йҮ‘иһҚеёӮеңәдёӯзҡ„NLPвҖ”вҖ”жғ…ж„ҹеҲҶжһҗ( дә” )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
з”ұдәҺиҫ“е…Ҙж•°жҚ®дёҚе№іиЎЎ пјҢ еӣ жӯӨиҜ„дј°д»ҘF1еҲҶж•°дёәеҹәзЎҖ пјҢ еҗҢж—¶д№ҹеҸӮиҖғдәҶеҮҶзЎ®жҖ§ гҖӮ
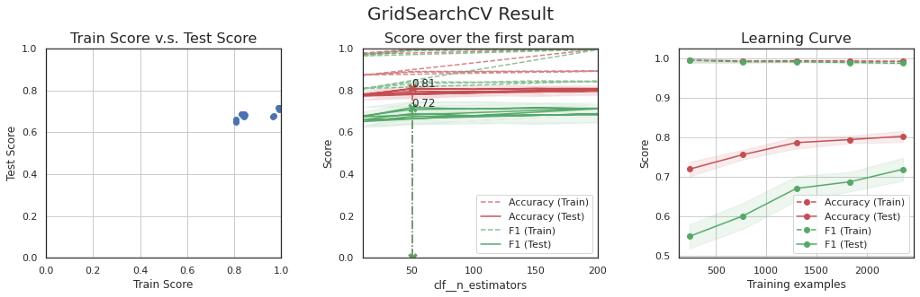
def metric(y_true, y_pred):acc = accuracy_score(y_true, y_pred)f1 = f1_score(y_true, y_pred, average='macro')return acc, f1scoring = {'Accuracy': 'accuracy', 'F1': 'f1_macro'}refit = 'F1'kfold = StratifiedKFold(n_splits=5)жЁЎеһӢAе’ҢBдҪҝз”ЁзҪ‘ж јжҗңзҙўдәӨеҸүйӘҢиҜҒ пјҢ иҖҢCе’ҢDзҡ„ж·ұеұӮзҘһз»ҸзҪ‘з»ңжЁЎеһӢдҪҝз”ЁиҮӘе®ҡд№үдәӨеҸүйӘҢиҜҒ гҖӮ
# еҲҶеұӮKFoldskf = StratifiedKFold(n_splits=5, shuffle=True, random_state=rand_seed)# еҫӘзҺҜfor n_fold, (train_indices, valid_indices) in enumerate(skf.split(y_train, y_train)):# жЁЎеһӢmodel = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3)# иҫ“е…Ҙж•°жҚ®x_train_fold = x_train[train_indices]y_train_fold = y_train[train_indices]x_valid_fold = x_train[valid_indices]y_valid_fold = y_train[valid_indices]# и®ӯз»ғtrain_bert(model, x_train_fold, y_train_fold, x_valid_fold, y_valid_fold)з»“жһңеҹәдәҺBERTзҡ„еҫ®и°ғжЁЎеһӢеңЁиҠұиҙ№дәҶжҲ–еӨҡжҲ–е°‘зӣёдјјзҡ„и¶…еҸӮж•°и°ғж•ҙж—¶й—ҙд№ӢеҗҺ пјҢ жҳҺжҳҫдјҳдәҺе…¶д»–жЁЎеһӢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
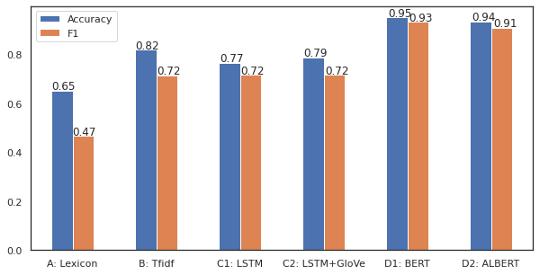
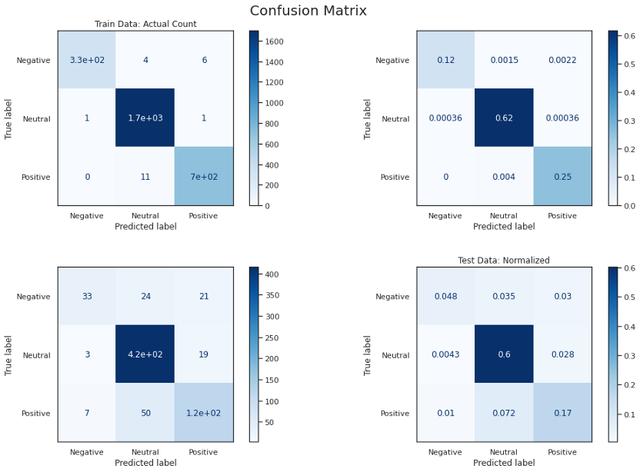
жЁЎеһӢAиЎЁзҺ°дёҚдҪі пјҢ еӣ дёәиҫ“е…ҘиҝҮдәҺз®ҖеҢ–дёәжғ…ж„ҹеҫ—еҲҶ пјҢ жғ…ж„ҹеҲҶж•°жҳҜеҲӨж–ӯжғ…з»Әзҡ„еҚ•дёҖеҖј пјҢ иҖҢйҡҸжңәжЈ®жһ—жЁЎеһӢжңҖз»Ҳе°ҶеӨ§еӨҡж•°ж•°жҚ®ж Үи®°дёәдёӯжҖ§ гҖӮ з®ҖеҚ•зҡ„зәҝжҖ§жЁЎеһӢеҸӘйңҖеҜ№жғ…ж„ҹиҜ„еҲҶеә”з”ЁйҳҲеҖје°ұеҸҜд»ҘиҺ·еҫ—жӣҙеҘҪзҡ„ж•Ҳжһң пјҢ дҪҶеңЁеҮҶзЎ®еәҰе’Ңf1иҜ„еҲҶж–№йқўд»Қ然еҫҲдҪҺ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҲ‘们没жңүдҪҝз”Ёж¬ йҮҮж ·/иҝҮйҮҮж ·жҲ–SMOTEзӯүж–№жі•жқҘе№іиЎЎиҫ“е…Ҙж•°жҚ® пјҢ еӣ дёәе®ғеҸҜд»Ҙзә жӯЈиҝҷдёӘй—®йўҳ пјҢ дҪҶдјҡеҒҸзҰ»еӯҳеңЁдёҚе№іиЎЎзҡ„е®һйҷ…жғ…еҶө гҖӮ еҰӮжһңеҸҜд»ҘиҜҒжҳҺдёәжҜҸдёӘиҰҒи§ЈеҶізҡ„й—®йўҳе»әз«ӢдёҖдёӘиҜҚе…ёзҡ„жҲҗжң¬жҳҜеҗҲзҗҶзҡ„ пјҢ иҝҷдёӘжЁЎеһӢзҡ„жҪңеңЁж”№иҝӣжҳҜе»әз«ӢдёҖдёӘиҮӘе®ҡд№үиҜҚе…ё пјҢ иҖҢдёҚжҳҜL-MиҜҚе…ё гҖӮ
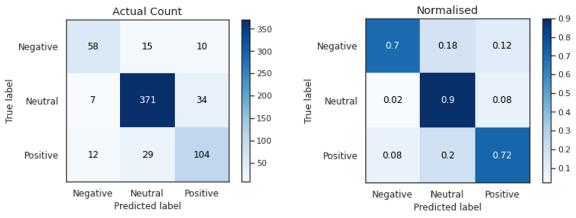
жЁЎеһӢBжҜ”еүҚдёҖдёӘжЁЎеһӢеҘҪеҫ—еӨҡ пјҢ дҪҶжҳҜе®ғд»ҘеҮ д№Һ100%зҡ„еҮҶзЎ®зҺҮе’Ңf1еҲҶж•°жӢҹеҗҲдәҶи®ӯз»ғйӣҶ пјҢ дҪҶжҳҜжІЎжңүиў«жіӣеҢ– гҖӮ жҲ‘иҜ•еӣҫйҷҚдҪҺжЁЎеһӢзҡ„еӨҚжқӮеәҰд»ҘйҒҝе…ҚиҝҮжӢҹеҗҲ пјҢ дҪҶжңҖз»ҲеңЁйӘҢиҜҒйӣҶдёӯзҡ„еҫ—еҲҶиҫғдҪҺ гҖӮ е№іиЎЎж•°жҚ®еҸҜд»Ҙеё®еҠ©и§ЈеҶіиҝҷдёӘй—®йўҳжҲ–收йӣҶжӣҙеӨҡзҡ„ж•°жҚ® гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жЁЎеһӢCдә§з”ҹдәҶдёҺеүҚдёҖдёӘжЁЎеһӢзӣёдјјзҡ„з»“жһң пјҢ дҪҶж”№иҝӣдёҚеӨ§ гҖӮ дәӢе®һдёҠ пјҢ и®ӯз»ғж•°жҚ®зҡ„ж•°йҮҸдёҚи¶ід»Ҙд»Һйӣ¶ејҖе§Ӣи®ӯз»ғзҘһз»ҸзҪ‘з»ң пјҢ йңҖиҰҒи®ӯз»ғеҲ°еӨҡдёӘepoch пјҢ иҝҷеҫҖеҫҖдјҡиҝҮжӢҹеҗҲ гҖӮ йў„и®ӯз»ғзҡ„GloVe并дёҚиғҪж”№е–„з»“жһң гҖӮ еҜ№еҗҺдёҖз§ҚжЁЎеһӢзҡ„дёҖдёӘеҸҜиғҪзҡ„ж”№иҝӣжҳҜдҪҝз”Ёзұ»дјјйўҶеҹҹзҡ„еӨ§йҮҸж–Үжң¬пјҲеҰӮ10KгҖҒ10QиҙўеҠЎжҠҘиЎЁпјүжқҘи®ӯз»ғGloVe пјҢ иҖҢдёҚжҳҜдҪҝз”Ёз»ҙеҹәзҷҫ科дёӯйў„и®ӯз»ғиҝҮзҡ„жЁЎеһӢ гҖӮ
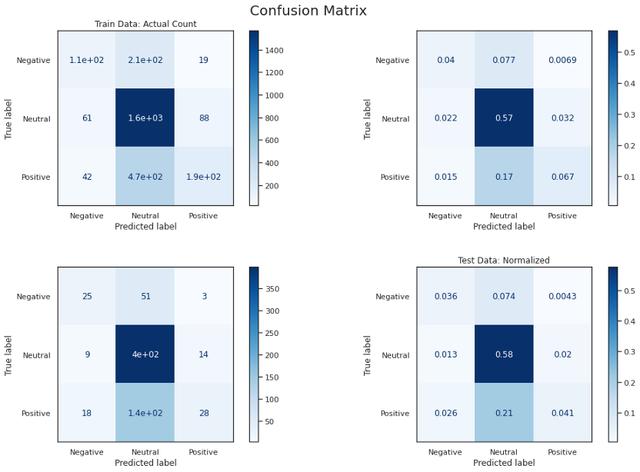
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
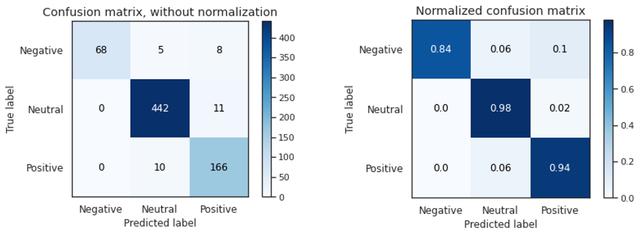
жЁЎеһӢDеңЁдәӨеҸүйӘҢиҜҒе’ҢжңҖз»ҲжөӢиҜ•дёӯзҡ„еҮҶзЎ®зҺҮе’Ңf1еҲҶж•°еқҮиҫҫеҲ°90%д»ҘдёҠ гҖӮ е®ғжӯЈзЎ®ең°е°Ҷиҙҹйқўж–Үжң¬еҲҶзұ»дёә84% пјҢ иҖҢжӯЈйқўж–Үжң¬жӯЈзЎ®еҲҶзұ»дёә94% пјҢ иҝҷеҸҜиғҪжҳҜз”ұдәҺиҫ“е…Ҙзҡ„ж•°йҮҸ пјҢ дҪҶжңҖеҘҪд»”з»Ҷи§ӮеҜҹд»ҘиҝӣдёҖжӯҘжҸҗй«ҳжҖ§иғҪ гҖӮ иҝҷиЎЁжҳҺ пјҢ з”ұдәҺиҝҒ移еӯҰд№ е’ҢиҜӯиЁҖжЁЎеһӢ пјҢ йў„и®ӯз»ғжЁЎеһӢзҡ„еҫ®и°ғеңЁиҝҷдёӘе°Ҹж•°жҚ®йӣҶдёҠиЎЁзҺ°иүҜеҘҪ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»

















- жҹ”жҖ§з”өеӯҗеёӮеңәе№ҝйҳ”пјҢйўҶеӨҙзҫҠжҹ”е®Ү科жҠҖиҺ·жӣҙеӨҡе…іжіЁ
- Eyeware BeamдҪҝз”ЁiPhoneиҝҪиёӘзҺ©е®¶еңЁжёёжҲҸдёӯзҡ„зңјзқӣиҝҗеҠЁ
- еҸҲзҲҶзӮёпјҒиҒ”з”ө科жҠҖдј жқҘдёҖеЈ°е·Ёе“ҚпјҢжҲ–жҠҠ8 иӢұеҜёжҷ¶еңҶеёӮеңә"зӮё"дәҶ
- зәҝдёӢеёӮеңәеҪ»еә•вҖңд№ұдәҶвҖқпјҒе°Ҹзұіе®Јеёғ新规пјҒеҚҺдёәжҚҶз»‘еҠ д»·иЎҢдёәиҝҺдәүи®®
- и…ҫи®ҜжёёжҲҸеҸ‘иө·еҜ№еҚҺдёәзҡ„жҢ‘жҲҳпјҢжҲ–еӣ еҗҺиҖ…еҜ№еӣҪеҶ…жүӢжңәеёӮеңәзҡ„еҪұе“ҚеҠӣеӨ§и·Ң
- еҚҺдёәP50 ProжёІжҹ“еӣҫжӣқе…үпјҡжӣІйқўзҖ‘еёғеұҸ
- иӢ№жһңдёӯеӣҪеҢәдёӢжһ¶иҝ‘5дёҮж¬ҫжёёжҲҸеә”з”ЁпјҢжүӢжёёеёӮеңәйқўдёҙеӨ§жҙ—зүҢ
- иҪ¬иҪ¬пјҡiPhone 12зғӯй”Җ дәҢжүӢеёӮеңә5GжүӢжңәдәӨжҳ“зңӢж¶Ё
- еёӮеңә|iPhoneXз”ЁжҲ·йӣҶдёӯеҚ–жүӢжңәпјҹиҪ¬иҪ¬Q4жүӢжңәиЎҢжғ…пјҡiPhone12еј•йўҶ5GжҚўжңәжҪ®
- OPPOиҘҝ欧еҮәиҙ§йҮҸеҺ»е№ҙеўһй•ҝдёүеҖҚ й«ҳз«ҜеёӮеңәжҲҗеӨҙйғЁеҺӮе•Ҷеҝ…дәүд№Ӣең°