语法数据扩增提升推理启发法的鲁棒性( 五 )
? 最后 , 我们希望能有一个在各语言理解任务中能对使用语法方面具有强归纳偏差的模型 , 即使在重叠启发法导致其在训练集上的高精度时也是如此 。 事实上 , 很难想象人们在理解一个句子时会完全忽略语法 。 另一种可选的方法是创建足以代表各种语言现象的训练集;众包工作者(理性的人)偏爱使用尽可能简单的生成策略 , 这可以通过对抗性过滤等方法来抵消(Nie et al., 2019) 。 然而 , 在此期间 , 我们得出结论 , 数据扩增是一个简单而有效的策略 , 其可以缓解 BERT 等模型中已知的推理启发法 。
A. 附录A.1 微调细节我们在所有实验中都使用了 bert-base-uncased 版本的模型 。 按照标准 , 我们通过在 MNLI 上训练线性分类器从 CLS 标记的最终层嵌入预测标签 , 同时继续更新 BERT 参数 , 来对该预训练模型进行微调(Devlin et al., 2019) 。 每个模型的训练实例顺序都进行了打乱 。 所有模型都经过了三个 epoch 的训练 。
A.2 生成扩增实例? 以下列表描述了我们使用的扩增策略 。 表 A.1 说明了应用于特定原句的所有策略 。 注意 , 倒置通常会改变句子的含义(侦探跟随着嫌疑犯(the detective followed the suspect)与嫌疑犯跟随着侦探(the suspect followed the detective)描述的并不是一个场景) , 但是被动语句并不会(侦探跟随着嫌疑犯(the detective followed the suspect)与嫌疑犯被侦探跟随(the suspect was followed by the detective)描述的是同一个场景) 。
 文章插图
文章插图
? 我们使用 MNLI 提供的选区分析 , 识别出 MNLI 中可以作为原句的及物句 , 但噪声较大的 TELEPHONE 类型除外 。 为此 , 我们搜索了恰好带有 VP 的一个 NP 子节点的矩阵 S 节点 , 其中主宾都是完整的名词短语(即 , 都不是像 me 这样的人称代词) , 而动词词缀不是 be 或 have 。 我们保留了动词的原始时态 , 并在必要时修改了他们的一致性特征 。 (如:电影是 Matt Dillon 和 Gary Sinise 出演(the movie stars Matt Dillon and Gary Sinise)改为 Matt Dillon 和 Gary Sinise 出演了这部电影(Matt Dillon and Gary Sinise star the movie)) 。
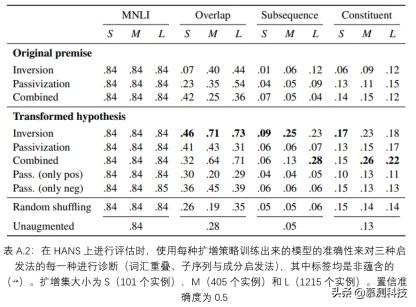
? 所有策略中 , 最大的扩增集大小为 1215 。 这个大小是我们可以从 MNLI 生成的最大扩增数据集确定的 , 该数据集是使用了上述的倒置结合原始前提方法 。 为了公平比较 , 即使对于可以生成更大数据集的策略 , 我们仍保持相同的大小 。 我们还通过随机抽样 405 个使用上述过程识别的案例创造了中型数据集 , 以及包含了 101 个实例的小数据集 。 我们对于每种策略仅执行一次这个过程:因此 , 运行过程仅在分类器的权重初始化和实例顺序方面有所不同 , 而在训练中包含的扩增实例没有变化 。
为了创建组合的扩增数据集 , 我们将倒置和被动化的数据集进行串联 , 然后随机丢掉一半实例(以使组合数据集的大小与其他数据集相匹配) 。 与其他数据集一样 , 我们只执行了一次:合并的扩增集在每次运行中相同 。 该过程的一个结果是 , 倒置和被动化的实例数量不完全相同 。
A.3 详细结果下列图表提供了我们试验的详细结果 。
 文章插图
文章插图
最后 , 末尾三个表格详细说明了通过倒置结合转换假设来对 30 个 HANS 子案例进行扩增的效果 , 并按设计依据诊断启发法来细分成表:词汇重叠启发法(表 A.5);子序列启发法(表 A.6)和成分启发法(表 A.7) 。
 文章插图
文章插图
表 A.1:语法扩充策略(完整表格)
 文章插图
文章插图
推荐阅读


![[他人婚]被曝插足他人婚姻 《青你2》选手申冰退赛](https://img3.utuku.china.com/550x0/toutiao/20200326/5961a705-f613-40cd-b825-bc7656e59cfc.jpg)













- 西部数据在CES 2021推出多款4TB容量的旗舰级SSD
- WhatsApp收集用户数据新政惹众怒,“删除WhatsApp”在土耳其上热搜
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能
- HDMI 2.1诞生三年:超高速数据线落地 8K电视圆满了