ж·ұе…Ҙжө…еҮәSparkпјҲдәҢпјүпјҡиЎҖз»ҹпјҲDAGпјү
дё“йўҳд»Ӣз»Қ
2009 е№ҙ пјҢ Spark иҜһз”ҹдәҺеҠ е·һеӨ§еӯҰдјҜе…ӢеҲ©еҲҶж Ўзҡ„ AMP е®һйӘҢе®ӨпјҲthe Algorithms, Machines and People labпјү пјҢ 并дәҺ 2010 е№ҙејҖжәҗ гҖӮ 2013 е№ҙ пјҢ Spark жҚҗзҢ®з»ҷйҳҝеё•еҘҮиҪҜ件еҹәйҮ‘дјҡпјҲApache Software Foundationпјү пјҢ 并дәҺ 2014 е№ҙжҲҗдёә Apache йЎ¶зә§йЎ№зӣ® гҖӮ
еҰӮд»Ҡ пјҢ еҚҒе№ҙе…үжҷҜе·ІиҝҮ пјҢ Spark жҲҗдёәдәҶеӨ§еӨ§е°Ҹе°ҸдјҒдёҡдёҺз ”з©¶жңәжһ„зҡ„еёёз”Ёе·Ҙе…·д№ӢдёҖ пјҢ дҫқж—§ж·ұеҸ—дёҚе°‘ејҖеҸ‘дәәе‘ҳзҡ„е–ңзҲұ гҖӮ еҰӮжһңдҪ жҳҜеҲқе…Ҙжұҹж№–дё”еёҢжңӣдәҶи§ЈгҖҒеӯҰд№ Spark зҡ„вҖңе°ҸиҷҫзұівҖқ пјҢ йӮЈд№Ҳ InfoQ дёҺ FreeWheel жҠҖжңҜ专家еҗҙзЈҠеҗҲдҪңзҡ„дё“йўҳзі»еҲ—ж–Үз« вҖ”вҖ”гҖҠж·ұе…Ҙжө…еҮә SparkпјҡеҺҹзҗҶиҜҰи§ЈдёҺејҖеҸ‘е®һи·өгҖӢдёҖе®ҡйҖӮеҗҲдҪ пјҒ
жң¬ж–Үзі»дё“йўҳзі»еҲ—第дәҢзҜҮ гҖӮ
д№ҰжҺҘеүҚж–Ү пјҢ еңЁдёҠдёҖзҜҮгҖҠеҶ…еӯҳи®Ўз®—зҡ„з”ұжқҘ вҖ”вҖ” RDDгҖӢ пјҢ жҲ‘们д»ҺвҖңиҷҡвҖқгҖҒвҖңе®һвҖқдёӨдёӘж–№йқўд»Ӣз»ҚдәҶRDD зҡ„еҹәжң¬жһ„жҲҗ гҖӮ RDD йҖҡиҝҮdependencies е’Ңcompute еұһжҖ§йҰ–е°ҫзӣёиҝһжһ„жҲҗзҡ„и®Ўз®—и·Ҝеҫ„ пјҢ дё“дёҡжңҜиҜӯз§°д№ӢдёәLineage вҖ”вҖ” иЎҖз»ҹ пјҢ еҸҲеҗҚDAGпјҲDirected Acyclic Graph пјҢ жңүеҗ‘ж— зҺҜеӣҫпјү гҖӮ дёҖдёӘжҰӮеҝөдёәд»Җд№ҲдјҡжңүдёӨдёӘз§°е‘је‘ўпјҹиҝҷдёӨдёӘдёҚеҗҢзҡ„еҗҚеӯ—еҸҲжңүд»Җд№ҲеҢәеҲ«е’ҢиҒ”зі»пјҹз®ҖеҚ•ең°иҜҙ пјҢ иЎҖз»ҹдёҺDAG жҳҜд»ҺдёӨдёӘдёҚеҗҢзҡ„и§Ҷи§’еҮәеҸ‘ пјҢ жқҘжҸҸиҝ°еҗҢдёҖдёӘдәӢзү© гҖӮ иЎҖз»ҹ пјҢ дҫ§йҮҚдәҺд»Һж•°жҚ®зҡ„и§’еәҰжҸҸиҝ°дёҚеҗҢRDD д№Ӣй—ҙзҡ„дҫқиө–е…ізі»пјӣDAG пјҢ еҲҷжҳҜд»Һи®Ўз®—зҡ„и§’еәҰжҸҸиҝ°дёҚеҗҢRDD д№Ӣй—ҙзҡ„иҪ¬жҚўйҖ»иҫ‘ гҖӮ еҰӮжһңиҜҙRDD жҳҜSpark еҜ№дәҺеҲҶеёғејҸж•°жҚ®жЁЎеһӢзҡ„жҠҪиұЎ пјҢ йӮЈд№ҲдёҺд№ӢеҜ№еә”ең° пјҢ DAG е°ұжҳҜSpark еҜ№дәҺеҲҶеёғејҸи®Ўз®—жЁЎеһӢзҡ„жҠҪиұЎ гҖӮ
йЎҫеҗҚжҖқд№ү пјҢ DAG жҳҜдёҖз§ҚвҖңеӣҫвҖқ пјҢ еӣҫи®Ўз®—жЁЎеһӢзҡ„еә”з”Ёз”ұжқҘе·Ід№… пјҢ ж—©еңЁдёҠдёӘдё–зәӘе°ұиў«еә”з”ЁдәҺж•°жҚ®еә“зі»з»ҹпјҲGraph databasesпјүзҡ„е®һзҺ°дёӯ гҖӮ д»»дҪ•дёҖдёӘеӣҫйғҪеҢ…еҗ«дёӨз§Қеҹәжң¬е…ғзҙ пјҡиҠӮзӮ№пјҲVertexпјүе’Ңиҫ№пјҲEdgeпјү пјҢ иҠӮзӮ№йҖҡеёёз”ЁдәҺиЎЁзӨәе®һдҪ“ пјҢ иҖҢиҫ№еҲҷд»ЈиЎЁе®һдҪ“й—ҙзҡ„е…ізі» гҖӮ дҫӢеҰӮ пјҢ еңЁвҖңеҖҡеӨ©еұ йҫҷвҖқзӨҫдәӨзҪ‘з»ңзҡ„еҘҪеҸӢе…ізі»дёӯ пјҢ жҜҸдёӘиҠӮзӮ№иЎЁзӨәдёҖдёӘе…·дҪ“зҡ„дәә пјҢ жҜҸжқЎиҫ№ж„Ҹе‘ізқҖдёӨз«Ҝзҡ„е®һдҪ“д№Ӣй—ҙе»әз«ӢдәҶеҘҪеҸӢе…ізі» гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
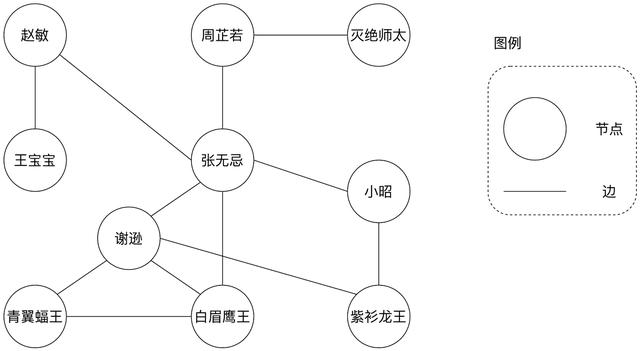
еҖҡеӨ©еұ йҫҷзӨҫдәӨзҪ‘з»ң
еңЁдёҠйқўзҡ„зӨҫдәӨзҪ‘з»ңдёӯ пјҢ еҘҪеҸӢе…ізі»жҳҜзӣёдә’зҡ„ пјҢ еҰӮеј ж— еҝҢе’Ңе‘ЁиҠ·иӢҘдә’дёәеҘҪеҸӢ пјҢ еӣ жӯӨиҜҘе…ізі»еӣҫдёӯзҡ„иҫ№жҳҜжІЎжңүжҢҮеҗ‘жҖ§зҡ„пјӣеҸҰеӨ– пјҢ з»Ҷеҝғзҡ„еҗҢеӯҰеҸҜиғҪе·Із»ҸеҸ‘зҺ° пјҢ дёҠйқўзҡ„еӣҫз»“жһ„жҳҜжңүвҖңзҺҜвҖқзҡ„ пјҢ еҰӮеј ж— еҝҢгҖҒи°ўйҖҠгҖҒзҷҪзңүй№°зҺӢжһ„жҲҗзҡ„е…ізі»зҺҜ пјҢ еј ж— еҝҢгҖҒи°ўйҖҠгҖҒзҙ«иЎ«йҫҷзҺӢгҖҒе°Ҹжҳӯд№Ӣй—ҙзҡ„е…ізі»зҺҜ пјҢ зӯүзӯү гҖӮ еғҸдёҠйқўиҝҷж ·зҡ„еӣҫз»“жһ„ пјҢ жңҜиҜӯз§°д№ӢдёәвҖңж— еҗ‘жңүзҺҜеӣҫвҖқ гҖӮ жІЎжңүжҜ”иҫғе°ұжІЎжңүйүҙеҲ« пјҢ жңүеҗ‘ж— зҺҜеӣҫпјҲDAGпјүиҮӘ然жҳҜдёҖз§ҚеёҰжңүжҢҮеҗ‘жҖ§гҖҒдёҚеӯҳеңЁвҖңзҺҜвҖқз»“жһ„зҡ„еӣҫжЁЎеһӢ гҖӮ еҗ„дҪҚзңӢе®ҳиҝҳи®°еҫ—еңҹиұҶе·ҘеқҠзҡ„дҫӢеӯҗеҗ—пјҹ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еңҹиұҶе·ҘеқҠDAG
еңЁдёҠйқўзҡ„еңҹиұҶеҠ е·ҘDAG дёӯ пјҢ жҜҸдёӘиҠӮзӮ№жҳҜдёҖдёӘдёӘRDD пјҢ жҜҸжқЎиҫ№д»ЈиЎЁзқҖдёҚеҗҢRDD д№Ӣй—ҙзҡ„зҲ¶еӯҗе…ізі» вҖ”вҖ” зҲ¶еӯҗе…ізі»иҮӘ然жҳҜеҚ•еҗ‘зҡ„ пјҢ еӣ жӯӨж•ҙеј еӣҫжҳҜжңүжҢҮеҗ‘жҖ§зҡ„ гҖӮ еҸҰеӨ–жҲ‘们注ж„ҸеҲ° пјҢ ж•ҙдёӘеӣҫдёӯжҳҜдёҚеӯҳеңЁзҺҜз»“жһ„зҡ„ гҖӮ еғҸиҝҷж ·зҡ„еңҹиұҶеҠ е·ҘжөҒж°ҙзәҝеҸҜд»ҘиҜҙжҳҜжңҖз®ҖеҚ•зҡ„жңүеҗ‘ж— зҺҜеӣҫ пјҢ жҜҸдёӘиҠӮзӮ№зҡ„е…ҘеәҰпјҲIndegree пјҢ жҢҮеҗ‘иҮӘе·ұзҡ„иҫ№пјүдёҺеҮәеәҰпјҲOutdegree пјҢ д»ҺиҮӘе·ұеҮәеҸ‘зҡ„иҫ№пјүйғҪжҳҜ1 пјҢ ж•ҙдёӘеӣҫзңӢдёӢжқҘеҸӘжңүдёҖжқЎеҲҶж”Ҝ гҖӮ
дёҚиҝҮ пјҢ е·Ҙдёҡеә”з”Ёдёӯзҡ„Spark DAG иҰҒжҜ”иҝҷеӨҚжқӮеҫ—еӨҡ пјҢ еҫҖеҫҖжҳҜз”ұдёҚеҗҢRDD з»ҸиҝҮе…іиҒ”гҖҒжӢҶеҲҶдә§з”ҹеӨҡдёӘеҲҶж”Ҝзҡ„жңүеҗ‘ж— зҺҜеӣҫ гҖӮ дёәдәҶиҜҙжҳҺиҝҷдёҖзӮ№ пјҢ жҲ‘们иҝҳжҳҜжӢҝеңҹиұҶе·ҘеқҠжқҘдёҫдҫӢ пјҢ еңЁе°ҶвҖңеҺҹе‘івҖқи–ҜзүҮжҺЁеҗ‘еёӮеңәдёҖж®өж—¶й—ҙеҗҺ пјҢ е·ҘеқҠиҖҒжқҝеҸ‘зҺ°еӯЈеәҰй”ҖйҮҸзӣҙзәҝдёӢж»‘ пјҢ иҖҒжқҝеҝғжҖҘеҰӮз„ҡгҖҒдёҖзӯ№иҺ«еұ• гҖӮ жӯӨж—¶жңүдәәеҗ‘д»–е»әи®®пјҡвҖңдҪ•дёҚжҺЁеҮәжӣҙеӨҡйЈҺе‘ізҡ„и–ҜзүҮ пјҢ жқҘиҝҺеҗҲеӨ§дј—зҡ„еӨҡж ·еҢ–йҖүжӢ©вҖқ пјҢ дәҺжҳҜиҖҒжқҝдёҖеЈ°д»ӨдёӢ пјҢ е·Ҙдәә们еҜ№жөҒж°ҙзәҝеҒҡдәҶеҰӮдёӢж”№еҠЁ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
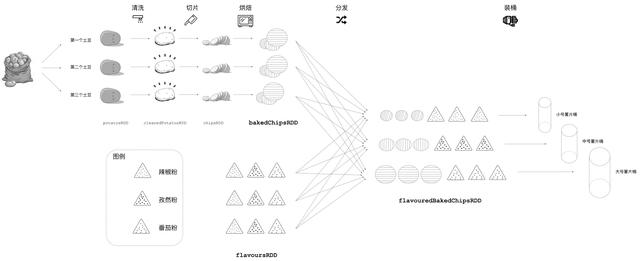
еңҹиұҶе·ҘеқҠй«ҳзә§з”ҹдә§зәҝ
дёҺд№ӢеүҚзӣёжҜ” пјҢ ж–°зҡ„жөҒзЁӢеўһеҠ дәҶ3 жқЎйЈҺе‘іжөҒж°ҙзәҝ пјҢ з”ЁдәҺеҲҶеҸ‘дёҚеҗҢзҡ„и°ғж–ҷзІү гҖӮ ж–°жөҒж°ҙзәҝдёҠзҡ„иҫЈжӨ’зІүиў«еҲҶеҸ‘еҲ°ж”¶йӣҶе°ҸеҸ·и–ҜзүҮзҡ„жөҒж°ҙзәҝгҖҒеӯң然зІүеҲҶеҸ‘еҲ°дёӯеҸ·и–ҜзүҮжөҒж°ҙзәҝ пјҢ зӣёеә”ең° пјҢ з•ӘиҢ„зІүеҲҶеҸ‘еҲ°еӨ§еҸ·и–ҜзүҮжөҒж°ҙзәҝ гҖӮ з»ҸиҝҮж”№йҖ пјҢ еңҹиұҶе·ҘеқҠзҺ°еңЁеҸҜд»Ҙз”ҹдә§3 з§ҚйЈҺе‘ігҖҒдёҚеҗҢе°әеҜёзҡ„и–ҜзүҮ пјҢ еҚійә»иҫЈе‘ізҡ„е°ҸеҸ·и–ҜзүҮгҖҒеӯң然味зҡ„дёӯеҸ·и–ҜзүҮе’Ңз•ӘиҢ„е‘ізҡ„еӨ§еҸ·и–ҜзүҮ гҖӮ еҰӮжһңжҲ‘们用flavoursRDD жқҘжҠҪиұЎи°ғе‘іе“Ғзҡ„иҜқ пјҢ йӮЈд№Ҳе·ҘеқҠж–°дҪңдёҡжөҒзЁӢжүҖеҜ№еә”зҡ„DAG дјҡжј”еҢ–дёәеҰӮдёӢжүҖзӨәеёҰжңү2 дёӘеҲҶж”Ҝзҡ„жңүеҗ‘ж— зҺҜеӣҫ гҖӮ
жҺЁиҚҗйҳ…иҜ»








![[иө°з§Ғ]иӯҰж–№зӘҒиўӯиө°з§Ғд»“еә“пјҢеҸ‘зҺ°10жһ¶е…ұиҪҙж—ӢзҝјзӣҙеҚҮжңәпјҢеұ…然жҳҜзәҜжүӢе·Ҙжү“йҖ](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/c8ccb32baca45ed2b7fdedb939dbab14.jpg)




![[иҫ…еҠ©и®ӯз»ғ]еҲҶжё…дё»ж¬ЎпјҢиҫ…еҠ©и®ӯз»ғеҸӘиғҪжҳҜиҫ…еҠ©пјҒ](http://ttbs.guangsuss.com/image/a9e56a600a9c6f896d0b8d5345ff816b)


- иӢұдә§иЎҖз»ҹ зәҜжӯЈйҹіиүІ RHA TrueConnect2зңҹж— зәҝи“қзүҷиҖіжңә
- йӣ¶еҹәзЎҖе…Ҙй—ЁSpark groupByж“ҚдҪң(JavaзүҲ)
- е”Ҝе“Ғдјҡе®һж—¶е№іеҸ°жһ¶жһ„-FlinkгҖҒSparkгҖҒStorm
- д»Һ0еҲ°1иҝӣиЎҢSpark historyеҲҶжһҗ
- йӣ¶иҝӣзЁӢе…Ҙй—ЁSpark keyByж“ҚдҪң(JavaзүҲ)
- жӣҙж–°дәҶпјҒж·ұе…Ҙжө…еҮәеӣҫи§ЈGitпјҢе…Ҙй—ЁеҲ°зІҫйҖҡпјҲдҝқе§Ҷзә§ж•ҷзЁӢпјү第дёүзҜҮ
- жӣҙе…·дёӘжҖ§еҢ–зҡ„й«ҳз«ҜеҶ…еӯҳпјҹZADAK SPARK жөӢиҜ„жҠҘе‘Ҡ
- йӣ¶еҹәзЎҖе…Ҙй—ЁSpark foldж“ҚдҪң(JavaзүҲ)
- ITheatзғӯзӮ№з§‘жҠҖ|жҺЁеҮә新移иҪҙй•ңеӨҙ Spark 2.0 е…үеңҲиҫҫ F2.5пјҢLensbaby
- еҠ зұіи°·еӨ§ж•°жҚ®еј иҖҒеёҲ|еӨ§ж•°жҚ®иҝӣйҳ¶д№ӢSparkиҝҗиЎҢжөҒзЁӢ