唯品会实时平台架构-Flink、Spark、Storm
目前在唯品会实时平台并不是一个统一的计算框架 , 而是包括Storm , Spark , Flink在内的三个主要计算框架 , 这是由于历史原因形成 。
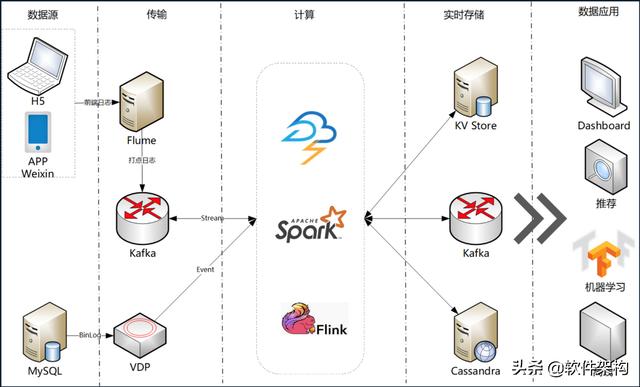
实时平台的职责主要包括实时计算平台和实时基础数据 。 实时计算平台在Storm、Spark、Flink等计算框架的基础上 , 为监控、稳定性提供了保障 , 为业务开发提供了数据的输入与输出 。 实时基础数据包含对上游埋点的定义和规范化 , 对用户行为数据、MySQL的Binlog日志等数据进行清洗、打宽等处理 , 为下游提供质量保证的数据 。
 文章插图
文章插图
在架构设计上 , 包括两大数据源 。 一种是在App、微信、H5等应用上的埋点数据 , 原始数据收集后发送到在kafka中;另一种是线上实时数据的MySQL Binlog日志 。 数据在计算框架里面做清洗关联 , 把原始的数据通过实时ETL为下游的业务应用(包括离线宽表等)提供更易于使用的数据 。
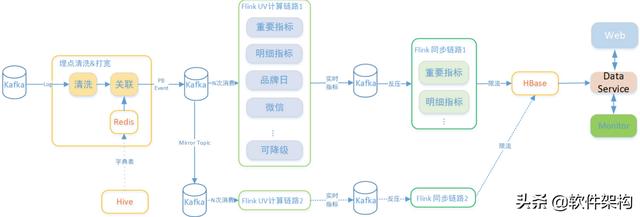
以UV计算为例 , 首先对Kafka内的埋点数据进行清洗 , 然后与Redis数据进行关联 , 关联好的数据写入Kafka中;后续Flink计算任务消费Kafka的关联数据 。 通常任务的计算结果的量也很大(由于计算维度和指标特别多 , 可以达到上千万) , 数据输出通过也是通过Kafka作为缓冲 , 最终使用同步任务同步到HBase中 , 作为实时数据展示 。
同步任务会对写入HBase的数据限流和同类型的指标合并 , 保护HBase 。 与此同时还有另一路计算方案作为容灾 。
 文章插图
文章插图
原文链接:
Apache Flink 在唯品会的实践
【唯品会实时平台架构-Flink、Spark、Storm】
推荐阅读










![新华网|德国法兰克福“跳蚤市场”重新开放[组图]](https://mz.eastday.com/16510358.jpeg)





- 运动计数开发项目的对抗赛:飞算全自动软件工程平台碾压传统模式
- 虾米音乐正式宣告关停:国内音乐平台终告别“三国杀”,TME一家独大或将持续
- 人瑞人才(06919):未来3年系统平台将发力智能化,打造职业生态链平台
- 影像旗舰vivo X60系列正式开售 斩获多个线上平台双冠军
- 威刚为英特尔12代Alder Lake平台准备了64GB DDR5-8400内存模组
- 2020百度地图生态大会:开放平台十周年 为行业送出多个解决方案“大礼包”
- vivo新机亮相跑分平台 配8GB内存搭载天玑820芯片
- 不再是特例:Facebook将在平台上禁掉乔治亚州的政治广告
- 当AI从虚拟走向现实:大规模行业应用加速 开放AI平台成趋势
- 阿里云AIoT启动“堡垒行动”企业物联网平台年内覆盖1万家客户