дәҶи§Јжғ…з»ӘеҲ’еҲҶпјҡеҰӮдҪ•дҪҝз”ЁжңәеҷЁеӯҰд№ жқҘдҝқжҢҒз§ҜжһҒеҝғжҖҒпјҹ
е…Ёж–Үе…ұ2208еӯ— пјҢ йў„и®ЎеӯҰд№ ж—¶й•ҝ6еҲҶй’ҹ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
вҖңжҖқиҖғеҶҚжҖқиҖғ пјҢ 然еҗҺйҮҮеҸ–иЎҢеҠЁвҖқ пјҢ иҝҷж ·зҡ„жөҒзЁӢжҳҜдёҚжҳҜеҗ¬иө·жқҘеҫҲзҶҹжӮүпјҹеӨ§еӨҡж•°дәәйғҪжҳҜиҝҷж ·еҒҡзҡ„ гҖӮ
然иҖҢ пјҢ иҝҷдёӘжҖқиҖғжөҒзЁӢеҫҲеҸҜиғҪжҳҜдёҖжҠҠеҸҢеҲғеү‘пјҡеңЁдёҖдәӣжғ…еҪўдёӢ пјҢ з»“жһңеҸҜиғҪз§ҜжһҒжңүз”Ё пјҢ дҪҶеңЁеҸҰдёҖдәӣжғ…еҪўдёӢ пјҢ з»“жһңеҸҜиғҪжңүе®і пјҢ з”ҡиҮіеҸҚеҷ¬иҮӘиә« гҖӮ еҗҺиҖ…жҳҜжҲ‘们йғҪеёҢжңӣйҒҝе…Қзҡ„ гҖӮ дёәдәҶжё…жҷ°дәҶи§Јжғ…з»Әзҡ„еҲ’еҲҶ пјҢ жҲ‘зј–еҶҷдәҶиҝҷдёӘжңәеҷЁеӯҰд№ пјҲMLпјүзЁӢеәҸ гҖӮ
йҡ”зҰ»йҳ¶ж®өи®©жҲ‘жңүжңәдјҡжҺўзҙўиҮӘжҲ‘并审и§ҶиҮӘе·ұзҡ„жҖқи·Ҝ гҖӮ жҲ‘дёҚжҳҜдёҖдёӘжІүжҖқиҖ… пјҢ дҪҶжҳҜжҖ»дјҡйҷ·е…Ҙзә·д№ұзҡ„жҖқз»Әд№Ӣдёӯ пјҢ жҜҸеҪ“иҝҷж—¶ пјҢ жҲ‘йғҪйңҖиҰҒзҗҶжё…жҖқи·Ҝ гҖӮ еӣ жӯӨжҲ‘иҰҒеҲӣе»әдёҖдёӘеҸҜд»ҘеҲҶжһҗжҲ‘зҡ„жҖқиҖғиҝҮзЁӢзҡ„MLжЁЎеһӢ гҖӮ жҲ‘з”ЁKNNз®—жі•еҲӨж–ӯеә”иҜҘйҒҝе…Қзҡ„жғ…з»Ә пјҢ 并йҖҡиҝҮеҸҜи§ҶеҢ–жҠҖжңҜе°ҶжҲ‘зҡ„жғ…з»Әд»ҘеӣҫеҪўеұ•зӨә пјҢ дҪҝжҲ‘жё…жҷ°ең°дёҖи§Ҳе…ЁиІҢ гҖӮ дёӢйқўжҳҜжҲ‘зҡ„еҒҡжі•пјҡ
В· дҪңдёәејҖе§Ӣ пјҢ жҲ‘еҲӣе»әдәҶдёҖдёӘжңүдёҚеҗҢжғіжі•зҡ„ж•°жҚ®йӣҶпјӣ
В· дҪҝз”ЁKNNз®—жі•пјӣ
В· дҪҝз”ЁеҸҜи§ҶеҢ–жҠҖжңҜпјӣ
В· жңҖеҗҺ пјҢ жҲ‘еӯҰдјҡдәҶеҲҶеүІжҖқиҖғиҝҮзЁӢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
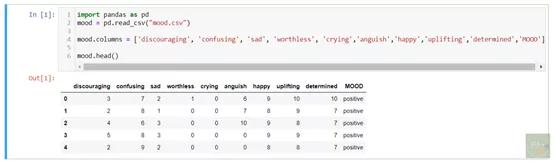
еҲӣе»әж•°жҚ®йӣҶж•°жҚ®йӣҶз”ұд№қз§Қжғ…з»ӘпјҲзү№еҫҒпјүз»„жҲҗпјҡжІ®дё§ пјҢ жӮІдјӨ пјҢ еҚ‘еҫ® пјҢ е“ӯжіЈ пјҢ з—ӣиӢҰ пјҢ еӣ°жғ‘ пјҢ еҝ«д№җ пјҢ жҢҜеҘӢе’Ңеқҡе®ҡ гҖӮ жҲ‘е°Ҷе®ғ们еҲҶдёәдёүзұ»пјҲж Үзӯҫпјүпјҡз§ҜжһҒ пјҢ ж¶ҲжһҒе’Ңдёӯз«Ӣ гҖӮ еҸҰеӨ– пјҢ жҲ‘ж №жҚ®ж ҮзӯҫеҜ№иҝҷд№қз§Қжғ…з»Ә/зү№еҫҒеқҮжҢү1-10зҡ„ж ҮеҮҶиҝӣиЎҢдәҶиҜ„еҲҶ гҖӮ дәҺжҳҜжҲ‘еҲӣе»әдәҶе…ұ150дёӘжЎҲдҫӢ гҖӮ иҝҷжҳҜж•°жҚ®йӣҶзҡ„еүҚеҮ иЎҢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дҪҝз”ЁKNNз®—жі•еңЁејҖе§ӢдёӢдёҖжӯҘд№ӢеүҚ пјҢ йҰ–е…ҲйңҖиҰҒжҺҢжҸЎдёҖдәӣзӣ‘зқЈејҸеӯҰд№ зҡ„MLеҹәжң¬жңҜиҜӯпјҡ
В· дёәдәҶи®ӯз»ғгҖҒжөӢиҜ•е’ҢиҜ„дј°дёҖдёӘжЁЎеһӢ пјҢ жҲ‘们дҪҝз”ЁдёҖзі»еҲ—жЎҲдҫӢпјӣ
В· иҝҷдәӣжЎҲдҫӢеҢ…жӢ¬дёҺжЁЎеһӢзӣёе…ізҡ„зү№еҫҒе’Ңж ҮзӯҫеҖјпјӣ
В· зү№еҫҒжҳҜз”ЁдәҺи®ӯз»ғз®—жі•зҡ„еҹәзЎҖеҖјпјӣ
В· дёҖж—Ұи®ӯз»ғйғЁеҲҶз»“жқҹ пјҢ з®—жі•е°ұиғҪйў„жөӢжөӢиҜ•зү№еҫҒзҡ„жӯЈзЎ®ж ҮзӯҫеҖј гҖӮ
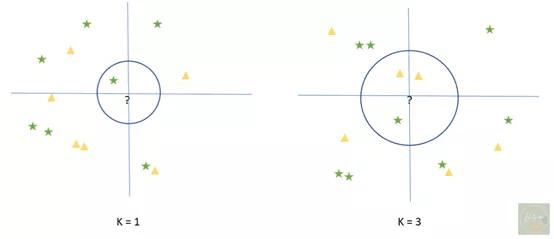
зӣ®ж ҮжҳҜжӯЈзЎ®йў„жөӢж Үзӯҫ гҖӮ еӣ жӯӨ пјҢ еҸ—и®ӯз®—жі•зҡ„зІҫеәҰеә”иҜҘеҫҲй«ҳ гҖӮ еҰӮжһңдёҚй«ҳ пјҢ еә”дҪҝйў„жөӢзҡ„ж ҮзӯҫеҖје’ҢеҺҹжң¬ж Үзӯҫд№Ӣй—ҙзҡ„иҜҜе·®жңҖе°ҸеҢ– гҖӮ жңүдәҶиҝҷдәӣеҹәзЎҖзҹҘиҜҶ пјҢ и®©жҲ‘们жҺҘзқҖжқҘдәҶи§ЈKNNз®—жі• гҖӮ KNNжҳҜзӣ‘зқЈејҸзҡ„жңәеҷЁеӯҰд№ з®—жі• пјҢ вҖңKвҖқжҳҜеҫ…еҲҶзұ»зӮ№йӮ»иҝ‘еҖјзҡ„дёӘж•° (дҫӢеҰӮ пјҢ K=1гҖҒ2гҖҒ3зӯү) гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е·Ұеӣҫдёӯ пјҢ KNNдјҡе°ҶвҖңпјҹвҖқеҪ’зұ»дёәз»ҝиүІжҳҹжҳҹ пјҢ еӣ дёәе®ғжңҖиҝ‘ гҖӮ еҗҢж · пјҢ еңЁеҸідҫӢдёӯKNNдјҡе°ҶвҖңпјҹвҖқеҪ’дёәй»„иүІдёүи§’ пјҢ еӣ дёәиҝҷдәӣдёүи§’еҪўжҳҜжңҖжҺҘиҝ‘зҡ„еӨҡж•°жғ…еҶө гҖӮ
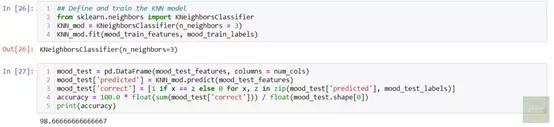
ж–°жЎҲдҫӢдёҺе·ІзҹҘжЎҲдҫӢд№Ӣй—ҙзҡ„жҺҘиҝ‘зЁӢеәҰ пјҢ еҸҜд»ҘдҪҝз”Ёд»»ж„Ҹи·қзҰ»еҮҪж•° пјҢ еҰӮ欧еҮ йҮҢеҫ—е°әеәҰе’ҢжҳҺеҸҜеӨ«ж–Ҝеҹәе°әеәҰзӯүдҪ“зҺ° гҖӮ еӣ жӯӨз§°д№ӢдёәжңҖйӮ»иҝ‘ гҖӮ иҝҷж · пјҢ KNNз®—жі•еҜ№ж–°жЎҲдҫӢиҝӣиЎҢдәҶеҲҶзұ» гҖӮ еңЁиҝҷз§Қзү№е®ҡжЁЎејҸдёӯ пјҢ KNNиҰҒжӯЈзЎ®йў„жөӢеҗ„дёӘжғ…з»Әзҡ„еҲҶзұ» гҖӮ йў„еӨ„зҗҶжүҖжңүж•°жҚ®еҗҺ пјҢ жҲ‘дҪҝз”ЁдәҶKNNз®—жі• пјҢ 然еҗҺи®Ўз®—еҮәеҮҶзЎ®еәҰдёә98.6пј… гҖӮ иҝҷжҳҜжҳҫзӨәзӣёеҗҢзҡ„д»Јз Ғж®өпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дҪҝз”ЁеҸҜи§ҶеҢ–жҠҖжңҜжҲ‘з”Ёж•°жҚ®еҸҜи§ҶеҢ–иҝӣиЎҢдәҶеҲҶзұ» пјҢ еӣҫиЎЁжӣҙдҫҝдәҺзҗҶи§Ј пјҢ 并еҲӣе»әдәҶдёҖз§Қи§ЈеҶіж–№жЎҲ пјҢ з”ЁжқҘйў„жөӢжҲ‘еә”иҜҘйҒҝе…Қд»Җд№Ҳж ·зҡ„жғ…з»ӘжүҚиғҪдҝқжҢҒдёҖдёӘз§ҜжһҒзҡ„еҝғжҖҒ гҖӮ иҝҷдёӘжҠҖжңҜе°Ҷеё®еҠ©жҲ‘еҲҶиҫЁж Үзӯҫзұ»еҲ«пјҲз§ҜжһҒгҖҒж¶ҲжһҒе’ҢдёӯжҖ§пјү пјҢ дёәжӯӨжҲ‘дҪҝз”ЁдәҶвҖңз®ұеҪўеӣҫвҖқ гҖӮ
ж–Үз« жҸ’еӣҫ
з»“жһң
жҺЁиҚҗйҳ…иҜ»










![ж–°еҚҺзҪ‘|еҫ·еӣҪжі•е…°е…ӢзҰҸвҖңи·іиҡӨеёӮеңәвҖқйҮҚж–°ејҖж”ҫ[з»„еӣҫ]](https://mz.eastday.com/16510358.jpeg)





- iQOO 7йӮҖиҜ·еҮҪжӣқе…үвҖң马вҖқвҖңйёӯвҖқвҖңзҫҠвҖқд»ЈиЎЁд»Җд№Ҳ
- жӣҙдҫҝе®ңзҡ„зұі11зі»еҲ—ж–°е“ҒиҰҒжқҘдәҶпјҢе°Ҹзұі11LiteдәҶи§ЈдёӢ
- дәәе·ҘжҷәиғҪжӯЈеңЁдәҶи§Јдәәзұ»зҡ„вҖңиЁҖеӨ–д№Ӣж„ҸвҖқ
- еҚҺдёәиҰҒ让专家еҪ“家пјҢдҪ дәҶи§ЈеҚҺдёәеҗ—пјҹеҚҺдёәеҜ№дәҺдёӯеӣҪеҲӣдёҡиҖ…зңҹжӯЈзҡ„ж„Ҹд№ү
- жӣІйқўз”өз«һжҳҫзӨәеҷЁдәҶи§ЈдёҖдёӢ зҺҜз»•и§Ҷи§үжІүжөёдҪ“йӘҢ
- дёүжҳҹж–°жңәдё“еҲ©жӣқе…үпјҢдјёзј©ејҸеұҸдёӢй•ңеӨҙдәҶи§ЈдёӢ
- ж“Ұең°жңәеҷЁдәәе“ҒзүҢжҺ’иЎҢжҰңжқҘдәҶпјҢдҪ жғідәҶи§Јзҡ„йғҪеңЁиҝҷйҮҢ
- иҜәеҹәдәҡ5Gи®ўеҚ•ж•°е·Із ҙзҷҫпјҢзҲұз«ӢдҝЎжӣҙжҳҜиҫҫеҲ°118дёӘпјҢйӮЈеҚҺдёәе‘ўпјҹ
- и°·жӯҢAIеҸҲиҺ·йҮҚеӨ§зӘҒз ҙпјҒж–°з®—жі•ж— йңҖдәҶ解规еҲҷд№ҹиғҪиҮӘеӯҰжҲҗвҖңжЈӢвҖқ
- д№°дёӢдёҖйғЁжүӢжңәжүӢжңәеүҚ иҜ·дәҶи§ЈдёҖдёӢOriginOS