Pythonж•°жҚ®еҲҶжһҗпјҡJupyter Notebook и®Іи§Ј( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
зҺ°еңЁйңҖиҰҒйҖҡиҝҮPythonе°Ҷе…¶иҜ»еҸ–еҮәжқҘ пјҢ 并е°ҶжҢҮе®ҡзҡ„еӯ—ж®өдҝқеӯҳеҲ°MongoDBдёӯ пјҢ йңҖиҰҒеңЁAnacondaдёӯжү§иЎҢе‘Ҫд»Өconda install pymongoе®үиЈ…pymongo гҖӮ
Pythonд»Јз ҒеҰӮдёӢпјҡ
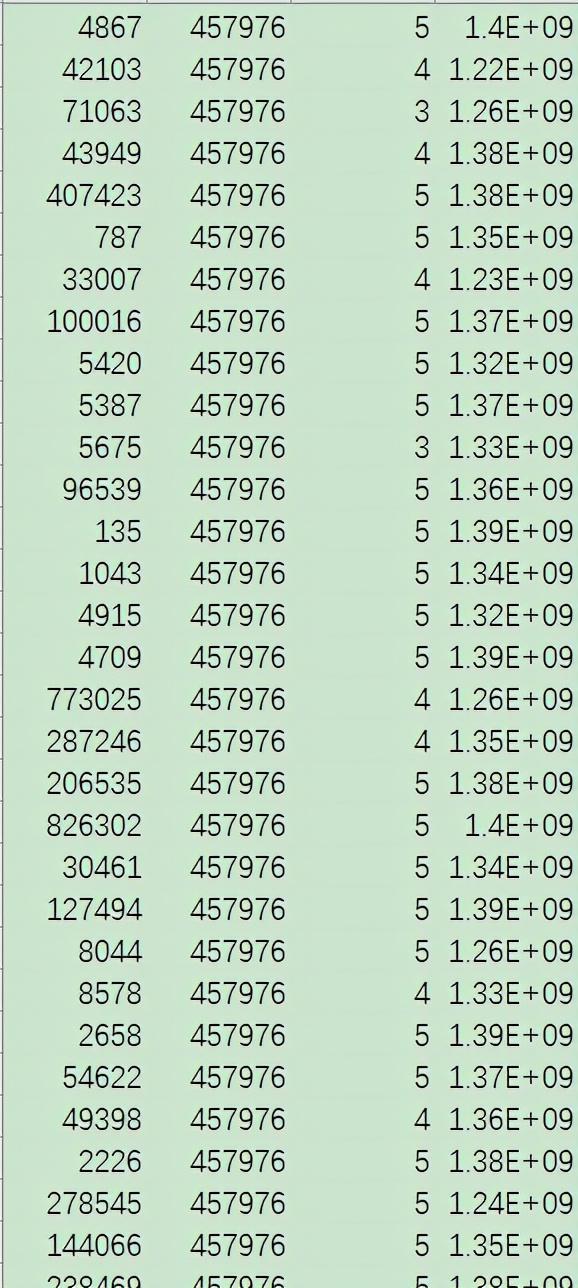
import pymongoclass Product:def __init__(self,productId:int ,name, imageUrl, categories, tags):self.productId = productIdself.name = nameself.imageUrl = imageUrlself.categories = categoriesself.tags = tagsdef __str__(self) -> str:return self.productId +'^' + self.name +'^' + self.imageUrl +'^' + self.categories +'^' + self.tagsclass Rating:def __init__(self, userId:int, productId:int, score:float, timestamp:int):self.userId = userIdself.productId = productIdself.score = scoreself.timestamp = timestampdef __str__(self) -> str:return self.userId +'^' + self.productId +'^' + self.score +'^' + self.timestampif __name__ == '__main__':myclient = pymongo.MongoClient("mongodb://127.0.0.1:27017/")mydb = myclient["goods-users"]## val attr = item.split("\\^")## // иҪ¬жҚўжҲҗProduct## Product(attr(0).toInt, attr(1).trim, attr(4).trim, attr(5).trim, attr(6).trim)shopproducts = mydb['shopproducts']with open('shopproducts.csv', 'r',encoding='UTF-8') as f:item = f.readline()while item:attr = item.split('^')product = Product(int(attr[0]), attr[1].strip(), attr[4].strip(), attr[5].strip(), attr[6].strip())shopproducts.insert_one(product.__dict__)## print(product)## print(json.dumps(obj=product.__dict__,ensure_ascii=False))item = f.readline()## val attr = item.split(",")## Rating(attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt)userratings = mydb['userratings']with open('userratings.csv', 'r',encoding='UTF-8') as f:item = f.readline()while item:attr = item.split(',')rating = Rating(int(attr[0]), int(attr[1].strip()), float(attr[2].strip()), int(attr[3].strip()))userratings.insert_one(rating.__dict__)## print(rating)item = f.readline()еңЁеҗҜеҠЁMongoDBжңҚеҠЎеҗҺ пјҢ иҝҗиЎҢPythonд»Јз Ғ пјҢ иҝҗиЎҢе®ҢжҲҗеҗҺ пјҢ еҶҚйҖҡиҝҮRobo 3TжҹҘзңӢж•°жҚ®еә“еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҳҫ然 пјҢ дҝқеӯҳж•°жҚ®жҲҗеҠҹ гҖӮ
дҪҝз”ЁJupyterеӨ„зҗҶе•Ҷй“әж•°жҚ®
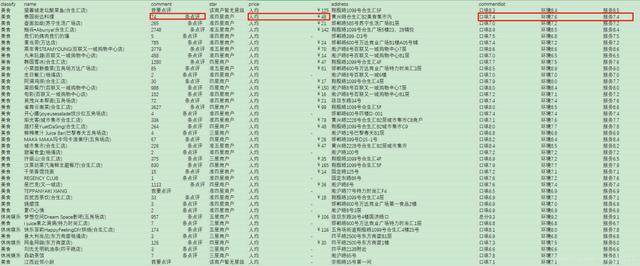
еҫ…еӨ„зҗҶзҡ„ж•°жҚ®жҳҜе•Ҷй“әж•°жҚ® пјҢ еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҢ…жӢ¬еҗҚз§°гҖҒиҜ„и®әж•°гҖҒд»·ж јгҖҒең°еқҖгҖҒиҜ„еҲҶеҲ—иЎЁзӯү пјҢ е…¶дёӯиҜ„и®әж•°гҖҒд»·ж је’ҢиҜ„еҲҶеқҮдёҚ规еҲҷгҖҒйңҖиҰҒиҝӣиЎҢж•°жҚ®жё…жҙ— гҖӮ
JupyterдёӯеӨ„зҗҶеҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҸҜд»ҘзңӢеҲ° пјҢ жңҖеҗҺеҫ—еҲ°дәҶз»ҸиҝҮжё…жҙ—еҗҺзҡ„规еҲҷж•°жҚ® гҖӮ
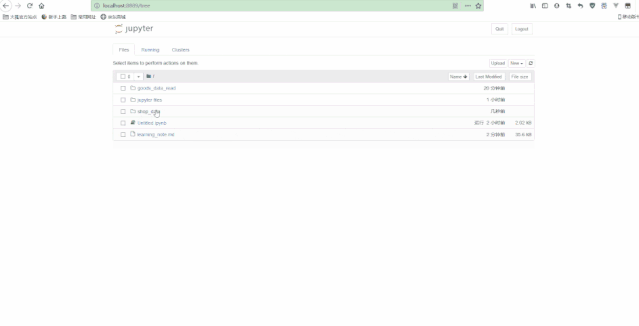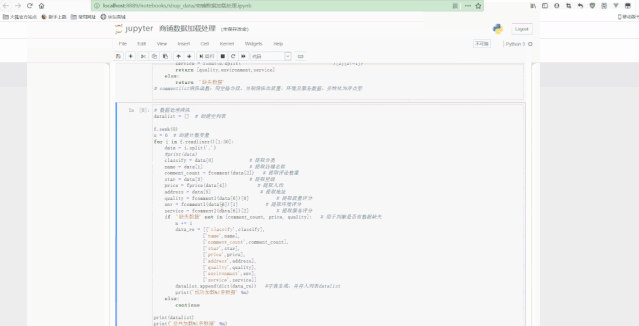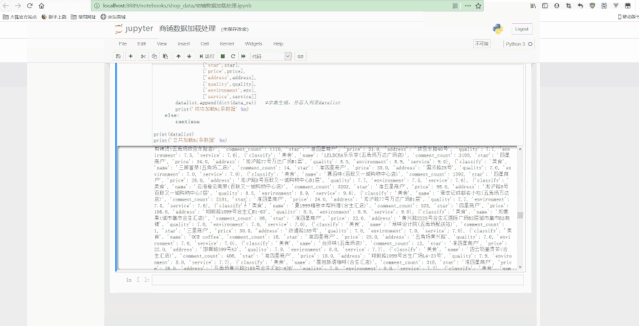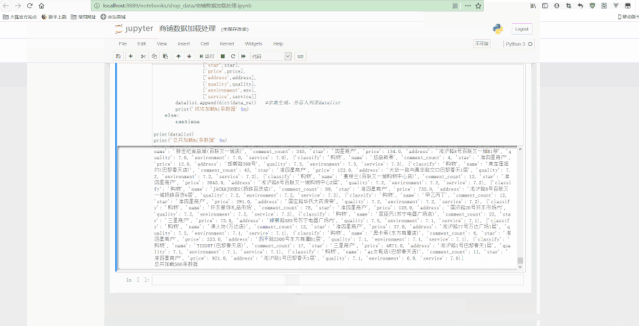
е®Ңж•ҙPythonд»Јз ҒеҰӮдёӢпјҡ
## ж•°жҚ®иҜ»еҸ–f = open('е•Ҷй“әж•°жҚ®.csv', 'r', encoding='utf8')for i in f.readlines()[1:15]:print(i.split(','))## еҲӣе»әcommentгҖҒpriceгҖҒcommentlistжё…жҙ—еҮҪж•°def fcomment(s):'''commentжё…жҙ—еҮҪж•°пјҡз”Ёз©әж јеҲҶж®ө пјҢ йҖүеҸ–з»“жһңlistзҡ„第дёҖдёӘдёәзӮ№иҜ„ж•° пјҢ 并且иҪ¬еҢ–дёәж•ҙеһӢ'''if 'жқЎ' in s:return int(s.split(' ')[0])else:return 'зјәеӨұж•°жҚ®'def fprice(s):'''priceжё…жҙ—еҮҪж•°пјҡз”ЁпҝҘеҲҶж®ө пјҢ йҖүеҸ–з»“жһңlistзҡ„жңҖеҗҺдёҖдёӘдёәдәәеқҮд»·ж ј пјҢ 并且иҪ¬еҢ–дёәжө®зӮ№еһӢ'''if 'пҝҘ' in s:return float(s.split('пҝҘ')[-1])else:return 'зјәеӨұж•°жҚ®'def fcommentl(s):'''commentlistжё…жҙ—еҮҪж•°пјҡз”Ёз©әж јеҲҶж®ө пјҢ еҲҶеҲ«жё…жҙ—еҮәиҙЁйҮҸгҖҒзҺҜеўғеҸҠжңҚеҠЎж•°жҚ® пјҢ 并иҪ¬еҢ–дёәжө®зӮ№еһӢ'''if ' ' in s:quality = float(s.split('')[0][2:])environment = float(s.split('')[1][2:])service = float(s.split('')[2][2:-1])return [quality, environment, service]else:return 'зјәеӨұж•°жҚ®'## ж•°жҚ®еӨ„зҗҶжё…жҙ—datalist = []## еҲӣе»әз©әеҲ—иЎЁf.seek(0)n = 0## еҲӣе»әи®Ўж•°еҸҳйҮҸfor i in f.readlines():data = http://kandian.youth.cn/index/i.split(',')## print(data)classify = data[0]## жҸҗеҸ–еҲҶзұ»name = data[1]## жҸҗеҸ–еә—й“әеҗҚз§°comment_count = fcomment(data[2])## жҸҗеҸ–иҜ„и®әж•°йҮҸstar = data[3]## жҸҗеҸ–жҳҹзә§price = fprice(data[4])## жҸҗеҸ–дәәеқҮaddress = data[5]## жҸҗеҸ–ең°еқҖquality = fcommentl(data[6])[0]## жҸҗеҸ–иҙЁйҮҸиҜ„еҲҶenv = fcommentl(data[6])[1]## жҸҗеҸ–зҺҜеўғиҜ„еҲҶservice = fcommentl(data[6])[2]## жҸҗеҸ–жңҚеҠЎиҜ„еҲҶif 'зјәеӨұж•°жҚ®' not in [comment_count, price, quality]:## з”ЁдәҺеҲӨж–ӯжҳҜеҗҰжңүж•°жҚ®зјәеӨұn += 1data_re = [['classify', classify],['name', name],['comment_count', comment_count],['star', star],['price', price],['address', address],['quality', quality],['environment', env],['service', service]]datalist.append(dict(data_re))## еӯ—е…ёз”ҹжҲҗ пјҢ 并еӯҳе…ҘеҲ—иЎЁdatalistprint('жҲҗеҠҹеҠ иҪҪ%iжқЎж•°жҚ®' % n)else:continueprint(datalist)print('жҖ»е…ұеҠ иҪҪ%iжқЎж•°жҚ®' % n)f.close()
жҺЁиҚҗйҳ…иҜ»
















- и®Ўз®—жңәдё“дёҡеӨ§дёҖдёӢеӯҰжңҹпјҢиҜҘйҖүжӢ©еӯҰд№ JavaиҝҳжҳҜPython
- жғіиҮӘеӯҰPythonжқҘејҖеҸ‘зҲ¬иҷ«пјҢйңҖиҰҒжҢүз…§е“ӘеҮ дёӘйҳ¶ж®өеҲ¶е®ҡеӯҰд№ и®ЎеҲ’
- жңӘжқҘжғіиҝӣе…ҘAIйўҶеҹҹпјҢиҜҘеӯҰд№ PythonиҝҳжҳҜJavaеӨ§ж•°жҚ®ејҖеҸ‘
- 2021е№ҙJavaе’ҢPythonзҡ„еә”з”Ёи¶ӢеҠҝдјҡжңүд»Җд№ҲеҸҳеҢ–пјҹ
- йқһи®Ўз®—жңәдё“дёҡзҡ„жң¬з§‘з”ҹпјҢжғіеҲ©з”ЁеҜ’еҒҮеӯҰд№ PythonпјҢиҜҘжҖҺд№Ҳе…ҘжүӢ
- з”ЁPythonеҲ¶дҪңеӣҫзүҮйӘҢиҜҒз ҒпјҢиҝҷдёүиЎҢд»Јз Ғе®ҢдәӢе„ҝ
- еҺҶж—¶ 1 дёӘжңҲпјҢеҒҡдәҶ 10 дёӘ Python еҸҜи§ҶеҢ–еҠЁеӣҫпјҢз”Ёеҝғдё”зІҫзҫҺ...
- ж•°жҚ®еҲҶжһҗдёҺжңәеҷЁеӯҰд№ пјҡдҫҰжөӢеә”з”ЁеҶ…жңәеҷЁдәәдҪңејҠе…ій”®
- дёәдҪ•еңЁдәәе·ҘжҷәиғҪз ”еҸ‘йўҶеҹҹPythonеә”з”ЁжҜ”иҫғеӨҡ
- еҜ№дәҺйқһи®Ўз®—жңәдё“дёҡзҡ„еҗҢеӯҰжқҘиҜҙпјҢиҜҘйҖүжӢ©еӯҰд№ PythonиҝҳжҳҜC