йҮ‘иһҚеёӮеңәдёӯзҡ„NLPвҖ”вҖ”жғ…ж„ҹеҲҶжһҗ( дәҢ )
## иҫ“е…Ҙж–Үжң¬зӨәдҫӢpositive "Finnish steel maker Rautaruukki Oyj ( Ruukki ) said on July 7 , 2008 that it won a 9.0 mln euro ( $ 14.1 mln ) contract to supply and install steel superstructures for Partihallsforbindelsen bridge project in Gothenburg , western Sweden."neutral "In 2008 , the steel industry accounted for 64 percent of the cargo volumes transported , whereas the energy industry accounted for 28 percent and other industries for 8 percent."negative "The period-end cash and cash equivalents totaled EUR6 .5 m , compared to EUR10 .5 m in the previous year." ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иҜ·жіЁж„Ҹ пјҢ жүҖжңүж•°жҚ®йғҪеұһдәҺжқҘжәҗ пјҢ з”ЁжҲ·еҝ…йЎ»йҒөе®Ҳе…¶зүҲжқғе’Ңи®ёеҸҜжқЎж¬ҫ гҖӮ
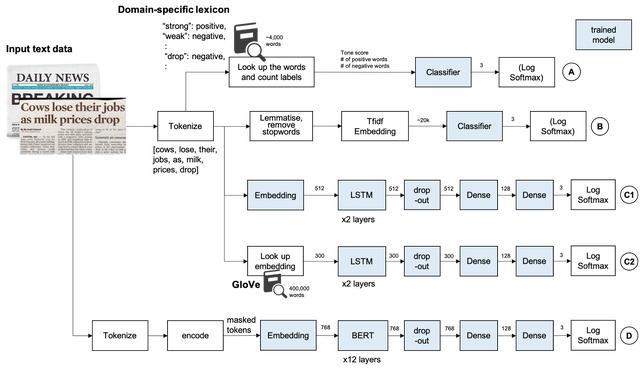
жЁЎеһӢдёӢйқўжҳҜжҲ‘жҜ”иҫғдәҶеӣӣж¬ҫжЁЎеһӢзҡ„жҖ§иғҪ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
AгҖҒ еҹәдәҺиҜҚжұҮзҡ„ж–№жі•еҲӣе»әзү№е®ҡдәҺйўҶеҹҹзҡ„иҜҚе…ёжҳҜдёҖз§Қдј з»ҹзҡ„ж–№жі• пјҢ еңЁжҹҗдәӣжғ…еҶөдёӢ пјҢ еҰӮжһңжәҗд»Јз ҒжқҘиҮӘзү№е®ҡзҡ„дёӘдәәжҲ–еӘ’дҪ“ пјҢ еҲҷиҝҷз§Қж–№жі•з®ҖеҚ•иҖҢејәеӨ§ гҖӮ Loughranе’ҢMcDonaldжғ…ж„ҹиҜҚеҲ—иЎЁ гҖӮ иҝҷдёӘеҲ—иЎЁеҢ…еҗ«и¶…иҝҮ4kдёӘеҚ•иҜҚ пјҢ иҝҷдәӣеҚ•иҜҚеҮәзҺ°еңЁеёҰжңүжғ…з»Әж Үзӯҫзҡ„иҙўеҠЎжҠҘиЎЁдёҠ гҖӮ жіЁпјҡжӯӨж•°жҚ®йңҖиҰҒи®ёеҸҜиҜҒжүҚиғҪз”ЁдәҺе•Ҷдёҡеә”з”Ё гҖӮ иҜ·еңЁдҪҝз”ЁеүҚжЈҖжҹҘ他们зҡ„зҪ‘з«ҷ гҖӮ
## ж ·жң¬negative: ABANDONnegative: ABANDONEDconstraining: STRICTLYжҲ‘з”ЁдәҶ2355дёӘж¶ҲжһҒеҚ•иҜҚе’Ң354дёӘз§ҜжһҒеҚ•иҜҚ гҖӮ е®ғеҢ…еҗ«еҚ•иҜҚеҪўејҸ пјҢ еӣ жӯӨдёҚиҰҒеҜ№иҫ“е…Ҙжү§иЎҢиҜҚе№ІеҲҶжһҗе’ҢиҜҚе№ІеҢ– гҖӮ еҜ№дәҺиҝҷз§Қж–№жі• пјҢ иҖғиҷ‘еҗҰе®ҡеҪўејҸжҳҜеҫҲйҮҚиҰҒзҡ„ гҖӮ жҜ”еҰӮnot пјҢ no пјҢ don пјҢ зӯүзӯү гҖӮ иҝҷдәӣиҜҚдјҡжҠҠеҗҰе®ҡиҜҚзҡ„ж„ҸжҖқж”№дёәиӮҜе®ҡзҡ„ пјҢ еҰӮжһңеүҚйқўдёүдёӘиҜҚдёӯжңүеҗҰе®ҡиҜҚ пјҢ иҝҷйҮҢжҲ‘з®ҖеҚ•ең°жҠҠеҗҰе®ҡиҜҚзҡ„ж„ҸжҖқиҪ¬жҚўжҲҗиӮҜе®ҡиҜҚ гҖӮ
然еҗҺ пјҢ жғ…ж„ҹеҫ—еҲҶе®ҡд№үеҰӮдёӢ гҖӮ
tone_score = 100 * (pos_count вҖ” neg_count) / word_countз”Ёй»ҳи®ӨеҸӮж•°и®ӯз»ғ14дёӘдёҚеҗҢзҡ„еҲҶзұ»еҷЁ пјҢ 然еҗҺз”ЁзҪ‘ж јжҗңзҙўдәӨеҸүйӘҢиҜҒжі•еҜ№йҡҸжңәжЈ®жһ—иҝӣиЎҢи¶…еҸӮж•°ж•ҙе®ҡ гҖӮ
classifiers = []classifiers.append(("SVC", SVC(random_state=random_state)))classifiers.append(("DecisionTree", DecisionTreeClassifier(random_state=random_state)))classifiers.append(("AdaBoost", AdaBoostClassifier(DecisionTreeClassifier(random_state=random_state),random_state=random_state,learning_rate=0.1)))classifiers.append(("RandomForest", RandomForestClassifier(random_state=random_state, n_estimators=100)))classifiers.append(("ExtraTrees", ExtraTreesClassifier(random_state=random_state)))classifiers.append(("GradientBoosting", GradientBoostingClassifier(random_state=random_state)))classifiers.append(("MultipleLayerPerceptron", MLPClassifier(random_state=random_state)))classifiers.append(("KNeighboors", KNeighborsClassifier(n_neighbors=3)))classifiers.append(("LogisticRegression", LogisticRegression(random_state = random_state)))classifiers.append(("LinearDiscriminantAnalysis", LinearDiscriminantAnalysis()))classifiers.append(("GaussianNB", GaussianNB()))classifiers.append(("Perceptron", Perceptron()))classifiers.append(("LinearSVC", LinearSVC()))classifiers.append(("SGD", SGDClassifier()))cv_results = []for classifier in classifiers :cv_results.append(cross_validate(classifier[1], X_train, y=Y_train, scoring=scoring, cv=kfold, n_jobs=-1))# дҪҝз”ЁйҡҸжңәжЈ®жһ—еҲҶзұ»еҷЁrf_clf = RandomForestClassifier()# жү§иЎҢзҪ‘ж јжҗңзҙўparam_grid = {'n_estimators': np.linspace(1, 60, 10, dtype=int),'min_samples_split': [1, 3, 5, 10],'min_samples_leaf': [1, 2, 3, 5],'max_features': [1, 2, 3],'max_depth': [None],'criterion': ['gini'],'bootstrap': [False]}model = GridSearchCV(rf_clf, param_grid=param_grid, cv=kfold, scoring=scoring, verbose=verbose, refit=refit, n_jobs=-1, return_train_score=True)model.fit(X_train, Y_train)rf_best = model.best_estimator_
жҺЁиҚҗйҳ…иҜ»

















- жҹ”жҖ§з”өеӯҗеёӮеңәе№ҝйҳ”пјҢйўҶеӨҙзҫҠжҹ”е®Ү科жҠҖиҺ·жӣҙеӨҡе…іжіЁ
- Eyeware BeamдҪҝз”ЁiPhoneиҝҪиёӘзҺ©е®¶еңЁжёёжҲҸдёӯзҡ„зңјзқӣиҝҗеҠЁ
- еҸҲзҲҶзӮёпјҒиҒ”з”ө科жҠҖдј жқҘдёҖеЈ°е·Ёе“ҚпјҢжҲ–жҠҠ8 иӢұеҜёжҷ¶еңҶеёӮеңә"зӮё"дәҶ
- зәҝдёӢеёӮеңәеҪ»еә•вҖңд№ұдәҶвҖқпјҒе°Ҹзұіе®Јеёғ新规пјҒеҚҺдёәжҚҶз»‘еҠ д»·иЎҢдёәиҝҺдәүи®®
- и…ҫи®ҜжёёжҲҸеҸ‘иө·еҜ№еҚҺдёәзҡ„жҢ‘жҲҳпјҢжҲ–еӣ еҗҺиҖ…еҜ№еӣҪеҶ…жүӢжңәеёӮеңәзҡ„еҪұе“ҚеҠӣеӨ§и·Ң
- еҚҺдёәP50 ProжёІжҹ“еӣҫжӣқе…үпјҡжӣІйқўзҖ‘еёғеұҸ
- иӢ№жһңдёӯеӣҪеҢәдёӢжһ¶иҝ‘5дёҮж¬ҫжёёжҲҸеә”з”ЁпјҢжүӢжёёеёӮеңәйқўдёҙеӨ§жҙ—зүҢ
- иҪ¬иҪ¬пјҡiPhone 12зғӯй”Җ дәҢжүӢеёӮеңә5GжүӢжңәдәӨжҳ“зңӢж¶Ё
- еёӮеңә|iPhoneXз”ЁжҲ·йӣҶдёӯеҚ–жүӢжңәпјҹиҪ¬иҪ¬Q4жүӢжңәиЎҢжғ…пјҡiPhone12еј•йўҶ5GжҚўжңәжҪ®
- OPPOиҘҝ欧еҮәиҙ§йҮҸеҺ»е№ҙеўһй•ҝдёүеҖҚ й«ҳз«ҜеёӮеңәжҲҗеӨҙйғЁеҺӮе•Ҷеҝ…дәүд№Ӣең°