йқўиҜ•е®ҳпјҡиҒҠиҒҠ etcd дёӯзҡ„ Raft еҗ§
Raftпјҡ(computer_science "Raft") жҳҜиҝ‘е№ҙжқҘжҜ”иҫғжөҒиЎҢзҡ„дёҖдёӘдёҖиҮҙжҖ§з®—жі• гҖӮ е®ғзҡ„еҺҹзҗҶжҜ”иҫғе®№жҳ“зҗҶи§Ј пјҢ зҪ‘дёҠд№ҹжңүеҫҲеӨҡзӣёе…ізҡ„д»Ӣз»Қ пјҢ еӣ жӯӨиҝҷйҮҢжҲ‘е°ұдёҚеҶҚе•°е—ҰеҺҹзҗҶдәҶ пјҢ иҖҢжҳҜжү“з®—д»Ҙ raft еңЁ etcd дёӯзҡ„е®һзҺ°1[1]дёәдҫӢ пјҢ д»Һе·ҘзЁӢзҡ„и§’еәҰжқҘи®Іи®ІиҝҷдёӘз®—жі•зҡ„дёҖдёӘе…·дҪ“е®һзҺ° пјҢ жҜ•з«ҹдәҶи§ЈеҺҹзҗҶеҸӘз®—жҳҜвҖңзәёдёҠи°Ҳе…өвҖқ пјҢ зҰ»зңҹжӯЈиғҪжҠҠе®ғеә”з”Ёиө·жқҘиҝҳжңүеҫҲй•ҝдёҖж®өи·қзҰ» гҖӮ
еҰӮжһңдҪ иҝҳдёҚзҶҹжӮү raft пјҢ иҝҷдёӘз»Ҹе…ёзҡ„еҠЁз”»жј”зӨә[2]гҖҒе®ғзҡ„и®әж–Ү[3]д»ҘеҸҠиҝҷдёӘ lecture[4]еҸҜиғҪдјҡеҜ№дҪ жңүеё®еҠ© гҖӮ жҲ–иҖ…дҪ д№ҹеҸҜд»ҘзӣҙжҺҘи§ӮзңӢдёӢйқўзҡ„и§Ҷйў‘ пјҢ иҝҷжҳҜжҲ‘дҪңзҡ„дёҖж¬ЎжҠҖжңҜеҲҶдә« пјҢ и®Ізҡ„жҳҜetcd дёӯ raft жЁЎеқ—зҡ„жәҗз Ғи§Јжһҗ[5] гҖӮ иҜҙеҸҘйўҳеӨ–иҜқ пјҢ еҫҲеӨҡ Conference е’Ң Meetup йғҪдјҡжҠҠи§Ҷйў‘еҪ•еғҸдёҠдј еҲ° YouTube дёҠ пјҢ YouTube з®Җзӣҙе°ұжҳҜзЁӢеәҸе‘ҳзҡ„иЎЈжҹң пјҢ жҜҸйҖӣдёҖж¬ЎйғҪжңү新收иҺ· гҖӮ пјҲж–№дҫҝж’ӯж”ҫ пјҢ ж”ҫдёҖдёӘ B з«ҷй“ҫжҺҘпјү
OverviewгҖҗйқўиҜ•е®ҳпјҡиҒҠиҒҠ etcd дёӯзҡ„ Raft еҗ§гҖ‘Etcd е°Ҷ raft еҚҸи®®е®һзҺ°дёәдёҖдёӘ library пјҢ 然еҗҺжң¬иә«дҪңдёәдёҖдёӘеә”з”ЁдҪҝз”Ёе®ғ гҖӮ еҪ“然 пјҢ еҸҜиғҪжҳҜдёәдәҶжҺЁе№ҝе®ғжүҖе®һзҺ°зҡ„иҝҷдёӘ library пјҢ etcd иҝҳйўқеӨ–жҸҗдҫӣдәҶдёҖдёӘеҸ«raftexample[6] зҡ„зӨәдҫӢзЁӢеәҸ пјҢ еҗ‘з”ЁжҲ·еұ•зӨәжҖҺж ·еңЁе®ғжүҖжҸҗдҫӣзҡ„ raft library зҡ„еҹәзЎҖдёҠжһ„е»әеҮәдёҖдёӘеҲҶеёғејҸзҡ„ KV еӯҳеӮЁеј•ж“Һ гҖӮ
еңЁ etcd дёӯ пјҢ raft дҪңдёәеә•еұӮзҡ„е…ұиҜҶжЁЎеқ— пјҢ иҝҗиЎҢеңЁдёҖдёӘgoroutineйҮҢ пјҢ йҖҡиҝҮchannelжҺҘеҸ—дёҠеұӮпјҲetcdserverпјүдј жқҘзҡ„ж¶ҲжҒҜ пјҢ 并е°ҶеӨ„зҗҶеҗҺзҡ„з»“жһңйҖҡиҝҮеҸҰдёҖдёӘchannelиҝ”еӣһз»ҷдёҠеұӮеә”з”Ё пјҢ 他们зҡ„дәӨдә’иҝҮзЁӢеӨ§жҰӮжҳҜиҝҷж ·зҡ„пјҡ
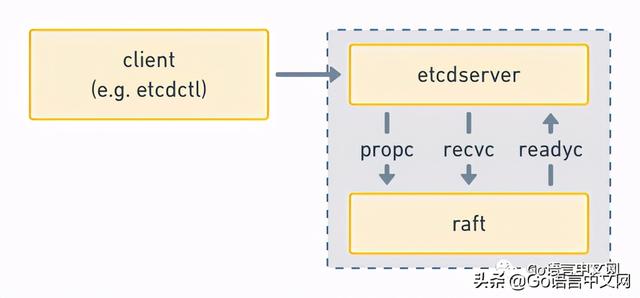 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
Raft Stack
иҝҷз§Қе…ЁејӮжӯҘзҡ„дәӨдә’ж–№ејҸеҘҪеӨ„е°ұжҳҜе®ғжҸҗй«ҳдәҶжҖ§иғҪ пјҢ дҪҶеқҸеӨ„е°ұжҳҜйҡҫд»Ҙи°ғиҜ• пјҢ д»Јз ҒзңӢиө·жқҘдјҡеҫҲз»• гҖӮ жӢҝ etcd дёҫдҫӢ пјҢ еҫҲеӨҡж—¶еҖҷдҪ еҸӘзңӢеҲ°е®ғжҠҠдёҖдёӘж¶ҲжҒҜ push еҲ°дёҖдёӘ slice/channel йҮҢйқў пјҢ 然еҗҺиҝҷйғЁеҲҶеҮҪж•°и°ғз”Ёй“ҫе°ұз»“жқҹдәҶ пјҢ дҪ ж— жі•зӣҙи§Ӯзҡ„иҝҪиёӘеҲ° пјҢ еҲ°еә•жҳҜи°ҒжңҖеҗҺеӨ„зҗҶдәҶиҝҷдёӘж¶ҲжҒҜ гҖӮ
Code BreakdownжҲ‘们жқҘзңӢдёҖдёӢиҝҷдёӘ raft library йҮҢйқўйғҪжңүе“Әдәӣж–Ү件пјҡ
$ tree --dirsfirst -L 1 -I '*test*' -P '*.go'.в”ңв”Җв”Җ raftpbв”ңв”Җв”Җ doc.goв”ңв”Җв”Җ log.goв”ңв”Җв”Җ log_unstable.goв”ңв”Җв”Җ logger.goв”ңв”Җв”Җ node.goв”ңв”Җв”Җ progress.goв”ңв”Җв”Җ raft.goв”ңв”Җв”Җ rawnode.goв”ңв”Җв”Җ read_only.goв”ңв”Җв”Җ status.goв”ңв”Җв”Җ storage.goв””в”Җв”Җ util.goдёӢйқўжҢүеҠҹиғҪжЁЎеқ—дҫқж¬Ўд»Ӣз»Қпјҡ
raftpbRaft дёӯзҡ„еәҸеҲ—еҢ–жҳҜеҖҹеҠ©дәҺProtocol Buffer[7]жқҘе®һзҺ°зҡ„ пјҢ иҝҷдёӘж–Ү件еӨ№е°ұе®ҡд№үдәҶйңҖиҰҒеәҸеҲ—еҢ–зҡ„еҮ дёӘж•°жҚ®з»“жһ„ пјҢ жҲ‘们е…Ҳд»ҺEntryе’ҢMessageејҖе§ӢзңӢиө·пјҡ
Entryд»Һж•ҙдҪ“дёҠжқҘиҜҙ пјҢ дёҖдёӘйӣҶзҫӨдёӯзҡ„жҜҸдёӘиҠӮзӮ№йғҪжҳҜдёҖдёӘзҠ¶жҖҒжңә пјҢ иҖҢ raft з®ЎзҗҶзҡ„е°ұжҳҜеҜ№иҝҷдёӘзҠ¶жҖҒжңәиҝӣиЎҢжӣҙж”№зҡ„дёҖдәӣж“ҚдҪң пјҢ иҝҷдәӣж“ҚдҪңеңЁд»Јз Ғдёӯиў«е°ҒиЈ…дёәдёҖдёӘдёӘEntry гҖӮ
// #L203type Entry struct {Termuint64Indexuint64TypeEntryTypeData[]byte}
- TermпјҡйҖүдёҫд»»жңҹ пјҢ жҜҸж¬ЎйҖүдёҫд№ӢеҗҺйҖ’еўһ 1 гҖӮ е®ғзҡ„дё»иҰҒдҪңз”ЁжҳҜж Үи®°дҝЎжҒҜзҡ„ж—¶ж•ҲжҖ§ пјҢ жҜ”ж–№иҜҙеҪ“дёҖдёӘиҠӮзӮ№еҸ‘еҮәжқҘзҡ„ж¶ҲжҒҜдёӯжҗәеёҰзҡ„ term жҳҜ 2 пјҢ иҖҢеҸҰдёҖдёӘиҠӮзӮ№жҗәеёҰзҡ„ term жҳҜ 3 пјҢ йӮЈжҲ‘们е°ұи®Өдёә第дёҖдёӘиҠӮзӮ№зҡ„дҝЎжҒҜиҝҮж—¶дәҶ гҖӮ
- IndexпјҡеҪ“еүҚиҝҷдёӘ entry еңЁж•ҙдёӘ raft ж—Ҙеҝ—дёӯзҡ„дҪҚзҪ®зҙўеј• гҖӮ жңүдәҶTermе’ҢIndexд№ӢеҗҺ пјҢ дёҖдёӘ log entry е°ұиғҪиў«е”ҜдёҖж ҮиҜҶ гҖӮ
- TypeпјҡеҪ“еүҚ entry зҡ„зұ»еһӢ пјҢ зӣ®еүҚ etcd ж”ҜжҢҒдёӨз§Қзұ»еһӢпјҡEntryNormal[8]е’ҢEntryConfChange[9] пјҢ EntryNormal д»ЈиЎЁеҪ“еүҚ Entry жҳҜеҜ№зҠ¶жҖҒжңәзҡ„ж“ҚдҪң пјҢ EntryConfChange еҲҷд»ЈиЎЁеҜ№еҪ“еүҚйӣҶзҫӨй…ҚзҪ®иҝӣиЎҢжӣҙж”№зҡ„ж“ҚдҪң пјҢ жҜ”еҰӮеўһеҠ жҲ–иҖ…еҮҸе°‘иҠӮзӮ№ гҖӮ
- DataпјҡдёҖдёӘиў«еәҸеҲ—еҢ–еҗҺзҡ„ byte ж•°з»„ пјҢ д»ЈиЎЁеҪ“еүҚ entry зңҹжӯЈиҰҒжү§иЎҢзҡ„ж“ҚдҪң пјҢ жҜ”ж–№иҜҙеҰӮжһңдёҠйқўзҡ„TypeжҳҜEntryNormal пјҢ йӮЈиҝҷйҮҢзҡ„ Data е°ұеҸҜиғҪжҳҜе…·дҪ“иҰҒжӣҙж”№зҡ„ key-value pair пјҢ еҰӮжһңTypeжҳҜEntryConfChange пјҢ йӮЈ Data е°ұжҳҜе…·дҪ“зҡ„й…ҚзҪ®жӣҙж”№йЎ№ConfChange[10] гҖӮ raft з®—жі•жң¬иә«е№¶дёҚе…іеҝғиҝҷдёӘж•°жҚ®жҳҜд»Җд№Ҳ пјҢ е®ғеҸӘжҳҜжҠҠиҝҷж®өж•°жҚ®еҪ“еҒҡ log еҗҢжӯҘиҝҮзЁӢдёӯзҡ„ payload жқҘеӨ„зҗҶ пјҢ е…·дҪ“еҜ№иҝҷдёӘж•°жҚ®зҡ„и§ЈжһҗеҲҷжңүдёҠеұӮеә”з”ЁжқҘе®ҢжҲҗ гҖӮ
жҺЁиҚҗйҳ…иҜ»
- иҒҠиҒҠзҪ‘жҳ“дә‘йҹід№җпјҡвҖңеҝғеҠЁжЁЎејҸвҖқ
- еҚҺдёәзӘҒ然宣еёғпјҒи…ҫи®Ҝд№ҹжІЎжңүжғіеҲ°пјҢдёҖеҲҮжқҘеҫ—еҰӮжӯӨеҝ«
- е…ЁзҗғжңҖеҸ—ж¬ўиҝҺзҡ„4йғЁ5GжүӢжңәпјҡйқ йҮҸеҸ–иғңзҡ„е°Ҹзұіз«ҹжҰңдёҠж— еҗҚпјҹ
- JavaеӯҰд№ пјҡJavaеӯҰд№ еҲ°д»Җд№ҲзЁӢеәҰеҸҜд»ҘиҝӣиЎҢйқўиҜ•
- зЁӢеәҸе‘ҳйқўиҜ•йҮ‘е…ё17.05_go_еӯ—жҜҚдёҺж•°еӯ—
- е®үеҚ“жҳҘжӢӣйқўз»ҸпјҡдәҢжң¬жёЈйҷўйқўиҜ•зҪ‘жҳ“иў«жӢ’пјҢжңҖз»ҲиҺ·и…ҫи®ҜйҳҝйҮҢoffer
- дёӯеӣҪжңҖиөҡй’ұзҡ„е…¬еҸёиҜһз”ҹпјҒдёҚжҳҜ移еҠЁпјҢд№ҹдёҚжҳҜйҳҝйҮҢе·ҙе·ҙпјҢйӮЈз¬¬дёҖжҳҜпјҹ
- гҖҢ6гҖҚиҝӣеӨ§еҺӮеҝ…йЎ»жҺҢжҸЎзҡ„йқўиҜ•йўҳ-Hibernate
- й«ҳйҖҡйӘҒйҫҷ888жҸҗеүҚжқҘдәҶпјҒеҚҺдёәвҖңж…ҢвҖқдәҶпјҹдҪҶдёҖеҲҮиҝҳжІЎжңүе®ҡи®ә
- йңҮжғҠпјҒдә¬дёңT4еӨ§дҪ¬йқўиҜ•ж•ҙж•ҙдёүдёӘжңҲпјҢжүҚеҶҷдәҶдёӨд»ҪjavaйқўиҜ•з¬”и®°