BGLLзӨҫеӣўеҲ’еҲҶпҪңDBSCANеҜҶеәҰиҒҡзұ»пҪңPythonеӨҚжқӮзҪ‘з»ң
BGLLзӨҫеӣўеҲ’еҲҶжЎҲдҫӢеҲҶжһҗе…·жңүеӨҚжқӮзӣёдә’дҪңз”Ёзҡ„еӨ§йҮҸдёӘдҪ“зі»з»ҹ пјҢ еӨҚжқӮзҪ‘з»ңжҳҜеёёз”Ёзҡ„е·Ҙе…· гҖӮ еӨ§еӨҡж•°еӨҚжқӮзҪ‘з»ңе‘ҲзҺ°зӨҫеӣўз»“жһ„ пјҢ еҚіиҠӮзӮ№з»„з»ҮжҲҗзҙ§еҜҶзӣёиҝһзҡ„зҫӨз»„ пјҢ еңЁеҗҢдёҖдёӘзҫӨз»„еҶ…зҡ„иҠӮзӮ№иҝһжҺҘзӣёеҜ№зҙ§еҜҶ пјҢ иҖҢдёҚеҗҢзҫӨз»„й—ҙзҡ„иҠӮзӮ№иҝһжҺҘзӣёеҜ№зЁҖз–Ҹ гҖӮ дёҖдёӘзҫӨз»„йҖҡеёёеҜ№еә”зқҖдёҖдёӘеҠҹиғҪеҚ•е…ғ пјҢ дҫӢеҰӮд»Ји°ўзҪ‘еҗҢдёҖзҫӨз»„еҶ…зҡ„д»Ји°ўзү©еҸҜиғҪе®һзҺ°зҡ„жҳҜеҗҢдёҖеҠҹиғҪ гҖӮ еӣ жӯӨеӨҚжқӮзҪ‘з»ңзҡ„зӨҫеӣўеҲ’еҲҶеҸҜд»ҘеӨ§еӨ§з®ҖеҢ–еӨҚжқӮзі»з»ҹзҡ„еҠҹиғҪеҲҶжһҗ пјҢ еңЁиҚҜзү©еҠҹиғҪеҲҶжһҗгҖҒе•Ҷе“ҒжҺЁиҚҗгҖҒзҪ‘з»ңеҜјиҲӘгҖҒдёҮз»ҙзҪ‘з»“жһ„и®ҫи®Ўзӯүжңүе№ҝжіӣеә”з”Ё гҖӮ
ж•°жҚ®жҸҸиҝ°пјҡ
network.txtдёәж— еҗ‘зҪ‘з»ң пјҢ жІЎжңүиҮӘиҫ№жҲ–иҖ…йҮҚиҫ№,зҪ‘з»ңиҠӮзӮ№ж•°115 пјҢ иҠӮзӮ№д»Һ1ејҖе§Ӣзј–еҸ· гҖӮ жҜҸдёҖиЎҢдёәдёҖдёӘдәҢе…ғз»„ пјҢ дәҢе…ғз»„зҡ„дёӨдёӘж•°иЎЁзӨәдёӨдёӘиҠӮзӮ№й—ҙжңүж— еҗ‘иҫ№зӣёиҝһ гҖӮ
й—®йўҳпјҡ
иҜ·е°ҶиҜҘзҪ‘з»ңеҲ’еҲҶдёәдҪ и®ӨдёәеҗҲйҖӮзҡ„зӨҫеӣўж•°зӣ® гҖӮ
жҸҗдәӨз»“жһңпјҡ
иҜ·еңЁжӯЈж–Ү(з»“жһңжұҮжҖ».pdf)дёӯиҜҰз»ҶжҸҸиҝ°и§Јзӯ”иҝҮзЁӢ пјҢ еҢ…жӢ¬и§ЈйўҳжҖқи·Ҝ пјҢ з®—жі• пјҢ еҸҠеҲҶжһҗеҲ’еҲҶзҡ„з»“жһң пјҢ 并жҸҗдәӨд»ҘдёӢ2дёӘйҷ„еҪ•ж–Ү件пјҡ
1. д»Јз Ғпјӣ
2. зҪ‘з»ңзҡ„еҲ’еҲҶз»“жһң,з”ЁCommunity_Detection.csvе‘ҪеҗҚ пјҢ ж јејҸеҰӮдёӢпјҡ
(иҠӮзӮ№1 жүҖеұһзӨҫеӣўзј–еҸ·i)
(иҠӮзӮ№2 жүҖеұһзӨҫеӣўзј–еҸ·j)
зӨҫеӣўзј–еҸ·д»Һ1ејҖе§Ӣ
ж•°жҚ®еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
зӨҫеӣўеҲ’еҲҶ
1. зӨҫеӣўеҲ’еҲҶйў„еӨҮзҹҘиҜҶ
дёҖдёӘеӣҫйҖҡеёёиЎЁзӨәдёәG=(V,E) пјҢ е…¶дёӯVиЎЁзӨәзӮ№йӣҶеҗҲ пјҢ EиЎЁзӨәиҫ№йӣҶеҗҲ пјҢ йҖҡеёёжҲ‘们用nиЎЁзӨәеӣҫзҡ„иҠӮзӮ№ж•° пјҢ mиЎЁзӨәиҫ№ж•° гҖӮ дёҖдёӘеӣҫдёӯ пјҢ дёҺдёҖдёӘзӮ№зҡ„зӣёе…іиҒ”зҡ„иҫ№зҡ„ж•°йҮҸз§°дёәиҜҘзӮ№зҡ„еәҰ гҖӮ еҜ№дәҺдёҖдёӘеӣҫ пјҢ еӣҫдёӯжүҖжңүзӮ№зҡ„еәҰзҡ„е’ҢжҒ°еҘҪзӯүдәҺиҫ№ж•°зҡ„дёӨеҖҚ гҖӮ еӣҫйҖҡеёёз”ЁйӮ»жҺҘзҹ©йҳөAиЎЁзӨә пјҢ йӮ»жҺҘзҹ©йҳөзҡ„(i,j)дҪҚзҪ®е…ғзҙ жҳҜ1иЎЁзӨәзӮ№iеҲ°зӮ№jеҸіиҫ№ пјҢ 0иЎЁзӨәж— иҫ№ гҖӮжң¬ж–ҮдёӯжҲ‘们дјҡз”ЁеҲ°йҡҸжңәеӣҫзҡ„жҰӮеҝө пјҢ жүҖи°“йҡҸжңәеӣҫ пјҢ е°ұжҳҜжҢҮдёҖдёӘеӣҫдёӯд»»дҪ•дёӨдёӘзӮ№д№Ӣй—ҙиҝһиҫ№зҡ„жҰӮзҺҮзӣёзӯү гҖӮ йҰ–е…ҲзЎ®е®ҡnдёӘзӮ№ пјҢ 然еҗҺд»Ҙеӣәе®ҡжҰӮзҺҮpеҺ»з»ҷеӣҫдёӯзҡ„дёҖеҜ№йЎ¶зӮ№иҝһиҫ№ пјҢ е°ұеҪўжҲҗдәҶдёҖдёӘйҡҸжңәеӣҫ гҖӮ еңЁз ”究дёӯ,йҡҸжңәеӣҫйҖҡеёёз”ЁжқҘдҪңдёәдёҖдёӘз©әжЁЎеһӢжқҘдёҺе®һйҷ…зҪ‘з»ңиҝӣиЎҢжҜ”иҫғ пјҢ д»ҺиҖҢеҫ—еҮәдёҖдәӣжҖ§иҙЁз»“и®ә гҖӮз ”з©¶зӨҫеӣўзҡ„еҲ’еҲҶ пјҢ дёҖдёӘйңҖиҰҒи§ЈеҶізҡ„й—®йўҳжҳҜ пјҢ еҰӮдҪ•жқҘиЎЎйҮҸдёҖдёӘзӨҫеӣўзҡ„еҲ’еҲҶзҡ„еҘҪеқҸпјҹдёҖдёӘжҜ”иҫғз®ҖеҚ•зӣҙи§Ӯзҡ„еҺҹеҲҷжҳҜдҪҝеҫ—зӨҫеҢәеҶ…йғЁзҡ„иҫ№е°ҪеҸҜиғҪең°еӨҡ пјҢ зӨҫеҢәд№Ӣй—ҙзҡ„иҫ№й—ҙеҸҜиғҪең°е°‘ гҖӮ еҸҰеӨ–дёҖдёӘзЁҚеҫ®еӨҚжқӮзӮ№дҪҶжҳҜжӣҙдёәеёёз”Ёзҡ„еәҰйҮҸжҳҜNewmanзӯүдәәжҸҗеҮәзҡ„жЁЎеқ—еәҰ(modularity)зҡ„жҰӮеҝө пјҢ еҹәжң¬зҡ„жғіжі•жҳҜиҝҷж ·зҡ„пјҡжҲ‘们еҒҮи®ҫеңЁйҡҸжңәеӣҫдёӯжҳҜдёҚеӯҳеңЁиҝҷз§ҚзӨҫеӣўз»“жһ„зҡ„ пјҢ е°Ҷе®һйҷ…зҪ‘з»ңи·ҹе…¶зӣёеә”зҡ„йҡҸжңәзҪ‘з»ңиҝӣиЎҢжҜ”иҫғ пјҢ еҰӮжһңдёҖдёӘзҪ‘з»ңи·ҹйҡҸжңәзҪ‘з»ңд№Ӣй—ҙзҡ„е·®ејӮи¶ҠеӨ§ пјҢ иЎЁзӨәзӨҫеӣўз»“жһ„и¶ҠжҳҺжҳҫ гҖӮ иҝҷж · пјҢ жҲ‘们еҜ№еҲ’еҲҶеҗҺзҡ„жҜҸдёҖдёӘеӯҗзҪ‘з»ңи®Ўз®—дёҖдёӘвҖңеҜҶеәҰвҖқ пјҢ 然еҗҺи®Ўз®—иҜҘеӯҗзҪ‘з»ңйҡҸжңәжғ…еҶөдёӢзҡ„вҖңеҜҶеәҰвҖқ пјҢ иҝҷдёӨдёӘвҖңеҜҶеәҰвҖқеӯҳеңЁдёҖдёӘе·®еҖј пјҢ иЎЁзӨәдәҶиҜҘеӯҗзҪ‘з»ңеҒҸзҰ»йҡҸжңәжғ…еҶөзҡ„дёҖз§ҚзЁӢеәҰ пјҢ 并且иҝҷдёӘеҖји¶ҠеӨ§иЎЁзӨәиҝҷдёӘеӯҗзҪ‘з»ңзӣёеҜ№йҡҸжңәзҪ‘з»ңи¶ҠзЁ еҜҶ гҖӮ дёҖдёӘзҪ‘з»ңдёӯеҢ…еҗ«зҡ„жүҖжңүеӯҗзҪ‘з»ңзҡ„иҝҷдёӘе·®еҖјеҠ еҲ°дёҖиө·зҡ„е’Ңе°ұжҳҜиҝҷдёӘеӨҚжқӮзҪ‘з»ңзҡ„жЁЎеқ—еәҰ пјҢ ж•°еӯҰе…¬ејҸиЎЁзӨәеҰӮдёӢпјҡ
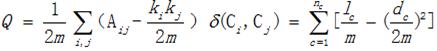 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…¶дёӯAijиЎЁзӨәеӣҫзҡ„йӮ»жҺҘзҹ©йҳө пјҢ ki иЎЁзӨәзӮ№i зҡ„еәҰ пјҢ mжҳҜеӣҫзҡ„иҫ№ж•° пјҢ ki*kj/2mиЎЁзӨәзӮ№ i е’ҢзӮ№ jд№Ӣй—ҙиҫ№зҡ„жңҹжңӣ гҖӮ иҝӣдёҖжӯҘе°ҶжЁЎеқ—еәҰеҸҜд»ҘеҢ–дёәзӯүејҸеҸіиҫ№зҡ„еҪўејҸ пјҢ ncжҳҜзӨҫеӣўзҡ„жҖ»дёӘж•° пјҢ lcжҳҜзӨҫеӣўcеҶ…зҡ„иҫ№ж•° пјҢ dcжҳҜзӨҫеӣўеҶ…зҡ„зӮ№зҡ„еәҰж•°д№Ӣе’Ң (note: зӨҫеӣўеҶ…зҡ„жҜҸдёҖдёӘзӮ№еҸҜиғҪи·ҹжң¬зӨҫеӣўеҶ…йғЁзҡ„зӮ№жңүиҫ№ пјҢ д№ҹеҸҜиғҪжңүи·ҹе…¶д»–зӨҫеӣўзӮ№иҝһиҫ№ пјҢ ж•…йҖҡеёё dc> lc)
2. BGLLз®—жі•
BGLLз®—жі•е°ұеұһдәҺеҹәдәҺжЁЎеқ—еәҰдјҳеҢ–дёӯзҡ„иҒҡеҗҲзұ»з®—жі• пјҢ иҮӘеә•еҗ‘дёҠзҡ„дёҚж–ӯиҒҡеҗҲ гҖӮ
BGLLз®—жі•дё»иҰҒеҲҶдёәдёӨжӯҘ:
第дёҖжӯҘпјҡеҒҮи®ҫзҪ‘з»ңдёӯжңүNдёӘиҠӮзӮ№ пјҢ йҰ–е…ҲжҲ‘们з»ҷжҜҸдёӘиҠӮзӮ№еҲҶй…ҚдёҖдёӘзӨҫеҢә пјҢ жүҖд»ҘеҲқе§Ӣйҳ¶ж®өжңүеӨҡе°‘дёӘиҠӮзӮ№е°ұжңүеӨҡе°‘дёӘзӨҫеҢә гҖӮ 然еҗҺ пјҢ еҜ№дәҺзҪ‘з»ңдёӯжҜҸдёӘиҠӮзӮ№i,жҲ‘们иҖғиҷ‘д»–жүҖжңүзҡ„йӮ»еұ…иҠӮзӮ№j,жҲ‘们иҜ„дј°еҪ“жҠҠиҠӮзӮ№iд»Һе®ғжүҖеңЁзҡ„зӨҫеҢә移еҠЁеҲ°е…¶йӮ»еұ…jжүҖеңЁзҡ„зӨҫеҢәж—¶ пјҢ жЁЎеқ—еәҰзҡ„еўһйҮҸеҸҳеҢ– пјҢ жҲ‘们жҠҠиҠӮзӮ№i移еҠЁеҲ°дҪҝжЁЎеқ—еәҰеўһеҠ жңҖеӨ§зҡ„иҠӮзӮ№jжүҖеңЁзҡ„зӨҫеҢә гҖӮ еҰӮжһңжүҖжңүи®Ўз®—еҮәжқҘзҡ„еўһзӣҠйғҪдёҚжҳҜжӯЈж•° пјҢ еҲҷе°ҶиҜҘиҠӮзӮ№д»ҚеӨ„дәҺеҺҹзӨҫеҢәдёӯ гҖӮ иҜҘиҝҮзЁӢеҜ№жүҖжңүзҡ„иҠӮзӮ№йҮҚеӨҚ并且жҢүйЎәеәҸеә”з”Ё пјҢ зӣҙеҲ°жІЎжңүиҠӮзӮ№з§»еҠЁ пјҢ еҲҷ第дёҖдёӘиҝҮзЁӢеҒңжӯў пјҢ д№ҹе°ұжҳҜд»»дҪ•дёҖдёӘиҠӮзӮ№зҡ„移еҠЁйғҪдёҚдјҡеҜјиҮҙжЁЎеқ—еәҰзҡ„еўһеҠ гҖӮ д»ҺиҜҘиҝҮзЁӢеҸҜд»ҘиӮҜе®ҡ пјҢ жңүдәӣиҠӮзӮ№дјҡиў«дёҚжӯўдёҖж¬Ўзҡ„иҖғиҷ‘еҲ° гҖӮ еҪ“然иҠӮзӮ№иҖғиҷ‘йЎәеәҸеҜ№з®—жі•жңҖеҗҺзҡ„иҫ“еҮәд№ҹжҳҜжңүеҪұе“Қзҡ„ пјҢ дҪҶжҳҜжңҖеҗҺеҜ№жңҖеҗҺжүҖеҲ’еҲҶзҡ„зӨҫеҢәзҡ„жЁЎеқ—еәҰеҪұе“ҚдёҚеӨ§ гҖӮ дҪҶжҳҜиҠӮзӮ№зҡ„жҺ’еәҸйЎәеәҸжҳҜеҸҜд»ҘеҪұе“Қз®—жі•зҡ„иҝҗиЎҢж—¶й—ҙзҡ„ гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- вҖң8+вҖқвҖң12+вҖқвҖң16+вҖқдёүжЎЈпјҢдёӯеӣҪжёёжҲҸеҲҶзә§ж ҮеҮҶд»Ҙе№ҙйҫ„еҲ’еҲҶпјҒгҖҠзҪ‘з»ңжёёжҲҸйҖӮйҫ„жҸҗзӨәгҖӢеҸ‘еёғ
- Marine and Petroleum GeologyпјҡеҹәдәҺжңәеҷЁеӯҰд№ зҡ„ж·ұеұӮзўій…ёзӣҗеІ©зҡ„жөӢдә•зӣёеҲ’еҲҶ
- дәҶи§Јжғ…з»ӘеҲ’еҲҶпјҡеҰӮдҪ•дҪҝз”ЁжңәеҷЁеӯҰд№ жқҘдҝқжҢҒз§ҜжһҒеҝғжҖҒпјҹ