语法数据扩增提升推理启发法的鲁棒性( 四 )
 文章插图
文章插图
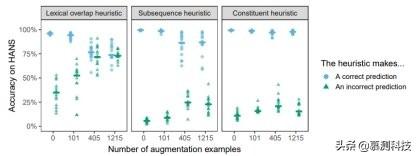
图 2:使用主语/宾语倒置与转换假设结合进行扩增 。 点表示对每种启发法进行 HANS 实例诊断的准确度 , 这是由在 MNLI 上微调的 15 次 BERT 运行与每个扩增的数据集相结合所得到的 。 水平条表示整体运行的中位数准确度 。
? 现在 , 我们来更详细地分析最有效的策略 , 即倒置结合转换假设 。 首先 , 该策略在抽象层面上与 HANS 的主语/宾语交换类别相似 , 但是两者的词汇与语法特性均有不同 。 尽管存在这些差异 , 但模型在 HANS 类别上的表现在中型与大型扩增条件下都是完美的(1.00) , 这表明 BERT 能从转换的高级语法结构中受益 。 对于小的扩增集 , 此类别的准确性为 0.53 , 表明有 101 个实例不足以使 BERT 知道不能随意的交换主语与宾语的对象 。 相反 , 将扩增大小从中型变至大型 , 能在 HANS 的子案例中产生适度且易变的效果(见附录 A.3 了解具体个案的结果);为了更清楚的了解扩增大小的影响 , 可能还需要对该参数进行更密集的采样 。
? 尽管倒置是该扩充集中的唯一转换 , 但是除了主语/宾语交换之外 , 其他结构的性能也得到了显著的提高(图 2);例如 , 模型能够更好地处理包含介词短语的实例 , 例如 , 经理背后的法官看医生(The judge behind the manager saw the doctors)并非蕴含医生看经理(The doctors saw the manager) , (未扩增:0.41;大型扩增:0.89) 。 在以子序列启发法为目标的案例中 , 有一个更平缓 , 但仍然十分明显的提升;这种较小程度的提升表明 , 对连续子序列从词汇重叠中分离处理更具泛化性 。 一个例外是对“NP/S”推论的准确性 , 例如
 文章插图
文章插图
, 这一准确度从 0.02(未扩增)大幅提升至 0.5(大型扩增) 。 因此 , 对子序列案例的进一步改进可能需要涉及子序列的数据扩增 。
在过去的一年中 , 人们提出了一系列技术来提高 HANS 的性能 。 这些模型包括语法感知模型(Moradshahi et al., 2019; Pang et al., 2019) , 旨在捕获预定义浅层启发法的辅助模型 , 以使主模型可以专注于稳健策略(Clark et al., 2019; He et al., 2019; Mahabadi and Henderson, 2019)以及提高难度训练实例权重的方法(Yaghoobzadeh et al., 2019) 。 尽管其中的一些方法在 HANS 上比我们的方法具有更高的准确性 , 包括更好的泛化了成分和子序列的情况(参见表 A.4) , 但它们并不具有直接的可比性:我们的目标是在不修改模型或训练程序的情况下 , 评估训练集中的具有语法挑战性的实例是如何影响 BERT 的 NLI 的表现的 。
6. 讨论? 我们最佳效果的策略是通过对 MNLI 实例的主语/宾语倒置转换而生成的少量 MNLI 实例来扩增 MNLI 训练集 。 这产生了可观的泛化能力:既是对另一个域而言的(HANS 挑战集) , 更重要的是 , 其也适用于其他结构 , 如关系从句和介词短语 。 这支持了缺失连接假设:对一个结构进行少量扩增会引起抽象的语法敏感性 , 而不是仅仅通过为模型建立来自同一分布的案例样本来“接种(inoculating)”模型 , 以防止在挑战集上失败(Liu et al., 2019) 。
? 同时 , 倒置转换并未完全抵消启发法 , 特别是 , 这些模型在被动句上的表现较差 。 因此 , 对于这些结构 , BERT 的预训练可能在通过一个较小的扩增后 , 也仍无法产生强有力的语法表现形式;换句话说 , 这可能是我们的代表性不足假设成立的情况 。 该假设预测 , 作为单词预测模型的预训练 BERT 对于被动词处理困难 , 并且可能需要专门针对 NLI 任务学习其对应结构的特性;这可能需要大量的扩增实例 。
? 表现最佳的扩增策略是从一个单独原句生成前提/假设对 , 这意味着该策略不依赖于 NLI 语料库 。 我们可以从任何语料库生成扩增实例 , 这使得我们有可能测试非常大的扩增集是否有效(当然 , 请注意 , 来自不同领域的扩增语句可能会影响在 MNLI 上本身的表现) 。
推荐阅读


![[他人婚]被曝插足他人婚姻 《青你2》选手申冰退赛](https://img3.utuku.china.com/550x0/toutiao/20200326/5961a705-f613-40cd-b825-bc7656e59cfc.jpg)













- 西部数据在CES 2021推出多款4TB容量的旗舰级SSD
- WhatsApp收集用户数据新政惹众怒,“删除WhatsApp”在土耳其上热搜
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能
- HDMI 2.1诞生三年:超高速数据线落地 8K电视圆满了