语法数据扩增提升推理启发法的鲁棒性( 六 )
 文章插图
文章插图
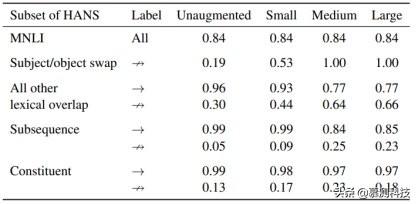
表 A.3:使用主语/宾语倒置结合转换假设的数据扩增对 HANS 准确性的影响 。 图表展示了在使用三种扩增集大小(101 , 405 , 1215 个实例)来扩增的 MNLI 训练集后 BERT 的微调结果 , 也展示了在未经扩增的 MNLI 训练集上 BERT 的微调结果 。
 文章插图
文章插图
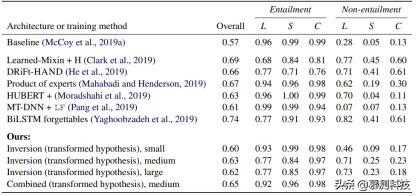
表 A.4:不同的架构与训练方式所得到的 HANS 准确率 , 其被按照实例诊断的启发法与实例明确的标签拆分开来 。 除了 MT-DNN+LF 外 , 其余均采用了 BERT 作为基本模型 。 L , S 与 C 分别代表词汇重叠、子序列和成分启发法 。 扩增集的大小为 n=101(小型) , n=405(中型) , n=1215(大型) 。
 文章插图
文章插图
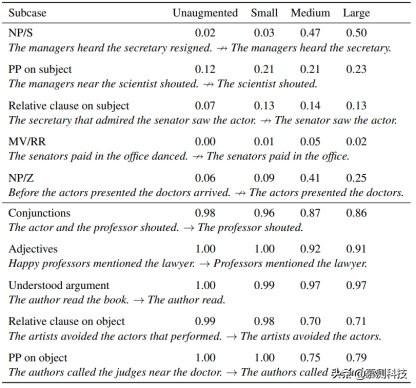
表 A.5:主语/宾语倒置结合转换假设:图表展示了 HANS 子案例在诊断为词法重叠启发法时的结果 , 这些案例包括四种训练方案-未经扩增(只在 MNLI 上进行训练) , 和小型(n=101) , 中型(n=405) , 大型(n=1215)扩增集的情况 。 置信准确度为 0.5 。 图表上半部分:标签是非蕴含的案例情况 。 图表下半部分:标签是蕴含的案例情况 。
 文章插图
文章插图
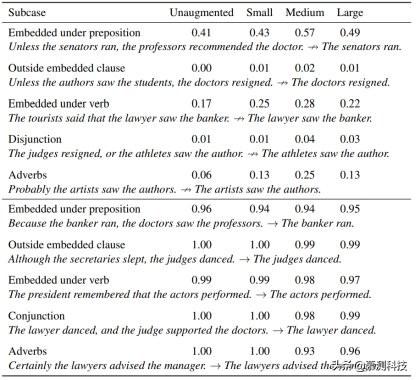
表 A.6:主语/宾语倒置结合转换假设:图表展示了 HANS 子案例在诊断为子序列启发法时的结果 , 这些案例包括四种训练方案-未经扩增(只在 MNLI 上进行训练) , 和小型(n=101) , 中型(n=405) , 大型(n=1215)扩增集的情况 。 图表上半部分:标签是非蕴含的案例情况 。 图表下半部分:标签是蕴含的案例情况 。
 文章插图
文章插图
表 A.7:主语/宾语倒置结合转换假设:图表展示了 HANS 子案例在诊断为成分启发法时的结果 , 这些案例包括四种训练方案-未经扩增(只在 MNLI 上进行训练) , 和小型(n=101) , 中型(n=405) , 大型(n=1215)扩增集的情况 。 置信准确度为 0.5 。 图表上半部分:标签是非蕴含的案例情况 。 图表下半部分:标签是蕴含的案例情况 。
【语法数据扩增提升推理启发法的鲁棒性】本论文由 iSE 实验室 2021 级学生刘关迪转述 。
推荐阅读


![[他人婚]被曝插足他人婚姻 《青你2》选手申冰退赛](https://img3.utuku.china.com/550x0/toutiao/20200326/5961a705-f613-40cd-b825-bc7656e59cfc.jpg)













- 西部数据在CES 2021推出多款4TB容量的旗舰级SSD
- WhatsApp收集用户数据新政惹众怒,“删除WhatsApp”在土耳其上热搜
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能
- HDMI 2.1诞生三年:超高速数据线落地 8K电视圆满了