机器学习实战:GNN(图神经网络)加速器的FPGA解决方案
应用Achronix Speedster7t FPGA设计高能效、可扩展的GNN加速器
1、概述得益于大数据的兴起以及算力的快速提升 , 机器学习技术在近年取得了革命性的发展 。 在图像分类、语音识别、自然语言处理等机器学习任务中 , 数据为大小维度确定且排列有序的欧氏(Euclidean)数据 。 然而 , 越来越多的现实场景中 , 数据是以图(Graph)这种复杂的非欧氏数据来表示的 。 Graph不但包含数据 , 也包含数据之间的依赖关系 , 比如社交网络、蛋白质分子结构、电商平台客户数据等等 。 数据复杂度的提升 , 对传统的机器学习算法设计以及其实现技术带来了严峻的挑战 。 在此背景之下 , 诸多基于Graph的新型机器学习算法—GNN(图神经网络) , 在学术界和产业界不断的涌现出来 。
 文章插图
文章插图
GNN对算力和存储器的要求非常高 , 其算法的软件实现方式非常低效 , 所以业界对GNN的硬件加速有着非常迫切的需求 。 我们知道传统的CNN(卷积神经网络网络)硬件加速方案已经有非常多的解决方案;但是 , GNN的硬件加速尚未得到充分的讨论和研究 , 在本文撰写之时 , Google和百度皆无法搜索到关于GNN硬件加速的中文研究 。 本文的撰写动机 , 旨在将国外最新的GNN算法、加速技术研究、以及笔者对GNN的FPGA加速技术的探讨相结合起来 , 以全景图的形式展现给读者 。
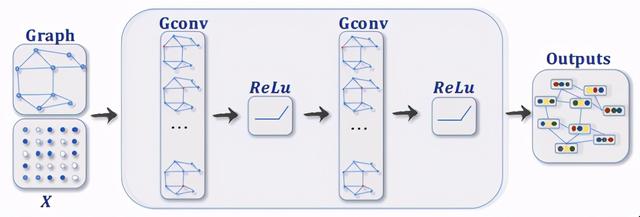
2、GNN简介GNN的架构在宏观层面有着很多与传统CNN类似的地方 , 比如卷积层、Polling、激活函数、机器学习处理器(MLP)和FC层等等模块 , 都会在GNN中得以应用 。 下图展示了一个比较简单的GNN架构 。
 文章插图
文章插图
图 1:典型的GNN架构(来源:)
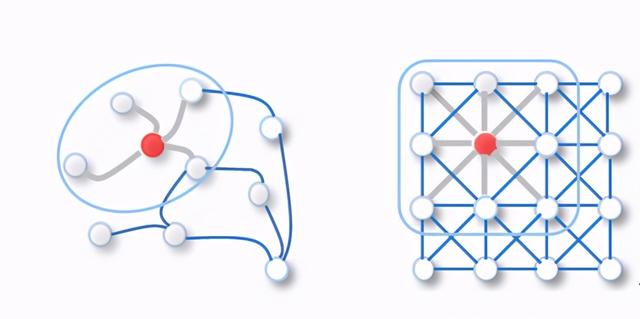
但是 ,GNN中的Graph数据卷积计算与传统CNN中的2D卷积计算是不同的 。 以图2为例 , 针对红色目标节点的卷积计算 , 其过程如下:
- Graph卷积:以邻居函数采样周边节点特征并计算均值 , 其邻居节点数量不确定且无序(非欧氏数据) 。
- 2D卷积:以卷积核采样周边节点特征并计算加权平均值 , 其邻居节点数量确定且有序(欧氏数据) 。
 文章插图
文章插图图 2: Graph卷积和2D卷积(来源:)
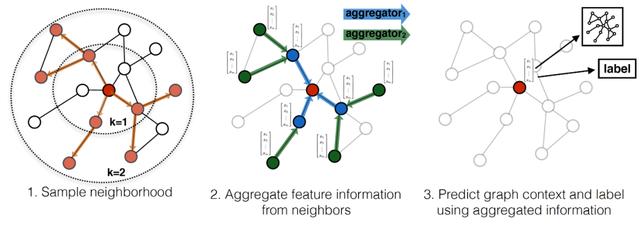
3、GraphSAGE算法简介学术界已对GNN算法进行了非常多的研究讨论 , 并提出了数目可观的创新实现方式 。 其中 , 斯坦福大学在2017年提出的GraphSAGE是一种用于预测大型图中动态新增未知节点类型的归纳式表征学习算法 , 特别针对节点数量巨大、且节点特征丰富的图做了优化 。 如下图所示 , GraphSAGE计算过程可分为三个主要步骤:
 文章插图
文章插图图 3:GraphSAGE算法的视觉表述(来源:)
- 邻节点采样:用于降低复杂度 , 一般采样2层 , 每一层采样若干节点
- 聚合:用于生成目标节点的embedding , 即graph的低维向量表征
- 预测:将embedding作为全连接层的输入 , 预测目标节点d的标签
 文章插图
文章插图图 4:GraphSAGE算法的数学模型(来源:)
对于每一个待处理的目标节点xv , GraphSAGE 执行下列操作:
1)通过邻居采样函数N(v) , 采样子图(subgraph)中的节点
推荐阅读

![[数码小王]Pro有点像,还是双打孔曲面屏!荣耀30 Pro真机曝光,跟华为P40](https://imgcdn.toutiaoyule.com/20200328/20200328061128829913a_t.jpeg)
















- 唐山四维智能科技有限公司:双臂机器人引领人机协作新纪元
- 计算机专业大一下学期,该选择学习Java还是Python
- 大众展示EV公共充电新解决方案:移动充电机器人
- 普渡机器人获最佳商用服务机器人奖
- 翻译|机器翻译能达60个语种3000个方向,近日又夺全球五冠,这家牛企是谁?
- 假期弯道超车 国美学习“神器”助孩子变身“学霸”
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 我国首次给四个新职业定标