ж·ұе…Ҙжө…еҮәSparkпјҲдәҢпјүпјҡиЎҖз»ҹпјҲDAGпјү( еӣӣ )
RDD зҡ„ 5 еӨ§еұһжҖ§еҸҠе…¶еҗ«д№ү
е…¶дёӯ第дёҖеӨ§еұһжҖ§ dependencies еҸҲеҸҜд»Ҙз»ҶеҲҶдёә NarrowDependency е’Ң ShuffleDependency пјҢ NarrowDependency еҸҲеҗҚвҖңзӘ„дҫқиө–вҖқ пјҢ е®ғиЎЁзӨә RDD жүҖдҫқиө–зҡ„ж•°жҚ®ж— йңҖеҲҶеҸ‘ пјҢ еҹәдәҺеҪ“еүҚзҺ°жңүзҡ„ж•°жҚ®еҲҶзүҮжү§иЎҢ compute еұһжҖ§е°ҒиЈ…зҡ„еҮҪж•°еҚіеҸҜпјӣShuffleDependency еҲҷдёҚ然 пјҢ е®ғиЎЁзӨә RDD дҫқиө–зҡ„ж•°жҚ®еҲҶзүҮйңҖиҰҒе…ҲеңЁйӣҶзҫӨеҶ…еҲҶеҸ‘ пјҢ 然еҗҺжүҚиғҪжү§иЎҢ RDD зҡ„ compute еҮҪж•°е®ҢжҲҗи®Ўз®— гҖӮ еӣ жӯӨ пјҢ RDD д№Ӣй—ҙзҡ„иҪ¬жҚўжҳҜеҗҰеҸ‘з”ҹ Shuffle пјҢ еҸ–еҶідәҺеӯҗ RDD зҡ„дҫқиө–зұ»еһӢ пјҢ еҰӮжһңдҫқиө–зұ»еһӢдёә ShuffleDependency пјҢ йӮЈд№Ҳ DAGScheduler еҲӨе®ҡпјҡдәҢиҖ…зҡ„иҪ¬жҚўдјҡеј•е…Ҙ Shuffle гҖӮ еңЁеӣһжәҜ DAG зҡ„иҝҮзЁӢдёӯ пјҢ дёҖж—Ұ DAGScheduler еҸ‘зҺ° RDD зҡ„дҫқиө–зұ»еһӢдёә ShuffleDependency пјҢ дҫҝдҫқеәҸжү§иЎҢеҰӮдёӢ 3 йЎ№ж“ҚдҪңпјҡ
- жІҝзқҖ Shuffle иҫ№з•Ңзҡ„еӯҗ RDD ж–№еҗ‘еҲӣе»әж–°зҡ„ Stage еҜ№иұЎ
- жҠҠж–°е»әзҡ„ Stage жіЁеҶҢеҲ° DAGScheduler зҡ„ stages зі»еҲ—еӯ—е…ёдёӯ пјҢ иҝҷдәӣеӯ—е…ёз”ЁдәҺеӯҳеӮЁгҖҒи®°еҪ•дёҺ Stage жңүе…ізҡ„зҠ¶жҖҒе’Ңе…ғдҝЎжҒҜ пјҢ д»ҘеӨҮеҗҺз”Ё
- жІҝзқҖеҪ“еүҚ RDD зҡ„зҲ¶ RDD йҒөеҫӘе№ҝеәҰдјҳе…Ҳжҗңзҙўз®—法继з»ӯеӣһжәҜ DAG
 ж–Үз« жҸ’еӣҫ
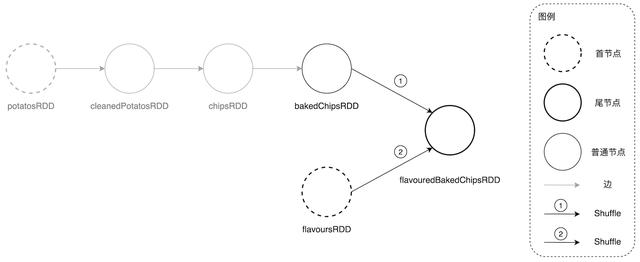
ж–Үз« жҸ’еӣҫDAGScheduler еӣһжәҜ DAG иҝҮзЁӢеҪ“дёӯйҒҮеҲ° ShuffleDependency ж—¶зҡ„дё»иҰҒж“ҚдҪңжөҒзЁӢ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫDAGScheduler жІҝзқҖе°ҫиҠӮзӮ№еӣһжәҜ并еҲ’еҲҶеҮә stage0
еңЁе®ҢжҲҗ第дёҖдёӘ StageпјҲstage0пјүзҡ„еҲӣе»әе’ҢжіЁеҶҢд№ӢеҗҺ пјҢ DAGScheduler е…ҲжІҝзқҖ bakedChipsRDD ж–№еҗ‘继з»ӯеҗ‘еүҚеӣһжәҜ гҖӮ еңЁжІҝзқҖиҝҷжқЎи·Ҝеҗ‘еүҚи·‘зҡ„ж—¶еҖҷ пјҢ жҲ‘们зҡ„иҝҷдҪҚ DAGScheduler еҗ‘еҜје®ҳжғҠе–ңең°еҸ‘зҺ°пјҡвҖңжҲ‘еҺ»пјҒиҝҷдёҖи·ҜдёҠдёҖ马平е·қгҖҒйЈҺжҷҜз”ҡеҘҪ пјҢ еҗ„дёӘй©ҝз«ҷд№Ӣй—ҙд»Җд№ҲйҡңзўҚйғҪжІЎжңү пјҢ дәӨйҖҡз”ҡжҳҜйЎәз•… пјҢ зңҹжҳҜзүҮеҘҪең°еҪўпјҒвҖқвҖ”вҖ” жІҝи·ҜйҒҮеҲ°зҡ„жүҖжңү RDDпјҲbakedChipsRDD пјҢ chipsRDD пјҢ cleanedPotatosRDD пјҢ potatosRDDпјүзҡ„дҫқиө–зұ»еһӢйғҪжҳҜ NarrowDependency гҖӮ
гҖҗж·ұе…Ҙжө…еҮәSparkпјҲдәҢпјүпјҡиЎҖз»ҹпјҲDAGпјүгҖ‘еңЁеӣһжәҜе®ҢжҜ•ж—¶ пјҢ DAGScheduler еҗҢж ·дјҡйҮҚеӨҚдёҠиҝ° 3 дёӘжӯҘйӘӨ пјҢ ж №жҚ® DAGScheduler д»Ҙ Shuffle дёәиҫ№з•ҢеҲ’еҲҶ Stage зҡ„еҺҹеҲҷ пјҢ жІҝйҖ”зҡ„жүҖжңү RDD йғҪеҲ’еҪ’дёәеҗҢдёҖдёӘ Stage пјҢ жҡӮдё”и®°дёә stage1 гҖӮ еҖјеҫ—дёҖжҸҗзҡ„жҳҜ пјҢ Stage еҜ№иұЎзҡ„ rdd еұһжҖ§еҜ№еә”зҡ„ж•°жҚ®зұ»еһӢжҳҜ RDD[] пјҢ иҖҢдёҚжҳҜ List[RDD[]] гҖӮ еҜ№дәҺдёҖдёӘйҖ»иҫ‘дёҠеҢ…еҗ«еӨҡдёӘ RDD зҡ„ Stage жқҘиҜҙ пјҢ е…¶ rdd еұһжҖ§еӯҳеӮЁзҡ„жҳҜи·Ҝеҫ„жң«е°ҫзҡ„ RDD иҠӮзӮ№ пјҢ е…·дҪ“еҲ°жҲ‘们зҡ„жЎҲдҫӢдёӯе°ұжҳҜ bakedChipsRDD гҖӮ
 ж–Үз« жҸ’еӣҫ
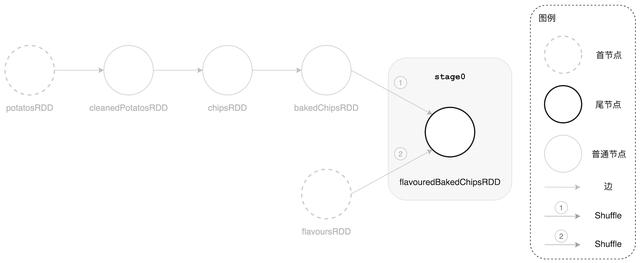
ж–Үз« жҸ’еӣҫDAGScheduler жІҝзқҖ bakedChipsRDD ж–№еҗ‘еӣһжәҜ并еҲ’еҲҶеҮә stage1
еӢӨеӢӨжҒіжҒізҡ„ DAGScheduler еңЁжҲҗеҠҹеҲӣе»ә stage1 д№ӢеҗҺ пјҢ дҫқ然дёҚеҝҳеҲқеҝғгҖҒзүўи®°дҪҝе‘Ҫ пјҢ 继з»ӯеҘ”еҗ‘иҝҳжңӘжҺўзҙўзҡ„и·Ҝзәҝ гҖӮ д»ҺдёҠеӣҫдёӯжҲ‘们清жҘҡең°зңӢеҲ°ж•ҙеқ—ең°еҪўиҝҳеү©дёӢ flavoursRDD ж–№еҗ‘зҡ„и·Ҝеҫ„жІЎжңүзәіе…Ҙ DAGScheduler зҡ„и§ҶйҮҺиҢғеӣҙ гҖӮ е’ұ们зҡ„иҝҷдҪҚ DAGScheduler еҗ‘еҜје®ҳи®°жҖ§зӣёеҪ“еҫ—еҘҪ пјҢ ж—©еңЁеҲ’еҲҶ stage0 зҡ„ж—¶еҖҷ пјҢ д»–е°ұз”Ёе°Ҹжң¬еӯҗпјҲж Ҳпјүи®°дёӢпјҡвҖңжӯӨи·ҜеҸЈжңүеҲҶеҸү пјҢ е…ҲжІҝзқҖ bakedChipsRDD ж–№еҗ‘иө° пјҢ 然еҗҺеҶҚеӣһиҝҮеӨҙжқҘжІҝзқҖ flavoursRDD зҡ„ж–№еҗ‘жҺўзҙў гҖӮ еҲҮи®° пјҢ еҲҮи®°пјҒвҖқжӯӨж—¶ пјҢ еҗ‘еҜјеӨ§дәәжӢҝеҮәд№ӢеүҚзҡ„е°Ҹжң¬еӯҗ пјҢ з”ЁжЁӘзәҝжҠҠ bakedChipsRDD ж–№еҗ‘зҡ„и·Ҝеҫ„еҲ’жҺү вҖ”вҖ” иЎЁзӨәиҜҘж–№еҗ‘и·Ҝеҫ„е·ІжҺўзҙўиҝҮ пјҢ 然еҗҺжІҝзқҖ flavoursRDD ж–№еҗ‘еӨ§иёҸжӯҘең°иө°дёӢеҺ» гҖӮ дёҖи„ҡдёӢеҺ» пјҢ еҸ‘зҺ°пјҡвҖңжҲ‘еҺ»пјҒеҲ°еӨҙе„ҝдәҶпјҒвҖқ пјҢ 然еҗҺзҙ§жҺҘзқҖжү§иЎҢдёҖиҙҜзҡ„вҖңдёүжӢӣдёҖеҘ—вҖқжөҒзЁӢ вҖ”вҖ” еҲӣе»ә StageгҖҒжіЁеҶҢ StageгҖҒ继з»ӯеӣһжәҜ гҖӮ йҡҸзқҖ DAGScheduler еҲӣе»әжңҖеҗҺдёҖдёӘ Stageпјҡstage2 пјҢ ең°еҪўдёҠзҡ„жүҖжңүи·Ҝеҫ„йғҪе·ІжҺўзҙўе®ҢжҜ• гҖӮ
жҺЁиҚҗйҳ…иҜ»














- иӢұдә§иЎҖз»ҹ зәҜжӯЈйҹіиүІ RHA TrueConnect2зңҹж— зәҝи“қзүҷиҖіжңә
- йӣ¶еҹәзЎҖе…Ҙй—ЁSpark groupByж“ҚдҪң(JavaзүҲ)
- е”Ҝе“Ғдјҡе®һж—¶е№іеҸ°жһ¶жһ„-FlinkгҖҒSparkгҖҒStorm
- д»Һ0еҲ°1иҝӣиЎҢSpark historyеҲҶжһҗ
- йӣ¶иҝӣзЁӢе…Ҙй—ЁSpark keyByж“ҚдҪң(JavaзүҲ)
- жӣҙж–°дәҶпјҒж·ұе…Ҙжө…еҮәеӣҫи§ЈGitпјҢе…Ҙй—ЁеҲ°зІҫйҖҡпјҲдҝқе§Ҷзә§ж•ҷзЁӢпјү第дёүзҜҮ
- жӣҙе…·дёӘжҖ§еҢ–зҡ„й«ҳз«ҜеҶ…еӯҳпјҹZADAK SPARK жөӢиҜ„жҠҘе‘Ҡ
- йӣ¶еҹәзЎҖе…Ҙй—ЁSpark foldж“ҚдҪң(JavaзүҲ)
- ITheatзғӯзӮ№з§‘жҠҖ|жҺЁеҮә新移иҪҙй•ңеӨҙ Spark 2.0 е…үеңҲиҫҫ F2.5пјҢLensbaby
- еҠ зұіи°·еӨ§ж•°жҚ®еј иҖҒеёҲ|еӨ§ж•°жҚ®иҝӣйҳ¶д№ӢSparkиҝҗиЎҢжөҒзЁӢ