4个计算机视觉领域用作迁移学习的模型( 二 )
对问题进行微调现在的模型也许能解决我们的问题 。 对预先训练好的模型进行微调通常更好 , 原因有两个:
- 这样我们可以达到更高的精度 。
- 我们的微调模型可以产生正确的格式的输出 。
在删除顶层之后 , 我们需要放置自己的层 , 这样我们就可以得到我们想要的输出 。 例如 , 使用ImageNet训练的模型可以分类多达1000个对象 。 如果我们试图对手写数字进行分类(例如 , MNIST classification) , 那么最后得到一个只有10个神经元的层可能会更好 。
在我们将自定义层添加到预先训练好的模型之后 , 我们可以用特殊的损失函数和优化器来配置它 , 并通过额外的训练进行微调 。
计算机视觉中的4个预训练模型这里有四个预先训练好的网络 , 可以用于计算机视觉任务 , 如图像生成、神经风格转换、图像分类、图像描述、异常检测等:
- VGG19
- Inceptionv3 (GoogLeNet)
- ResNet50
- EfficientNet
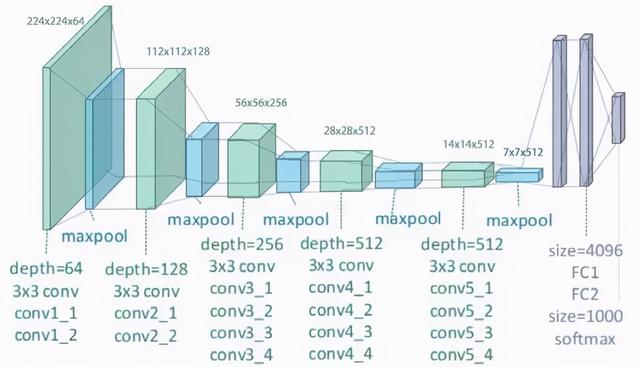
VGG-19VGG是一种卷积神经网络 , 深度为19层 。 它是由牛津大学的Karen Simonyan和Andrew Zisserman在2014年构建和训练的 , 论文为:Very Deep Convolutional Networks for large Image Recognition 。 VGG-19网络还使用ImageNet数据库中的100多万张图像进行训练 。 当然 , 你可以使用ImageNet训练过的权重导入模型 。 这个预先训练过的网络可以分类多达1000个物体 。 对224x224像素的彩色图像进行网络训练 。 以下是关于其大小和性能的简要信息:
- 大小:549 MB
- Top-1 准确率:71.3%
- Top-5 准确率:90.0%
- 参数个数:143,667,240
- 深度:26
 文章插图
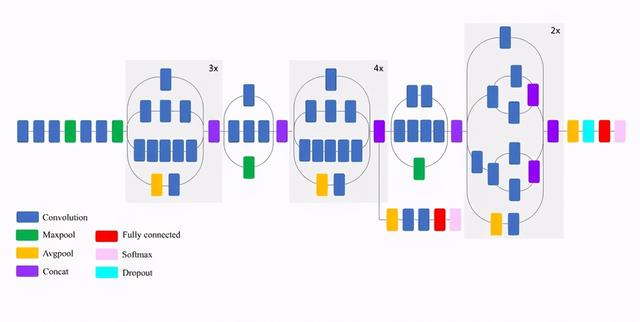
文章插图Inceptionv3 (GoogLeNet)Inceptionv3是一个深度为50层的卷积神经网络 。 它是由谷歌构建和训练的 , 你可以查看这篇论文:“Going deep with convolutions” 。 预训练好的带有ImageNet权重的Inceptionv3可以分类多达1000个对象 。 该网络的图像输入大小为299x299像素 , 大于VGG19网络 。 VGG19是2014年ImageNet竞赛的亚军 , 而Inception是冠军 。 以下是对Inceptionv3特性的简要总结:
- 尺寸:92 MB
- Top-1 准确率:77.9%
- Top-5 准确率:93.7%
- 参数数量:23,851,784
- 深度:159
 文章插图
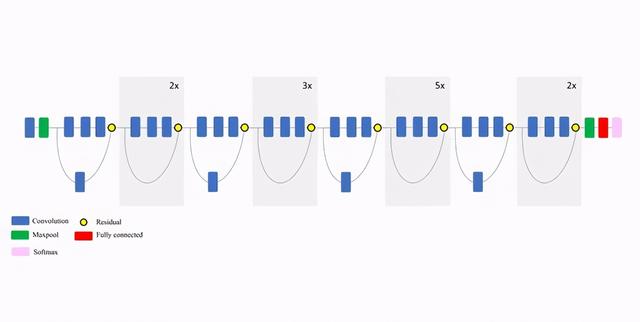
文章插图ResNet50 (Residual Network)ResNet50是一个卷积神经网络 , 深度为50层 。 它是由微软于2015年建立和训练的 , 论文:[Deep Residual Learning for Image Recognition](http://deep Residual Learning for Image Recognition /) 。 该模型对ImageNet数据库中的100多万张图像进行了训练 。 与VGG-19一样 , 它可以分类多达1000个对象 , 网络训练的是224x224像素的彩色图像 。 以下是关于其大小和性能的简要信息:
- 尺寸:98 MB
- Top-1 准确率:74.9%
- Top-5 准确率:92.1%
- 参数数量:25,636,712
 文章插图
文章插图
推荐阅读





![星巴克红茶拿铁怎么做?[红茶]](http://img.jiangsulong.com/220415/0151436496-0-lp.png)













- 大一非计算机专业的学生,如何利用寒假自学C语言
- 计算机专业大一下学期,该选择学习Java还是Python
- Mad Catz推出R.A.T. DWS无线电竞鼠标:配14个按钮
- 美国公司破解"刷脸支付"?用马云照片做实验,结果弹出4个大字
- 边缘计算点燃新风暴,IT与OT之战一触即发
- 赞!盐城高新区4个项目入选省级项目立项!
- 非计算机专业的本科生,想利用寒假学习Python,该怎么入手
- 计算机专业大三学生,如果想主攻前端开发,该重视哪些内容
- 手机网速慢?多半是这4个原因造成的,教你一招提升网速
- DeepMind新AI无需提前知晓规则也能掌握游戏:无论视觉简单还是复杂