ML Opsпјҡж•°жҚ®иҙЁйҮҸжҳҜе…ій”®( дәҢ )
еҚідҪҝжҳҜеңЁж•°жҚ®йӣҶеӨ„зҗҶзҡ„ж—©жңҹйҳ¶ж®ө пјҢ д»Һй•ҝиҝңжқҘзңӢ пјҢ еҜ№ж•°жҚ®иҝӣиЎҢиҙЁйҮҸжЈҖжҹҘе’Ңж–ҮжЎЈи®°еҪ•еҸҜд»ҘжһҒеӨ§ең°еҠ йҖҹж“ҚдҪң гҖӮ еҜ№дәҺе·ҘзЁӢеёҲжқҘиҜҙ пјҢ еҸҜйқ зҡ„ж•°жҚ®жөӢиҜ•йқһеёёйҮҚиҰҒ пјҢ еҸҜд»ҘдҪҝ他们е®үе…Ёең°еҜ№ж•°жҚ®иҺ·еҸ– pipeline иҝӣиЎҢжӣҙж”№ пјҢ иҖҢдёҚдјҡйҖ жҲҗдёҚеҝ…иҰҒзҡ„й—®йўҳ гҖӮ еҗҢж—¶ пјҢ еҪ“д»ҺеҶ…йғЁе’ҢеӨ–йғЁдёҠжёёжқҘжәҗиҺ·еҸ–ж•°жҚ®ж—¶ пјҢ дёәдәҶзЎ®дҝқж•°жҚ®еҮәзҺ°жңӘйў„ж–ҷзҡ„жӣҙж”№ пјҢ еңЁиҺ·еҸ–йҳ¶ж®өиҝӣиЎҢж•°жҚ®йӘҢиҜҒжҳҜйқһеёёйҮҚиҰҒзҡ„ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жЁЎеһӢејҖеҸ‘
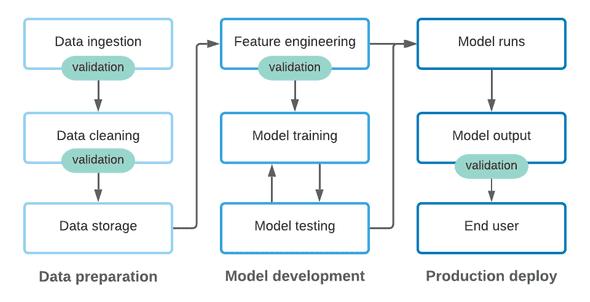
жң¬ж–Үе°Ҷзү№еҫҒе·ҘзЁӢгҖҒжЁЎеһӢи®ӯз»ғе’ҢжЁЎеһӢжөӢиҜ•дҪңдёәж ёеҝғжЁЎеһӢејҖеҸ‘жөҒзЁӢзҡ„дёҖйғЁеҲҶ гҖӮ еңЁиҝҷдёӘдёҚж–ӯиҝӯд»Јзҡ„иҝҮзЁӢдёӯ пјҢ еӣҙз»•ж•°жҚ®иҪ¬жҚўд»Јз Ғе’Ңж”ҜжҢҒж•°жҚ®з§‘еӯҰ家зҡ„жЁЎеһӢиҫ“еҮәжҸҗдҫӣж”ҜжҢҒ пјҢ еӣ жӯӨеңЁдёҖдёӘең°ж–№иҝӣиЎҢжӣҙж”№дёҚдјҡз ҙеқҸе…¶д»–ең°ж–№зҡ„еҶ…е®№ гҖӮ
еңЁдј з»ҹзҡ„ DevOps дёӯ пјҢ йҖҡиҝҮ CI/CD е·ҘдҪңжөҒиҝӣиЎҢжҢҒз»ӯзҡ„жөӢиҜ• пјҢ еҸҜд»Ҙеҝ«йҖҹең°жүҫеҮәеӣ д»Јз Ғдҝ®ж”№иҖҢеј•е…Ҙзҡ„д»»дҪ•й—®йўҳ гҖӮ жӣҙиҝӣдёҖжӯҘ пјҢ еӨ§еӨҡж•°иҪҜ件е·ҘзЁӢеӣўйҳҹиҰҒжұӮејҖеҸ‘дәәе‘ҳдёҚд»…иҰҒдҪҝз”ЁзҺ°жңүзҡ„жөӢиҜ•жқҘжөӢиҜ•д»Јз Ғ пјҢ иҝҳиҰҒеңЁеҲӣе»әж–°еҠҹиғҪж—¶ж·»еҠ ж–°зҡ„жөӢиҜ• гҖӮ еҗҢж · пјҢ иҝҗиЎҢжөӢиҜ•д»ҘеҸҠзј–еҶҷж–°зҡ„жөӢиҜ•еә”иҜҘжҳҜ ML жЁЎеһӢејҖеҸ‘иҝҮзЁӢзҡ„дёҖйғЁеҲҶ гҖӮ
еңЁз”ҹдә§дёӯиҝҗиЎҢжЁЎеһӢ
дёҺжүҖжңү ML Ops дёҖж · пјҢ еңЁз”ҹдә§зҺҜеўғдёӯиҝҗиЎҢзҡ„жЁЎеһӢдҫқиө–дәҺд»Јз Ғе’Ңиҫ“е…Ҙж•°жҚ® пјҢ жқҘдә§з”ҹеҸҜйқ зҡ„з»“жһң гҖӮ дёҺж•°жҚ®иҺ·еҸ–йҳ¶ж®өзұ»дјј пјҢ жҲ‘们йңҖиҰҒдҝқжҠӨж•°жҚ®иҫ“е…Ҙ пјҢ д»ҘйҒҝе…Қз”ұдәҺд»Јз Ғжӣҙж”№жҲ–е®һйҷ…ж•°жҚ®жӣҙж”№иҖҢеј•иө·зҡ„дёҚеҝ…иҰҒй—®йўҳ гҖӮ еҗҢж—¶ пјҢ жҲ‘们иҝҳеә”иҜҘеӣҙз»•жЁЎеһӢиҫ“еҮәиҝӣиЎҢдёҖдәӣжөӢиҜ• пјҢ д»ҘзЎ®дҝқжЁЎеһӢ继з»ӯж»Ўи¶іжҲ‘们зҡ„жңҹжңӣ гҖӮ
гҖҗML Opsпјҡж•°жҚ®иҙЁйҮҸжҳҜе…ій”®гҖ‘е°Өе…¶жҳҜеңЁе…·жңүй»‘зӣ’ ML жЁЎеһӢзҡ„зҺҜеўғдёӯ пјҢ е»әз«Ӣе’Ңз»ҙжҠӨиҙЁйҮҸж ҮеҮҶеҜ№дәҺжЁЎеһӢиҫ“еҮәиҮіе…ійҮҚиҰҒ гҖӮ еҗҢж ·ең° пјҢ еңЁе…ұдә«еҢәеҹҹи®°еҪ•жЁЎеһӢзҡ„йў„жңҹиҫ“еҮәеҸҜд»Ҙеё®еҠ©ж•°жҚ®еӣўйҳҹе’ҢеҲ©зӣҠзӣёе…іиҖ…е®ҡд№үе’Ңдј иҫҫгҖҢж•°жҚ®еҗҲеҗҢгҖҚ пјҢ д»ҺиҖҢеўһеҠ ML pipeline зҡ„йҖҸжҳҺеәҰе’ҢдҝЎд»»еәҰ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»




![[е”җе°Ҹе§җзҫҺйЈҹи®°]з«ӢеӨҸе°ҶиҮіпјҢиҝҷ6з§Қж—¶д»Ө蔬иҸңеҗғиө·жқҘпјҢд»·ж јдёҚиҙөиҗҘе…»й«ҳпјҢжҜ”еӨ§йұјеӨ§иӮүеҘҪ](http://ttbs.guangsuss.com/image/5959a505c1018e78d7432b8a16b0f427)










- иҘҝйғЁж•°жҚ®еңЁCES 2021жҺЁеҮәеӨҡж¬ҫ4TBе®№йҮҸзҡ„ж——иҲ°зә§SSD
- WhatsApp收йӣҶз”ЁжҲ·ж•°жҚ®ж–°ж”ҝжғ№дј—жҖ’пјҢвҖңеҲ йҷӨWhatsAppвҖқеңЁеңҹиҖіе…¶дёҠзғӯжҗң
- вҖңеҚғеә—еҗҢејҖвҖқеј•иҙЁйҮҸжӢ…еҝ§пјҢе°Ҹзұіеӣһеә”
- жңӘжқҘжғіиҝӣе…ҘAIйўҶеҹҹпјҢиҜҘеӯҰд№ PythonиҝҳжҳҜJavaеӨ§ж•°жҚ®ејҖеҸ‘
- й»‘е®ўзӘғеҸ–250дёҮдёӘдәәж•°жҚ® ж„ҸеӨ§еҲ©иҝҗиҗҘе•ҶжҸҗйҶ’з”ЁжҲ·е°Ҫеҝ«жӣҙжҚўSIMеҚЎ
- ж¶Ҳиҙ№иҖ…жҠҘе‘Ҡ | зҫҺеӣўе……з”өе®қз”өйҮҸдёҚи¶ід№ҹжүЈиҙ№пјҢжҳҜиҙЁйҮҸй—®йўҳиҝҳжҳҜзі»з»ҹзјәйҷ·пјҹ
- iPhoneиҙЁйҮҸжҖҺд№Ҳж ·пјҹеҗҙеҪҰзҘ–е°„дәҶдёҖз®ӯиҝҳиғҪз”Ё
- йҳізӢ®жҠҘе‘Ҡпјҡ4жҲҗеҸ—и®ҝиҖ…и®ӨдёәиҮӘе·ұзҡ„ж•°жҚ®жҜ”е…Қиҙ№жңҚеҠЎжӣҙжңүд»·еҖј
- дёӯж¶ҲеҚҸзӮ№еҗҚеӨ§ж•°жҚ®зҪ‘з»ңжқҖзҶҹ еҸҚеҜ№еҲ©з”Ёж¶Ҳиҙ№иҖ…дёӘдәәж•°жҚ®з”»еғҸ
- еӯҰд№ еӨ§ж•°жҚ®жҳҜеҗҰйңҖиҰҒеӯҰд№ JavaEE