DeepMind新AI无需提前知晓规则也能掌握游戏:无论视觉简单还是复杂
据外媒报道 , DeepMind的使命是向人们展示 , 人工智能不仅能够真正精通游戏甚至在不需要被告知游戏规则也能做到这一点 。 该公司最新的AI代理产品MuZero不仅可以通过具有复杂策略的视觉简单游戏如围棋、国际象棋和日本将棋实现这一目标 , 还可以通过视觉复杂的雅达利游戏实现这一目标 。
 文章插图
文章插图
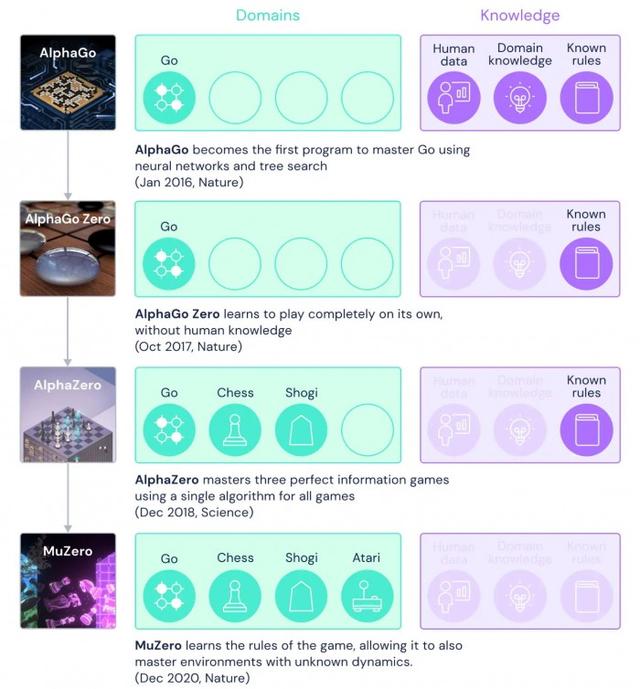
DeepMind的早期AI的成功至少在一定程度上得益于巨大决策树的非常有效的导航 , 这些决策树代表了游戏中可能的行动 。 在围棋或象棋中 , 这些树则是由非常具体的规则控制 , 如棋子的移动位置、这个棋子移动时会发生什么等等 。
在围棋比赛中击败世界冠军的AI AlphaGo在研究人类棋手之间和对手之间的比赛时了解了这些规则并把它们牢记于心从而形成了一套最佳实践和策略 。 它的续作AlphaGo Zero则在没有人类数据的情况下就做到了这一点 。 AlphaZero在2018年对围棋、象棋和将棋也做了同样的事情并由此创造了一个可以熟练玩所有这些游戏的AI模型 。
但在所有这些情况下 , AI都获得了一系列不变的已知游戏规则并围绕着这些规则创造了一个框架去创造自己的策略 。
 文章插图
文章插图
DeepMind在一篇关于他们新研究的博文中指出 , 如果AI提前被告知规则 , “这就很难将它们应用到混乱的现实世界问题中 , 这些问题通常都很复杂且很难提炼成简单的规则 。 ”
该公司的最新进展是MuZero , 它不仅可以玩上述游戏还可以玩雅达利的各种游戏 , 且完全无需任何规则手册 。 最终的模型不仅通过自己的实验(没有人类数据)甚至没有被告知最基本的规则就学会玩所有这些游戏 。
【DeepMind新AI无需提前知晓规则也能掌握游戏:无论视觉简单还是复杂】MuZero并没有使用规则去寻找最佳情况 , 而是学会考虑游戏环境的方方面面并自己观察它是否重要 。 在数以百万计的游戏中 , 它不仅学会了规则还学会了位置的一般价值、领先的一般政策以及事后评估自己行为的方法 。 据悉 , 后一种能力能帮助AI从自己的错误中吸取教训、重新开始并尝试不同的方法进而进一步完善位置和策略价值 。
推荐阅读


















- 华为P50 Pro亮点提前看:屏占比、颜值双双提升
- DeepMind巨亏42亿、独角兽惨遭3折贱卖,AI公司为何难有“好下场”?
- AMD Zen3 APU内核图提前偷跑:三级缓存质变
- 锐龙5000微代码更新:超频更稳、X570无需风扇
- 三星S21国行价提前泄密,比苹果12更便宜,小米11迎来强敌
- 5G已成“过去式”,美国6G提前布局,任正非早有预判
- 「商界早知道」消息称滴滴青桔正寻求五亿美元融资;美团取消支付宝渠道遭反垄断诉讼;12306网售时间提前至5点
- 儿子卖货爸爸买,DeepMind亏损多年谷歌竟表示满意?
- 买笔记本提前付款,提货时配置却降低了,顾客:不拿就要打我
- 发布|Intel 11代桌面酷睿1月量产:提前俩月出货