基于关系推理的自监督学习无标记训练( 二 )
让我们来讨论一下关系推理系统某些部分的要点:
- 小批量增强
- 内部推理由对同一对象{A1; A2}(正对)(例如 , 同一篮球的不同视角)
- 交互推理包括耦合两个随机对象{A1; B1}(负对)(例如带随机球的篮球)
例如 , 在{foot ball , basket ball}对中 , 颜色本身就可以很好地预测类 。 然而 , 随着颜色和形状大小的随机变化 , 学习者现在很难区分这两种颜色之间的差异 。 学习者必须考虑另一个特征 , 因此 , 它可以提供更好的表示 。
- 度量学习
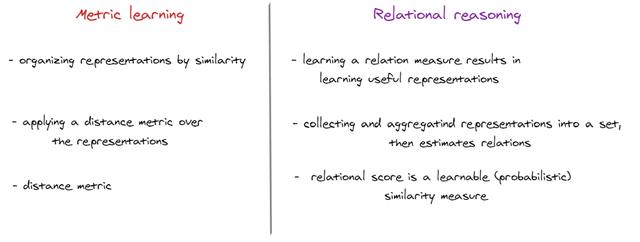 文章插图
文章插图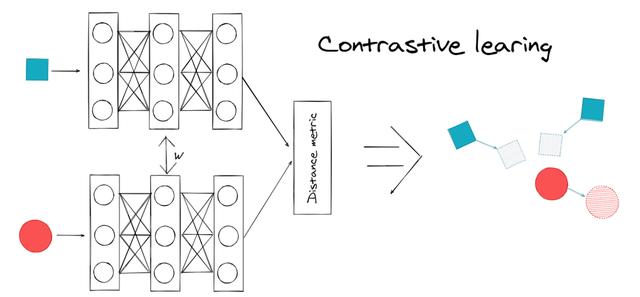 文章插图
文章插图 文章插图
文章插图- 损失函数
 文章插图
文章插图最后 , 本文[6]还提供了在标准数据集(CIFAR-10、CIFAR-100、CIFAR-100-20、STL-10、tiny-ImageNet、SlimageNet)、不同主干(浅层和深层)、相同的学习进度(epochs)上的关系推理结果 。 结果如下 , 欲了解更多信息 , 请查阅他的论文 。
实验评估在本文中 , 我想在公共图像数据集STL-10上重现关系推理系统 。 该数据集由10个类(飞机、鸟、汽车、猫、鹿、狗、马、猴、船、卡车)组成 , 颜色为96x96像素 。
首先 , 我们需要导入一些重要的库
import torchimport torchvisionimport torchvision.transforms as transformsfrom PIL import Imageimport mathimport timefrom torch.utils.data import DataLoaderfrom time import sleepfrom tqdm import tqdmimport numpy as npfrom fastprogress.fastprogress import master_bar, progress_barfrom torchvision import modelsimport matplotlib.pyplot as pltfrom torchvision.utils import make_grid%config InlineBackend.figure_format = 'svg'STL-10数据集包含1300个标记图像(500个用于训练 , 800个用于测试) 。 然而 , 它也包括100000个未标记的图像 , 这些图像来自相似但更广泛的分布 。 例如 , 除了标签集中的动物外 , 它还包含其他类型的动物(熊、兔子等)和车辆(火车、公共汽车等) 文章插图
文章插图然后根据作者的建议创建关系推理类
class RelationalReasoning(torch.nn.Module):"""自监督关系推理 。方法的基本实现 , 它使用“cat”聚合函数(最有效) ,可与任何主干一起使用 。"""def __init__(self, backbone, feature_size=64):super(RelationalReasoning, self).__init__()self.backbone = backbone.to(device)self.relation_head = torch.nn.Sequential(torch.nn.Linear(feature_size*2, 256),torch.nn.BatchNorm1d(256),torch.nn.LeakyReLU(),torch.nn.Linear(256, 1)).to(device)def aggregate(self, features, K):relation_pairs_list = list()targets_list = list()size = int(features.shape[0] / K)shifts_counter=1for index_1 in range(0, size*K, size):for index_2 in range(index_1+size, size*K, size):# 默认情况下使用“cat”聚合函数pos_pair = torch.cat([features[index_1:index_1+size],features[index_2:index_2+size]], 1)# 通过滚动小批无碰撞的洗牌(负)neg_pair = torch.cat([features[index_1:index_1+size],torch.roll(features[index_2:index_2+size],shifts=shifts_counter, dims=0)], 1)relation_pairs_list.append(pos_pair)relation_pairs_list.append(neg_pair)targets_list.append(torch.ones(size, dtype=torch.float32))targets_list.append(torch.zeros(size, dtype=torch.float32))shifts_counter+=1if(shifts_counter>=size):shifts_counter=1 # avoid identity pairsrelation_pairs = torch.cat(relation_pairs_list, 0)targets = torch.cat(targets_list, 0)return relation_pairs.to(device), targets.to(device)def train(self, tot_epochs, train_loader):optimizer = torch.optim.Adam([{'params': self.backbone.parameters()},{'params': self.relation_head.parameters()}])BCE = torch.nn.BCEWithLogitsLoss()self.backbone.train()self.relation_head.train()mb = master_bar(range(1, tot_epochs+1))for epoch in mb:# 实际目标被丢弃(无监督)train_loss = 0accuracy_list = list()for data_augmented, _ in progress_bar(train_loader, parent=mb):K = len(data_augmented) # tot augmentationsx = torch.cat(data_augmented, 0).to(device)optimizer.zero_grad()# 前向传播(主干)features = self.backbone(x)# 聚合函数relation_pairs, targets = self.aggregate(features, K)# 前向传播 (关系头)score = self.relation_head(relation_pairs).squeeze()# 交叉熵损失与向后传播loss = BCE(score, targets)loss.backward()optimizer.step()train_loss += loss.item()*Kpredicted = torch.round(torch.sigmoid(score))correct = predicted.eq(targets.view_as(predicted)).sum()accuracy = (correct / float(len(targets))).cpu().numpy()accuracy_list.append(accuracy)epoch_loss = train_loss / len(train_loader.sampler)epoch_accuracy = sum(accuracy_list)/len(accuracy_list)*100mb.write(f"Epoch [{epoch}/{tot_epochs}] - Accuracy: {epoch_accuracy:.2f}% - Loss: {epoch_loss:.4f}")
推荐阅读
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 华硕基于WRX80的主板现身 为AMD Ryzen Threadripper Pro打造
- 微软新版电子邮件客户端截图曝光:基于网页端Outlook
- 曝光 | 小鹏或春节前推送NGP更新,基于高精地图可自动变道
- 基于Spring+Angular9+MySQL开发平台
- 14款华为手机/平板公测EMUI 11:全部基于麒麟980
- AI赋能,让消防、用电更“智慧”
- 荷兰职员哭泣:中国明明说好自研光刻机,却跟日本尼康扯上关系
- 基于安卓11打造!魅族17系列将升级全新Flyme 8
- 谷歌为用户提供了基于AR的虚拟化妆体验
- 挺进云端AI训练&推理双赛道!独家对话燧原科技COO张亚林:揭秘超高效率背后的“内功”




![[唐小姐美食记]立夏将至,这6种时令蔬菜吃起来,价格不贵营养高,比大鱼大肉好](http://ttbs.guangsuss.com/image/5959a505c1018e78d7432b8a16b0f427)









