y = Total.Tweets,fill = Date),stat = 'identity',alpha = 0.75,show.legend = TRUE)+geom_hline(yintercept = mean(data.hour.date3$Total.Tweets),col = I('black'),size = 1)+geom_text(aes(fontface = 'italic',label = paste('Average:',ceiling(mean(data.hour.date3$Total.Tweets)),'Tweets per hour'),x = 5,y = mean(data.hour.date3$Total.Tweets)+6),hjust = 'left',size = 3.8)+scale_x_discrete(limits = data.hour.date3$Labels,labels = data.hour.date3$Hour)+labs(title = 'Total Tweets per Hours - Prabowo Subianto',subtitle = '28 - 29 May 2019',caption = 'Twitter Crawling 28 - 29 May 2019')+xlab('Time of Day')+ylab('Total Tweets')+ylim(c(0,100))+theme_bw()+theme(legend.position = 'bottom',legend.title = element_blank())+scale_fill_brewer(palette = 'Dark2')
推荐阅读


















- 大一非计算机专业的学生,如何利用寒假自学C语言
- 微软|外媒:微软将对Windows 10界面进行彻底改进 已招兵买马
- Linux 5.11开始围绕PCI Express 6.0进行早期准备
- AMP Robotics募资5500万美元 开发AI对可回收物进行分拣
- Mozilla正在对Firefox设计进行更新工作
- 为什么我喜欢C语言,却非常讨厌C++?一位国外程序员的回答
- iPhone 13仍将有四款型号 Pro版屏幕进行重大升级
- 谷歌对内部论文进行“敏感问题”审查!讲坏话的不许发
- Java语言会不会随着容器的兴起而衰落
- 大数据专业本科生选择主攻Python语言,如何提升就业竞争力