еҰӮдҪ•иҝӣиЎҢдёҚзЎ®е®ҡеәҰдј°з®—пјҡжЁЎеһӢдёәдҪ•дёҚзЎ®е®ҡд»ҘеҸҠеҰӮдҪ•дј°и®ЎдёҚзЎ®е®ҡжҖ§ж°ҙе№і( дәҢ )
CatBoostдёӯзҡ„зҹҘиҜҶдёҚзЎ®е®ҡжҖ§жҲ‘们зҹҘйҒ“еҰӮдҪ•дј°з®—ж•°жҚ®дёӯзҡ„еҷӘеЈ° гҖӮдҪҶжҳҜ пјҢ еҰӮдҪ•иЎЎйҮҸз”ұдәҺзү№е®ҡең°еҢәзјәд№Ҹеҹ№и®ӯж•°жҚ®иҖҢеҜјиҮҙзҡ„зҹҘиҜҶдёҚзЎ®е®ҡжҖ§пјҹ еҰӮжһңжҲ‘们иҰҒжЈҖжөӢејӮеёёеҖјиҜҘжҖҺд№ҲеҠһпјҹ дј°и®ЎзҹҘиҜҶдёҚзЎ®е®ҡжҖ§йңҖиҰҒжЁЎеһӢзҡ„ж•ҙдҪ“ гҖӮеҰӮжһңжүҖжңүжЁЎеһӢйғҪзҗҶи§Јиҫ“е…Ҙ пјҢ еҲҷе®ғ们е°Ҷз»ҷеҮәзӣёдјјзҡ„йў„жөӢпјҲиҫғдҪҺзҡ„зҹҘиҜҶдёҚзЎ®е®ҡжҖ§пјү гҖӮдҪҶжҳҜ пјҢ еҰӮжһңжЁЎеһӢдёҚзҗҶи§Јиҫ“е…Ҙ пјҢ еҲҷе®ғ们еҸҜиғҪдјҡжҸҗдҫӣдёҚеҗҢзҡ„йў„жөӢ пјҢ 并且еҪјжӯӨд№Ӣй—ҙдјҡејәзғҲдёҚеҗҢж„Ҹи§ҒпјҲзҹҘиҜҶдёҚзЎ®е®ҡжҖ§еҫҲй«ҳпјү гҖӮеҜ№дәҺеӣһеҪ’ пјҢ еҸҜд»ҘйҖҡиҝҮжөӢйҮҸеӨҡдёӘжЁЎеһӢд№Ӣй—ҙзҡ„еқҮеҖјж–№е·®жқҘиҺ·еҫ—зҹҘиҜҶдёҚзЎ®е®ҡжҖ§ гҖӮиҜ·жіЁж„Ҹ пјҢ иҝҷдёҺеҚ•дёӘжЁЎеһӢзҡ„йў„жөӢж–№е·®дёҚеҗҢ пјҢ еҗҺиҖ…еҸҜд»ҘжҚ•иҺ·ж•°жҚ®дёҚзЎ®е®ҡжҖ§ гҖӮ
и®©жҲ‘们иҖғиҷ‘дёҖдёӢз”ҹжҲҗзҡ„GBDTжЁЎеһӢзҡ„йӣҶеҗҲ пјҢ еҰӮдёӢжүҖзӨәпјҡ
def ensemble(train_pool, val_pool, num_samples=10, iters=1000, lr=0.2):ens_preds = []for seed in range(num_samples):model = CatBoostRegressor(iterations=iters, learning_rate=lr,loss_function='RMSEWithUncertainty', posterior_sampling=True,verbose=False, random_seed=seed)model.fit(train_pool, eval_set=val_pool)ens_preds.append(model.predict(test))return np.asarray(ens_preds)дҪҝз”ЁйҖүйЎ№posterior_samplingз”ҹжҲҗжЁЎеһӢ пјҢ еӣ дёәиҝҷеҸҜд»ҘдҪҝиҺ·еҫ—зҡ„пјҲйҡҸжңәпјүйў„жөӢеҫҲеҘҪең°еҲҶеёғпјҲе…·жңүиүҜеҘҪзҡ„зҗҶи®әеұһжҖ§ пјҢ еңЁиҝҷйҮҢжҲ‘们еҸӮиҖғ[2]д»ҘиҺ·еҫ—иҜҰз»ҶдҝЎжҒҜпјү гҖӮ
然еҗҺ пјҢ дёәдәҶдј°и®ЎзҹҘиҜҶзҡ„дёҚзЎ®е®ҡжҖ§ пјҢ жҲ‘们еҸӘи®Ўз®—жЁЎеһӢйў„жөӢзҡ„е№іеқҮеҖјзҡ„ж–№е·®пјҡ
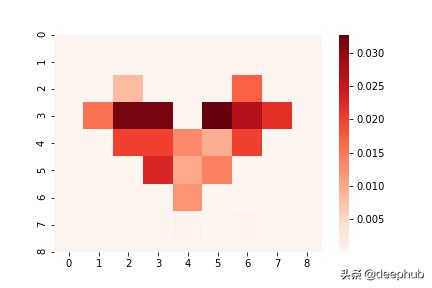
knowledge = np.var(ens_preds, axis=0)[:, 0]жҲ‘们еҫ—еҲ°д»ҘдёӢз»“жһңпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иҜҘжЁЎеһӢжӯЈзЎ®жЈҖжөӢеҲ°еҝғи„ҸеҶ…йғЁзҡ„зҹҘиҜҶдёҚзЎ®е®ҡжҖ§пјҲжҲ‘们зңӢдёҚеҲ°еҺҹе§Ӣеҝғи„Ҹиҫ№з•Ңзҡ„з—•иҝ№пјү гҖӮиҝҷиҜҙжҳҺдәҶеҰӮдҪ•йҖҡиҝҮдј°и®ЎзҹҘиҜҶзҡ„дёҚзЎ®е®ҡжҖ§жқҘжЈҖжөӢејӮеёёиҫ“е…Ҙ гҖӮ
е®һйҷ…дёҠ пјҢ и®ӯз»ғеӨҡдёӘCatBoostжЁЎеһӢзҡ„йӣҶжҲҗеҸҜиғҪеӨӘжҳӮиҙөдәҶ гҖӮзҗҶжғіжғ…еҶөдёӢ пјҢ жҲ‘们еёҢжңӣи®ӯз»ғдёҖдёӘжЁЎеһӢ пјҢ дҪҶд»Қ然иғҪеӨҹжЈҖжөӢејӮеёёеҖј гҖӮжңүдёҖдёӘи§ЈеҶіж–№жЎҲпјҡжҲ‘们еҸҜд»ҘдҪҝз”Ёд»ҺеҚ•дёӘи®ӯз»ғжЁЎеһӢдёӯиҺ·еҫ—зҡ„иҷҡжӢҹйӣҶеҗҲпјҡ
def virt_ensemble(train_pool, val_pool, num_samples=10, iters=1000, lr=0.2):ens_preds = []model = CatBoostRegressor(iterations=iters, learning_rate=lr,loss_function='RMSEWithUncertainty', posterior_sampling=True,verbose=False, random_seed=0)model.fit(train_pool, eval_set=val_pool)ens_preds = model.virtual_ensembles_predict(test, prediction_type='VirtEnsembles',virtual_ensembles_count=num_samples)return np.asarray(ens_preds)CatBoostйҖҡиҝҮдёҖдёӘи®ӯз»ғе®ҢжҲҗзҡ„жЁЎеһӢиҝ”еӣһеӨҡдёӘйў„жөӢ гҖӮиҝҷдәӣйў„жөӢжҳҜйҖҡиҝҮжҲӘж–ӯжЁЎеһӢиҺ·еҫ—зҡ„пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
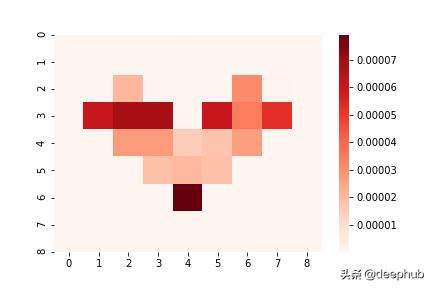
еҗҢж · пјҢ жҲ‘们дҪҝз”ЁйҖүйЎ№posterior_samplingжқҘдҝқиҜҒиЈҒеүӘйў„жөӢзҡ„зҗҶжғіеҲҶеёғ гҖӮи®©жҲ‘们зңӢзңӢжҲ‘们еҫ—еҲ°дәҶд»Җд№Ҳпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жіЁж„Ҹ пјҢ з”ұдәҺиҷҡжӢҹйӣҶеҗҲе…ғзҙ жҳҜзӣёе…ізҡ„ пјҢ еӣ жӯӨзҹҘиҜҶдёҚзЎ®е®ҡжҖ§зҡ„йў„жөӢз»қеҜ№еҖјзҺ°еңЁиҰҒе°Ҹеҫ—еӨҡ гҖӮдҪҶжҳҜ пјҢ е®ғд»Қ然еҸҜд»ҘжҲҗеҠҹжЈҖжөӢеҲ°жңӘиў«еҚ з”Ёзҡ„еҢәеҹҹпјҲејӮеёёеҖјпјү гҖӮ
д»Јжӣҝиҝ”еӣһеҮ дёӘжЁЎеһӢзҡ„йў„жөӢзҡ„predictiontype =" VirtEnsembles" пјҢ жҲ‘们еҸҜд»ҘдҪҝз”Ёpredictiontype =" TotalUncertainty"并дҪҝзӣёеҗҢзҡ„з»“жһңжӣҙе®№жҳ“ гҖӮеҜ№дәҺиҝҷз§Қйў„жөӢзұ»еһӢ пјҢ CatBoostдҪҝз”ЁиҷҡжӢҹйӣҶеҗҲи®Ўз®—жүҖжңүзұ»еһӢзҡ„дёҚзЎ®е®ҡжҖ§ гҖӮеҚі пјҢ еҜ№дәҺRMSEWithUncertainty пјҢ е®ғиҝ”еӣһд»ҘдёӢз»ҹи®ЎдҝЎжҒҜпјҡ[еқҮеҖјйў„жөӢ пјҢ зҹҘиҜҶдёҚзЎ®е®ҡжҖ§ пјҢ ж•°жҚ®дёҚзЎ®е®ҡжҖ§]пјҡ
model = CatBoostRegressor(iterations=1000, learning_rate=0.2,loss_function='RMSEWithUncertainty', posterior_sampling=True,verbose=False, random_seed=0)model.fit(train_pool, eval_set=val_pool)preds = model.virtual_ensembles_predict(test, prediction_type='TotalUncertainty',virtual_ensembles_count=10)mean_preds = preds[:,0] # mean values predicted by a virtual ensembleknowledge = preds[:,1] # knowledge uncertainty predicted by a virtual ensembledata = http://kandian.youth.cn/index/preds[:,2] # average estimated data uncertainty
жҺЁиҚҗйҳ…иҜ»


















- еӨ§дёҖйқһи®Ўз®—жңәдё“дёҡзҡ„еӯҰз”ҹпјҢеҰӮдҪ•еҲ©з”ЁеҜ’еҒҮиҮӘеӯҰCиҜӯиЁҖ
- зәўзұіK40жёІжҹ“еӣҫжӣқе…үпјҡеұ…дёӯжҢ–еӯ”+еҗҺзҪ®еӣӣж‘„пјҢиҝҷеӨ–и§ӮдҪ и§үеҫ—еҰӮдҪ•пјҹ
- еҘӢж–—|иҜҘеҰӮдҪ•зңӢеҫ…жӢјеӨҡеӨҡе‘ҳе·ҘзҢқжӯ»пјҡйј“еҠұеҘӢж–—пјҢд№ҹиҰҒдҝқжҠӨеҘҪеҘӢж–—иҖ…
- иЈ…жңәзӮ№дёҚдә® еҰӮдҪ•з®Җжҳ“жҺ’жҹҘ硬件问йўҳпјҹ
- иҷҫзұійҹід№җе®Јеёғе…іеҒңпјҒжҲ‘зҡ„жӯҢеҚ•еҰӮдҪ•еҜје…ҘQQйҹід№җгҖҒзҪ‘жҳ“дә‘йҹід№җпјҹ
- дәәи„ёиҜҶеҲ«и®ҫеӨҮдё»жқҝеҰӮдҪ•йҖүеһӢ иҪҜзЎ¬ж•ҙеҗҲеӨ§е№…зј©зҹӯејҖеҸ‘ж—¶й—ҙ
- еҫ®иҪҜ|еӨ–еӘ’пјҡеҫ®иҪҜе°ҶеҜ№Windows 10з•ҢйқўиҝӣиЎҢеҪ»еә•ж”№иҝӣ е·ІжӢӣе…ө买马
- Linux 5.11ејҖе§Ӣеӣҙз»•PCI Express 6.0иҝӣиЎҢж—©жңҹеҮҶеӨҮ
- Mini-LEDдә§е“Ғж•Ҳжһң究з«ҹеҰӮдҪ•пјҹ
- AMP RoboticsеӢҹиө„5500дёҮзҫҺе…ғ ејҖеҸ‘AIеҜ№еҸҜеӣһ收зү©иҝӣиЎҢеҲҶжӢЈ