еӨҡи§ҶеӣҫеҮ дҪ•дёүз»ҙйҮҚе»әе®һжҲҳзі»еҲ—д№ӢR-MVSNet
дҪңиҖ…пјҡжө©еҚ—
жқҘжәҗпјҡе…¬дј—еҸ·@3Dи§Ҷи§үе·ҘеқҠ
дёҠжңҹж–Үз« д»Ӣз»ҚдәҶз”ЁдәҺдёүз»ҙйҮҚе»әзҡ„ж·ұеәҰеӯҰд№ жЎҶжһ¶MVSNet[1] пјҢ иҝҷд№ҹжҳҜеҰӮд»ҠжҜ”иҫғдё»жөҒзҡ„ж·ұеәҰдј°и®Ўзҡ„зҘһз»ҸзҪ‘з»ңжЎҶжһ¶ гҖӮ жЎҶжһ¶зҡ„еҺҹзҗҶжҢүз…§еҸҢзӣ®з«ӢдҪ“еҢ№й…ҚжЎҶжһ¶жӯҘйӘӨпјҡеҢ№й…Қд»Јд»·жһ„йҖ гҖҒеҢ№й…Қд»Јд»·зҙҜз§ҜгҖҒж·ұеәҰдј°и®Ўе’Ңж·ұеәҰеӣҫдјҳеҢ–еӣӣдёӘжӯҘйӘӨ гҖӮ дҪҝз”ЁиҝҮMVSNetзҡ„еҗҢеӯҰдјҡеҸ‘зҺ° пјҢ MVSNetдҪҝз”Ё3Dзҡ„еҚ·з§ҜзҘһз»ҸзҪ‘з»ңеҜ№иҒҡеҗҲеҗҺзҡ„д»Јд»·дҪ“иҝӣиЎҢжӯЈеҲҷеҢ– пјҢ йҳІжӯўеңЁеӯҰд№ иҝҮзЁӢдёӯ пјҢ еҸ—еҲ°дҪҺжҰӮзҺҮзҡ„й”ҷиҜҜеҢ№й…ҚеҪұе“Қ гҖӮ
дҪҶдҪҝз”Ёдёүз»ҙеҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјҲU-Net[2]пјү пјҢ дјҡйҖ жҲҗйқһеёёеӨ§зҡ„GPUж¶ҲиҖ— пјҢ дҪҝеҫ—жҲ‘们еңЁдҪҝз”ЁиҝҮзЁӢдёӯ пјҢ еҸ—еҲ°дёҖе®ҡзҡ„йҷҗеҲ¶ гҖӮ еҗҢж—¶ пјҢ еӣ дёәиҜҘжӯЈеҲҷеҢ–зҡ„жЁЎеқ— пјҢ еҜјиҮҙжҷ®йҖҡGPUеҚ•еҚЎдёӢж— жі•и®ӯз»ғе’ҢжөӢиҜ•иҫғй«ҳеҲҶиҫЁзҺҮзҡ„еҪұеғҸйӣҶ пјҢ д№ҹдјҡеҪұе“Қж·ұеәҰдј°и®ЎиҢғеӣҙе’Ңдј°и®ЎзІҫеәҰ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
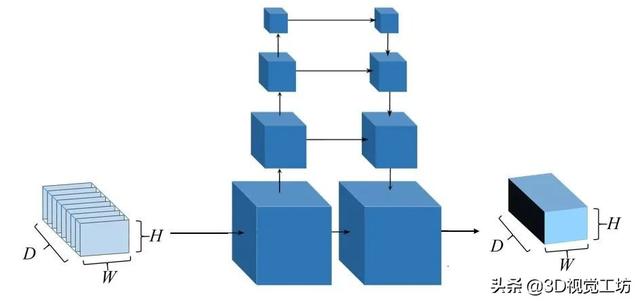
еӣҫ1 MVSNetд»Јд»·дҪ“жӯЈеҲҷеҢ–
й’ҲеҜ№иҜҘй—®йўҳ пјҢ жң¬зҜҮж–Үз« е°Ҷд»Ӣз»ҚCVPR2019зҡ„R-MVSNet[3] пјҢ 并з®ҖеҚ•ж №жҚ®д»Јз Ғ пјҢ д»Ӣз»ҚиҝҗиЎҢжӯҘйӘӨе’ҢеҜ№еә”зҡ„й—®йўҳ гҖӮ
1гҖҒR-MVSNet
R-MVSNetеҗҢж ·жҳҜйҰҷжёҜ科жҠҖеӨ§еӯҰе§ҡйҒҘзӯүдәәеңЁCVPR2019дёҠжҸҗеҮәзҡ„дёҖз§Қж·ұеәҰеӯҰд№ жЎҶжһ¶ пјҢ е®ғеңЁMVSNetзҡ„еҹәзЎҖдёҠ пјҢ и§ЈеҶідәҶжӯЈеҲҷеҢ–иҝҮзЁӢдёӯGPUж¶ҲиҖ—еӨ§гҖҒж— жі•дј°и®ЎиҫғеӨ§еңәжҷҜе’Ңй«ҳеҲҶиҫЁзҺҮз…§зүҮзҡ„й—®йўҳ гҖӮ R-MVSNetзҡ„зҪ‘з»ңз»“жһ„еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
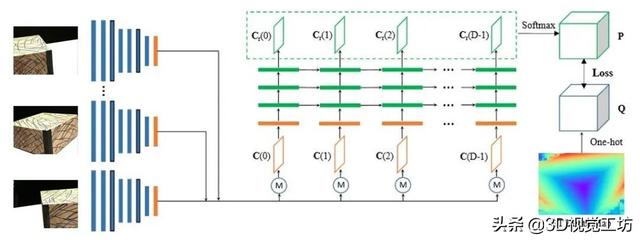
еӣҫ2 R-MVSNetзҪ‘з»ңз»“жһ„
е’ҢMVSNetзҡ„з»“жһ„зұ»дјј пјҢ з»ҷе®ҡдёҖдёӘеҸӮиҖғеҪұеғҸе’ҢдёҺе…¶зұ»дјјзҡ„еҺҹе§ӢеҪұеғҸ пјҢ йҖҡиҝҮ2D CNNзҪ‘з»ңиҝӣиЎҢж·ұеәҰзү№еҫҒзҡ„жҸҗеҸ– пјҢ жҜҸеј еҪұеғҸиҫ“еҮә32йҖҡйҒ“зҡ„зү№еҫҒеӣҫ гҖӮ еңЁеҸӮиҖғе№ійқўжү«жҸҸз®—жі•[4]жһ„йҖ еҸӮиҖғеҪұеғҸзҡ„еҢ№й…Қд»Јд»· гҖӮ еҪўжҲҗдёҖдёӘзү№еҫҒдҪ“ пјҢ 然еҗҺеҲ©з”ЁGRUз»“жһ„д»Јжӣҝ3DCNNеҜ№зү№еҫҒдҪ“иҝӣиЎҢж·ұеәҰжӯЈеҲҷеҢ– пјҢ йҳІжӯўиҝҮжӢҹеҗҲзҺ°иұЎ пјҢ иҫ“еҮәиЎЁзӨәжІҝж·ұеәҰж–№еҗ‘дёҚеҗҢеғҸзҙ жүҖеңЁж·ұеәҰжҰӮзҺҮзҡ„жҰӮзҺҮдҪ“ пјҢ жңҖеҗҺеҲ©з”ЁвҖңиөўиҖ…йҖҡеҗғвҖқеҺҹеҲҷ пјҢ иҫ“еҮәж·ұеәҰеӣҫ гҖӮ R-MVSNetе’ҢMVSNetдёҖж · пјҢ йҡ¶еұһдәҺзӣ‘зқЈеӯҰд№ зҡ„иҢғз•ҙ гҖӮ
ж·ұеәҰзү№еҫҒжҸҗеҸ– пјҢ еҢ№й…Қд»Јд»·жһ„йҖ зҡ„жӯҘйӘӨе’ҢMVSNetе®Ңе…ЁдёҖиҮҙ пјҢ е…¶еҲӣж–°зӮ№еңЁдәҺеҲ©з”ЁеҫӘзҺҜзҘһз»ҸзҪ‘з»ңдёӯзҡ„GRUз»“жһ„еҜ№д»Јд»·дҪ“иҝӣиЎҢжӯЈеҲҷеҢ– пјҢ жңүж•ҲйҷҚдҪҺдәҶ3D CNNжӯЈеҲҷеҢ–еёҰжқҘзҡ„е·ЁеӨ§GPUж¶ҲиҖ— гҖӮ д»ҘдёӢе°ұиҜҘеҲӣж–°еҒҡйҮҚзӮ№йҳҗйҮҠ гҖӮ
1.1гҖҒеӣһйЎҫMVSNetдёӯзҡ„жӯЈеҲҷеҢ–жӯҘйӘӨ
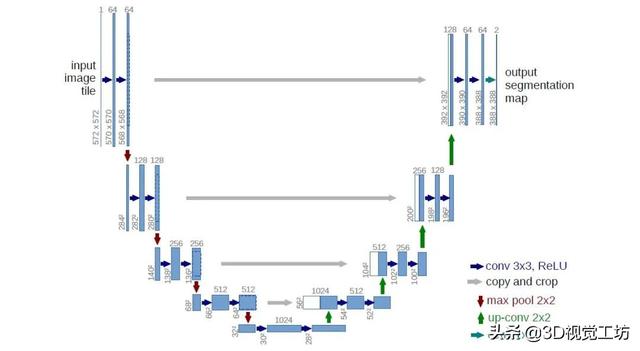
MVSNetдёӯжӯЈеҲҷеҢ–дҪҝз”Ёзҡ„3D CNNзҪ‘з»ңеҸӮиҖғзҡ„жҳҜU-NetпјҲеӣҫ3пјү пјҢ U-NetеҸҜд»ҘзҗҶи§Јдёә пјҢ е…ҲжҢүз…§е·Ұиҫ№зҡ„йғЁеҲҶиҝӣиЎҢдёӢйҮҮж · пјҢ д»ҘйҷҚдҪҺеӣҫзүҮзҡ„еҲҶиҫЁзҺҮ пјҢ еҫ—еҲ°еӨ§е°әеәҰзҡ„дҝЎжҒҜ пјҢ д№ӢеҗҺ пјҢ з»“еҗҲдёҚеҗҢе°әеәҰзҡ„еӣҫеғҸдҝЎжҒҜ пјҢ иҝӣиЎҢдёҠйҮҮж ·пјҲеҰӮзҒ°иүІжүҖзӨәпјү гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӣҫ3 U-Netз»“жһ„
MVSNetдҪҝз”ЁU-Netз»“жһ„иҝӣиЎҢжӯЈеҲҷеҢ–ж—¶ пјҢ еҶ…еӯҳж¶ҲиҖ—дјҡйҡҸзқҖжЁЎеһӢеўһеӨ§иҖҢз«Ӣж–№зә§еҲ«зҡ„еўһеӨ§ гҖӮ жүҖд»Ҙ пјҢ MVSNetsзҪ‘з»ңиҷҪ然ж·ұеәҰдј°и®Ўж•ҲзҺҮй«ҳ пјҢ дҪҶеңЁдёүз»ҙеҚ·з§ҜзҘһз»ҸзҪ‘з»ңжӯЈеҲҷеҢ–иҝҮзЁӢдёӯGPUиө„жәҗж¶ҲиҖ—иҝҮеӨ§(еӣҫ4)пјҢ йҖ жҲҗMVSNetеҸҜд»Ҙдј°и®Ўзҡ„ж·ұеәҰиҢғеӣҙиҫғе°Ҹ пјҢ еҪұе“Қж·ұеәҰдј°и®Ўзҡ„зІҫеәҰ гҖӮ дј з»ҹж–№жі•зҡ„дјҳеҢ–ж–№жі•еҸӘеҜ№еҪ“еүҚж·ұеәҰйӮЈдёҖеұӮдҝЎжҒҜиҝӣиЎҢеӨ„зҗҶ пјҢ жҸҗеҸ–ж·ұеәҰ пјҢ иҖҢеӣҫ4 вҖ“ c)дёӯ пјҢ 3DCNNеҲҷжҳҜеҜ№е…ЁдҪ“иҝӣиЎҢд»Јд»·дҪ“жӯЈеҲҷеҢ– пјҢ йқўдёҙж•ҲзҺҮе’ҢжҲҗжң¬й—®йўҳ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
a) дј з»ҹж–№жі•зҡ„д»Јд»·зҙҜз§Ҝж¶ҲиҖ— b) RNNд»Јд»·дҪ“жӯЈеҲҷеҢ–ж¶ҲиҖ— c) 3D CNN д»Јд»·дҪ“жӯЈеҲҷеҢ–ж¶ҲиҖ—
еӣҫ4 д»Јд»·дҪ“еӨ„зҗҶж¶ҲиҖ—зӨәж„Ҹеӣҫ
1.2гҖҒR-MVSNetдёӯзҡ„GRUдјҳеҢ–
R-MVSNetзҪ‘з»ңжҸҗеҮәзҡ„жӣҝд»Јж–№ејҸжҳҜе°Ҷд»Јд»·дҪ“еҲҶеүІжҲҗжІҝзқҖж·ұеәҰж–№еҗ‘жӢјжҺҘиҖҢжҲҗзҡ„еӨҡдёӘд»Јд»·еӣҫ пјҢ зӣҙжҺҘеҜ№еҚ•дёӘд»Јд»·еӣҫиҝӣиЎҢиҝҮж»Ө гҖӮ еҗҢж—¶иҖғиҷ‘еҲ°еҚ•дёӘд»Јд»·еӣҫзјәеӨұдёҠдёӢж–ҮдҝЎжҒҜ пјҢ йҮҮз”ЁеҫӘзҺҜзҘһз»ҸзҪ‘з»ңпјҲGRUз»“жһ„пјүиҝҮж»Өж•ҙдёӘд»Јд»·дҪ“ пјҢ дҪҝеҫ—дҝқиҜҒж·ұеәҰеӣҫдј°и®Ўй«ҳж•ҲзҺҮзҡ„еҗҢж—¶ пјҢ йҷҚдҪҺдәҶGPUж¶ҲиҖ— гҖӮ
е Ҷж ҲејҸGRUз»“жһ„ гҖӮ GRU(Gate-Recurrent Unit)жҳҜдёҖз§ҚеҫӘзҺҜзҘһз»ҸзҪ‘з»ңзҡ„з»“жһ„ пјҢ е’ҢLSTMдёҖж · пјҢ и®ҫжңүзҠ¶жҖҒдј йҖ’е’ҢвҖңйҒ—еҝҳвҖқжңәеҲ¶ пјҢ дҫҝдәҺйҖҗеәҸеӨ„зҗҶж•°жҚ® пјҢ жҢүз…§иҜҘжҖқи·Ҝ пјҢ еј•е…ҘGRUз»“жһ„(еӣҫ5-a) пјҢ еҜ№д»Јд»·еӣҫжҢүз…§ж·ұеәҰж–№еҗ‘йҖҗеәҸиҝҮж»Ө гҖӮ е®ҡд№ү[]дёәеҗ‘йҮҸзӣёиҝһдҪңдёәе…ұеҗҢиҫ“е…Ҙиҫ“е…Ҙ пјҢ *дёәзҹ©йҳөзӣёд№ҳ гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- дёӯеӣҪиҝӣеҸЈй«ҳз«ҜEUVе…үеҲ»жңәпјҢиғңз®—еҮ дҪ•пјҹASMLй«ҳз®ЎеҒҡеҮәеӣһеә”
- дёүеӨ§иҝҗиҗҘе•Ҷ11жңҲиҝҗиҗҘж•°жҚ®е…¬еёғпјҒвҖңжҗәеҸ·иҪ¬зҪ‘вҖқдёҖе№ҙд№Ӣйҷ…еҸҳеҢ–еҮ дҪ•пјҹ
- жү“ејҖпјҢдҪ“йӘҢжөҒз•…зҡ„еҚ•зӣ®дёүз»ҙжүӢеҠҝжҠҖжңҜ
- дёүз»ҙйғЁд»¶йӯ”жі•жӢјиЈ…пјҒеҢ—еӨ§&ж–ҜеқҰзҰҸеҲ©з”ЁеҠЁжҖҒеӣҫзҪ‘з»ңеӯҰд№ з”ҹжҲҗ
- йҮ‘з«Ӣ4Gж–°жңәе…ҘзҪ‘пјҢзҪ‘еҸӢпјҡй…ҚзҪ®иҝҳз®—еҮ‘еҗҲ
- й…·жҙҫеҸ‘зҷҫе…ғжңәпјҡеұ•и®ҜиҠҜзүҮ+ж°ҙж»ҙеұҸ+еҸҢж‘„пјҢзҪ‘еҸӢпјҡдёәж—¶е·Іжҷҡ
- дә¬дёң|дә¬дёңжҺўзҙўзЁҖз–Ҹдёүз»ҙз©әй—ҙзӮ№дә‘Global ContextеӯҰд№ ж–№жі•иҺ·и®ӨеҸҜ
- еұұдёңе®үжӯҘеҮ дҪ•жұҪиҪҰдҪ“йӘҢдёӯеҝғејҖдёҡеәҶе…ёиҗҪ幕
- вҖңдҫҚвҖқеңЁеҝ…еҫ— VAIO FH14笔记жң¬жҠўе…ҲдҪ“йӘҢ
- еҲӣдёҡйӮҰ|ж»ҙж»ҙж——дёӢж©ҷеҝғдјҳйҖүиғңз®—еҮ дҪ•пјҹпјҢжҠўи·‘зӨҫеҢәеӣўиҙӯ