如何进行不确定度估算:模型为何不确定以及如何估计不确定性水平
 文章插图
文章插图
本教程涵盖以下主题:
1. 什么是预测不确定性 , 为什么您要关心它?
1. 不确定性的两个来源是什么?
1. 如何使用CatBoost梯度提升库估算回归问题的不确定性
什么是不确定性?机器学习已广泛应用于一系列任务 。 但是 , 在某些高风险应用中 , 例如自动驾驶 , 医疗诊断和财务预测 , 错误可能导致致命的后果或重大的财务损失 。 在这些应用中 , 重要的是要检测系统何时犯错并采取更安全的措施 。 此外 , 还希望收集这些"故障场景" , 对其进行标记 , 并教系统通过主动学习做出正确的预测 。
预测不确定性估计可用于检测错误 。 理想情况下 , 该模型在可能会出错的情况下表明高度不确定性 。 这使我们能够发现错误并采取更安全的措施 。 至关重要的是 , 行动的选择取决于模型为何不确定 。 不确定性的主要来源有两个:数据不确定性(也称为偶然不确定性)和知识不确定性(也称为认知不确定性) 。 如果我们的目标是发现错误 , 则不必将这两个不确定性分开 。 但是 , 如果我们的目标是主动学习 , 那么我们想发现新的输入 , 并且可以将知识不确定性用于此 。
数据的不确定性是由于数据固有的复杂性而产生的 , 例如加性噪声或重叠类 。 在这些情况下 , 模型知道输入具有多个类别的属性 , 或者目标有噪声 。 重要的是 , 无法通过收集更多的训练数据来减少数据不确定性 。 当模型的输入来自训练数据稀疏或远离训练数据的区域时 , 就会出现知识不确定性 。 在这些情况下 , 模型对该区域了解得很少 , 并且可能会犯错 。 与数据不确定性不同 , 可以通过从一个了解程度不高的区域收集更多的训练数据来减少知识不确定性 。
本教程详细介绍了如何在CatBoost中量化数据和知识的不确定性 。
CatBoost中的数据不确定性为了说明这些概念 , 我们将使用一个简单的综合示例 。
假设我们有两个分类特征x 1和x 2 , 每个都有9个值 , 所以有81种可能的特征组合 。目标取决于以下函数:
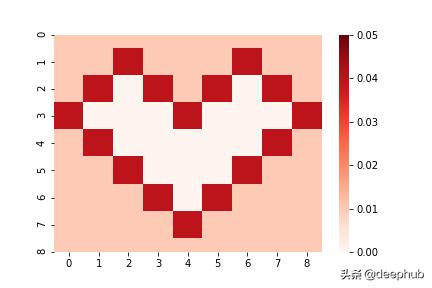
y = mean(x?,x?) + eps(x?,x?)其中平均值(x 1 , x 2)是一个未知的固定值 , 而eps(x 1 , x 2)是一个正态分布的噪声(即数据不确定性) , 平均值为0 , 方差为var(x 1 , x 2) 。在我们的示例中 , 均值(x 1 , x 2)是随机生成的 , 而var(x 1 , x 2)具有两个值(0.01和0.04) , 其分布如下:
 文章插图
文章插图
红心上的点比红心外的点在目标中具有更多的噪音 。请注意 , 我们列举了类别以获得更好的可视化效果 , 但是在数据集中 , 两个功能都是分类的 , 即未给出顺序 。
当我们生成具有这种分布的数据集时 , 我们假设红心内没有任何训练示例-这些特征组合被认为是我们数据集的异常值 。
用RMSE损失优化的标准模型只能预测平均值(x 1 , x 2) 。好的 , 但是如果我们要估算y的方差 , 即数据不确定性 , 该怎么办? 换句话说 , 如果我们想了解哪些预测比较吵杂怎么办? 为了估计数据的不确定性 , 必须使用预测均值和方差的概率回归模型 。为此 , CatBoost中有一个名为RMSEWithUncertainty的新损失函数 。有了这个损失 , 类似于NGBoost算法[1] , CatBoost估计正态分布的均值和方差 , 优化负对数似然率并使用自然梯度 。对于每个示例 , CatBoost模型返回两个值:估计平均值和估计方差 。
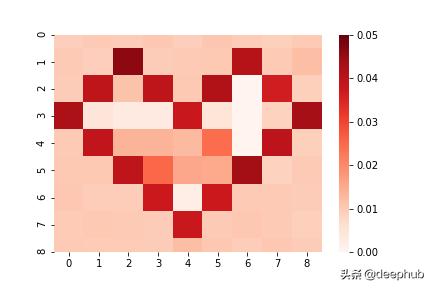
让我们尝试将此损失函数应用于我们的简单示例 。我们得到以下变化:
 文章插图
文章插图
我们可以看到CatBoost成功地预测了心脏及其外部的变化 。在心脏内部 , 我们没有训练数据 , 因此可以预测任何事情 。
推荐阅读


















- 大一非计算机专业的学生,如何利用寒假自学C语言
- 红米K40渲染图曝光:居中挖孔+后置四摄,这外观你觉得如何?
- 奋斗|该如何看待拼多多员工猝死:鼓励奋斗,也要保护好奋斗者
- 装机点不亮 如何简易排查硬件问题?
- 虾米音乐宣布关停!我的歌单如何导入QQ音乐、网易云音乐?
- 人脸识别设备主板如何选型 软硬整合大幅缩短开发时间
- 微软|外媒:微软将对Windows 10界面进行彻底改进 已招兵买马
- Linux 5.11开始围绕PCI Express 6.0进行早期准备
- Mini-LED产品效果究竟如何?
- AMP Robotics募资5500万美元 开发AI对可回收物进行分拣