机器学习实战:GNN(图神经网络)加速器的FPGA解决方案( 三 )
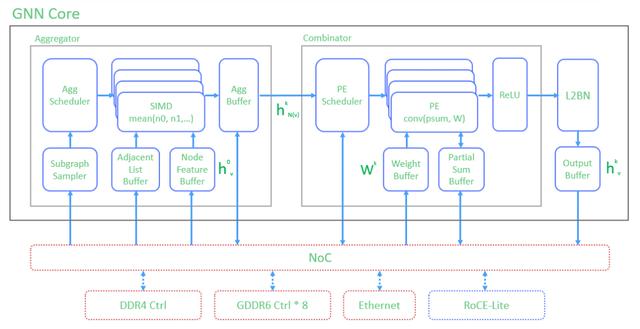
基于以上分析 , 我们决定在GNN Core加速器设计中用两种不同的硬件结构来处理聚合操作与合并操作 , 功能框图如下图所示:
 文章插图
文章插图
图7: GNN Core功能框图(来源:Achronix原创)
聚合器(Aggregator):通过SIMD(单指令多数据处理器)阵列来对Graph进行邻居节点采样并进行聚合操作 。 其中的“单指令”可以预定义为mean()均值计算 , 或者其他适用的聚合函数;“多数据”则表示单次mean()均值计算中需要多个邻居节点的特征数据作为输入 , 而这些数据来自于子图采样器(Subgraph Sampler);SIMD阵列通过调度器Agg Scheduler做负载均衡;子图采样器通过NoC从GDDR6或DDR4读回的邻接矩阵和节点特征数据h0v , 分别缓存在Adjacent List Buffer和Node Feature Buffer之中;聚合的结果hkN(v)存储在Agg Buffer之中 。
合并器(Combinator):通过脉动矩阵PE来执行聚合结果的卷积操作;卷积核为Wk权重矩阵;卷积结果通过ReLU激活函数做非线性处理 , 同时也存储在Partial Sum Buffer中以方便下一轮迭代 。
合并的结果通过L2BN归一化处理之后 , 即为最终的节点表征hkv 。
在比较典型的节点分类预测应用中 , 该节点表征hkv可以通过一个全连接层(FC) , 以得到该节点的分类标签 。 此过程属于传统的机器学习处理方法之一 , 没有在GraphSAGE论文中体现 , 此设计中也没有包含这个功能 。
6、结论本文深入讨论了GraphSAGE GNN 算法的数学原理 , 并从多个维度分析了GNN加速器设计中的技术挑战 。 作者通过分解问题并在架构层面逐一解决的方法 , 综合运用Achronix Speedster7t1500FPGA所提供的竞争优势 , 创造了一个性能极佳且高度可扩展的GNN加速解决方案 。
如需了解关于Achronix Speedster7t1500FPGA 产品以及该GNN加速器方案的更多信息 , 请访问Achronix 官方网站: 。
作者:袁光(Kevin Yuan) , Achronix资深现场应用工程师
欢迎您扫码关注Achronix头条号 , 了解更多FPGA、eFPGA、加速卡产品及应用信息:
 文章插图
文章插图
【机器学习实战:GNN(图神经网络)加速器的FPGA解决方案】如希望进一步了解Achronix及其系列FPGA产品 , 请发邮件到Dawson.Guo@achronix.com
推荐阅读
















- 唐山四维智能科技有限公司:双臂机器人引领人机协作新纪元
- 计算机专业大一下学期,该选择学习Java还是Python
- 大众展示EV公共充电新解决方案:移动充电机器人
- 普渡机器人获最佳商用服务机器人奖
- 翻译|机器翻译能达60个语种3000个方向,近日又夺全球五冠,这家牛企是谁?
- 假期弯道超车 国美学习“神器”助孩子变身“学霸”
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 我国首次给四个新职业定标