PythonзҪ‘з»ңзҲ¬иҷ«еҝ«йҖҹдёҠжүӢ
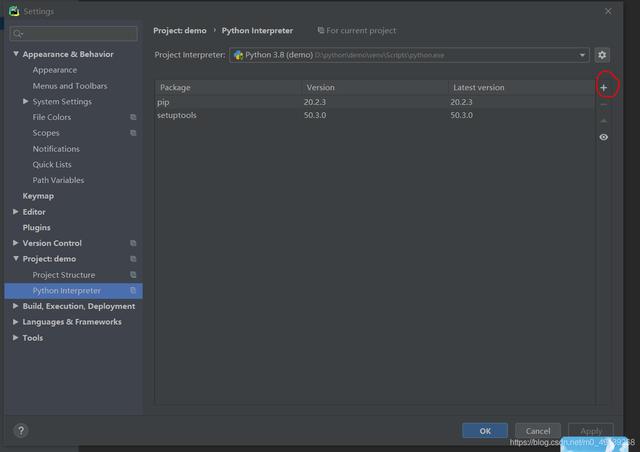
зҺҜеўғеҮҶеӨҮпјҡдәӢе…Ҳе®үиЈ…еҘҪ пјҢ pycharmжү“ејҖFileвҖ”вҖ”>SettingsвҖ”вҖ”>ProjextвҖ”вҖ”>Project Interpriter
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
зӮ№еҮ»еҠ еҸ·пјҲеӣҫдёӯзәўеңҲзҡ„ең°ж–№пјү
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
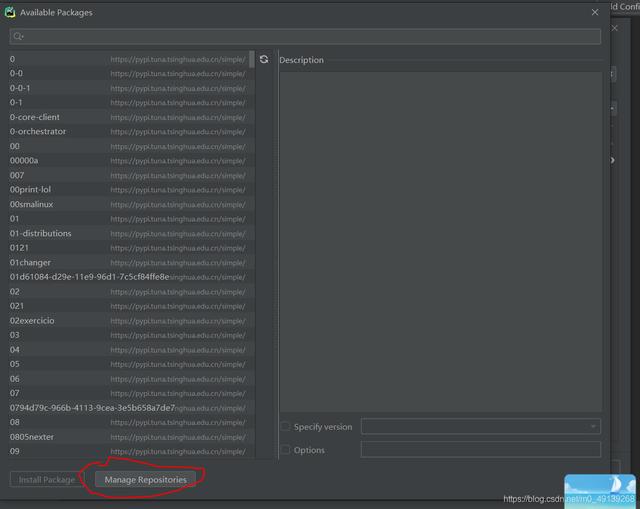
гҖҗPythonзҪ‘з»ңзҲ¬иҷ«еҝ«йҖҹдёҠжүӢгҖ‘зӮ№еҮ»зәўеңҲдёӯзҡ„жҢүй’®
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
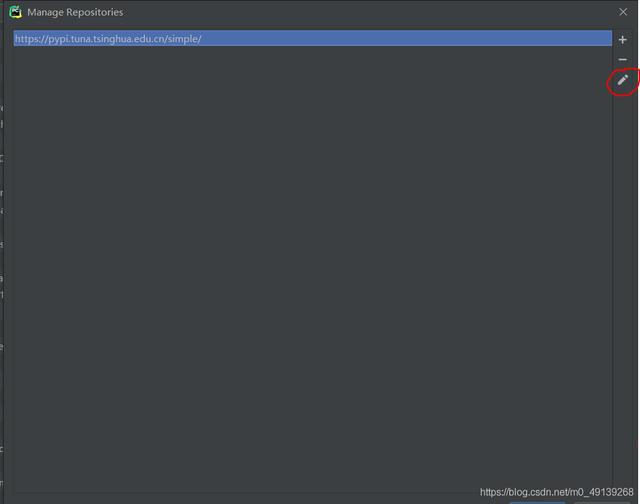
йҖүдёӯ第дёҖжқЎ пјҢ зӮ№еҮ»й“…笔 пјҢ е°ҶеҺҹжқҘзҡ„й“ҫжҺҘжӣҝжҚўдёәпјҲиҝҷйҮҢе·Із»ҸжӣҝжҚўиҝҮдәҶпјүпјҡзӮ№еҮ»OKеҗҺ пјҢ иҫ“е…Ҙrequests-html然еҗҺеӣһиҪҰйҖүдёӯrequests-htmlеҗҺзӮ№еҮ»Install Package
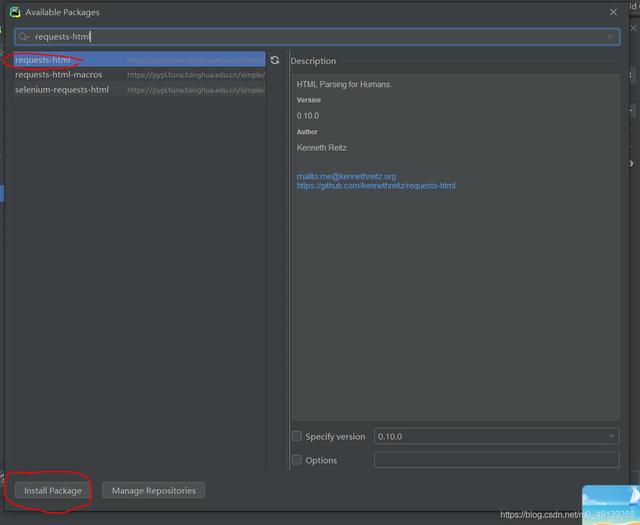 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
зӯүеҫ…е®үиЈ…жҲҗеҠҹ пјҢ е…ій—ӯ
йҖҡиҝҮи§ЈжһҗзҪ‘йЎөжәҗд»Јз Ғе®һдҫӢеҶ…е®№пјҡд»ҺжҹҗеҚҡдё»зҡ„жүҖжңүж–Үз« зҲ¬еҸ–жғіиҰҒзҡ„еҶ…е®№ гҖӮ е®һдҫӢиғҢжҷҜпјҡд»ҺпјҲпјүеҚҡдё»зҡ„жүҖжңүж–Үз« иҺ·еҸ–еҗ„ж–Үз« зҡ„ж Үйўҳ пјҢ ж—¶й—ҙ пјҢ йҳ…иҜ»йҮҸ гҖӮ
- еҜје…Ҙrequests_htmlдёӯHTMLSessionж–№жі• пјҢ 并еҲӣе»әе…¶еҜ№иұЎ
from requests_html import HTMLSessionsession = HTMLSession()123- дҪҝз”ЁgetиҜ·жұӮиҺ·еҸ–иҰҒзҲ¬зҡ„зҪ‘з«ҷ,еҫ—еҲ°иҜҘзҪ‘йЎөзҡ„жәҗд»Јз Ғ гҖӮ
html = session.get("").html12- жүҫеҲ°жүҖжңүж–Үз«
allBlog=html.xpath("//dl[@class='tab_page_list']") 1- иҝӣе…ҘзҪ‘з«ҷдё»йЎөпјҲжң¬дҫӢпјҡ пјү
- ж–Үз« з©әзҷҪеӨ„еҸій”®жЈҖжҹҘеҸҜд»Ҙе®ҡдҪҚеҲ°иҝҷж–Үз« зҡ„ж Үзӯҫ
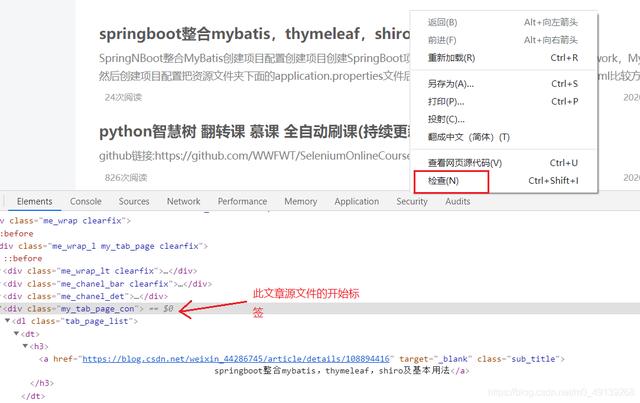 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ- е…¶д»–ж–Үз« дёҖж ·ж“ҚдҪң пјҢ 然еҗҺжүҫеҲ°жүҖжңүж–Үз« е…ұеҗҢзҡ„ж Үи®°пјҲиҝҷйҮҢжүҖжңүж–Үз« зҡ„classйғҪжҳҜвҖҳmy_tab_page_conвҖҷпјү
- xpath еҸҜд»ҘйҒҚеҺҶhtmlзҡ„еҗ„дёӘж Үзӯҫе’ҢеұһжҖ§ пјҢ жқҘе®ҡдҪҚеҲ°жҲ‘们йңҖиҰҒзҡ„дҝЎжҒҜзҡ„дҪҚзҪ® пјҢ 并жҸҗеҸ– гҖӮ
- зҪ‘йЎөеҲҶжһҗиҺ·еҸ–ж Үйўҳ пјҢ йҳ…иҜ»йҮҸ пјҢ ж—Ҙжңҹ гҖӮ
for i in allBlog:title = i.xpath("dl/dt/h3/a")[0].textviews = i.xpath("//div[@class='tab_page_b_l fl']")[0].textdate = i.xpath("//div[@class='tab_page_b_r fr']")[0].textprint(title +' ' +views +' ' + date )12345зҪ‘йЎөеҲҶжһҗпјҡ- еӣ дёәжңүеӨҡзҜҮж–Үз« пјҢ еҲҶеҲ«иҺ·еҸ–дҪҝз”ЁforеҫӘзҺҜ пјҢ дёҠиҝ°д»Јз Ғе·Іеҫ—еҲ°жүҖжңүж–Үз« жүҖд»ҘiиЎЁзӨәдёҖзҜҮж–Үз«
- 第дәҢиЎҢд»Јз ҒиҺ·еҸ–ж–Үз« ж Үйўҳ пјҢ дәҺиҺ·еҸ–ж–Үз« зұ»дјј пјҢ йј ж Үж”ҫеҲ°ж ҮйўҳдёҠеҸій”®жЈҖжҹҘ пјҢ еӣ дёәж–Үз« еҸӘжңүдёҖдёӘж ҮйўҳжүҖд»Ҙз”Ёз»қеҜ№и·Ҝеҫ„д№ҹеҸҜд»ҘжҢүж ҮзӯҫдёҖеұӮеұӮиҝӣеҲ°ж ҮйўҳдҪҚзҪ® гҖӮ
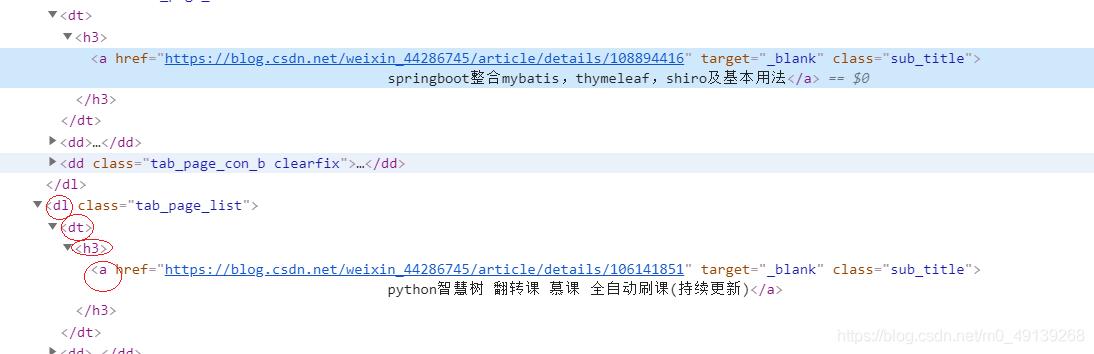 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ- xpathиҝ”еӣһзҡ„жҳҜеҲ—иЎЁ пјҢ жҲ‘们иҰҒ第дёҖдёӘжүҖд»ҘиҰҒеҠ дёӢж ҮпјҲеҲ—иЎЁйҮҢд№ҹеҸӘжңүдёҖдёӘе…ғзҙ пјү пјҢ иҰҒиҫ“еҮәзҡ„жҳҜж–Үжң¬ пјҢ жүҖд»Ҙ,textиҺ·еҸ–ж–Үжң¬ гҖӮ
- йҳ…иҜ»йҮҸе’Ңж—¶й—ҙд№ҹжҳҜйҮҚеӨҚзҡ„ж“ҚдҪң
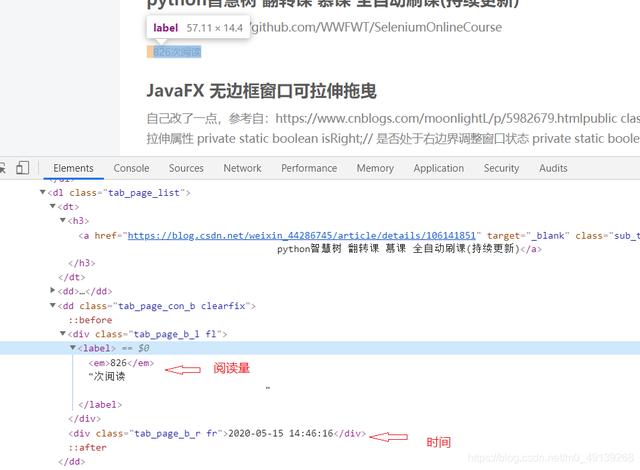 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ- еҸҜд»Ҙз”ЁзӣёеҜ№и·Ҝеҫ„д№ҹеҸҜд»Ҙз”Ёз»қеҜ№и·Ҝеҫ„ пјҢ дёҖиҲ¬йғҪжҳҜз”ЁзӣёеҜ№и·Ҝеҫ„ пјҢ ж јејҸд»ҝз…§д»Јз Ғ гҖӮ
- 第дә”иЎҢд»Јз Ғ пјҢ жҜҸеҫ—еҲ°дёҖзҜҮж–Үз« зҡ„дҝЎжҒҜе°ұиҫ“еҮә пјҢ йҒҚеҺҶе®Ңе°ұеҸҜд»ҘиҺ·еҫ—е…ЁйғЁзҡ„дҝЎжҒҜ гҖӮ
from requests_html import HTMLSessionsession = HTMLSession()html = session.get("").htmlallBlog=html.xpath("//dl[@class='tab_page_list']")for i in allBlog:title = i.xpath("dl/dt/h3/a")[0].textviews = i.xpath("//div[@class='tab_page_b_l fl']")[0].textdate = i.xpath("//div[@class='tab_page_b_r fr']")[0].textprint(title +' ' +views +' ' + date )1234567891011121314
жҺЁиҚҗйҳ…иҜ»
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- ж”№еҸҳзҪ‘з»ңеҢ–еҠһе…¬ жҸӯз§ҳеӨҸжҷ®ж–°еӨҚеҗҲжңәзі»еҲ—
- зҪ‘з»ңеҸҢйқўжҸҗйҖҹеҠһе…¬ еӨҸжҷ®еҸ‘еёғе…Ёж–°еӨҚеҚ°жңәзі»еҲ—
- и®Ўз®—жңәдё“дёҡеӨ§дёҖдёӢеӯҰжңҹпјҢиҜҘйҖүжӢ©еӯҰд№ JavaиҝҳжҳҜPython
- зҫҺеӘ’пјҡзҫҺеӣҪжӢүе°ҸејҹжҗһејҖж”ҫзҪ‘з»ң规иҢғж‘Ҷи„ұеҚҺдёә дҪҶжӣҙеӨҡдёӯеӣҪе…¬еҸёеҠ е…Ҙз«һдәүжҗ…й»„зҫҺж–№и®ЎеҲ’
- еҚҺдёәдёәжІіеҢ—вҖңзҒ«зңјвҖқе®һйӘҢе®ӨпјҲж°”иҶңзүҲпјүжҸҗдҫӣзҪ‘з»ңжҠҖжңҜдҝқйҡң
- жғіиҮӘеӯҰPythonжқҘејҖеҸ‘зҲ¬иҷ«пјҢйңҖиҰҒжҢүз…§е“ӘеҮ дёӘйҳ¶ж®өеҲ¶е®ҡеӯҰд№ и®ЎеҲ’
- жңӘжқҘжғіиҝӣе…ҘAIйўҶеҹҹпјҢиҜҘеӯҰд№ PythonиҝҳжҳҜJavaеӨ§ж•°жҚ®ејҖеҸ‘
- ж— зәҝзҪ‘з»ңиҒ”зӣҹпјҡWi-Fi 6EжҳҜдәҢеҚҒе№ҙжқҘжңҖйҮҚеӨ§зҡ„дёҖж¬ЎеҚҮзә§
- жүӢжңәзҪ‘з»ңзӘҒ然еҸҳжҲҗ2GпјҢе»ә议马дёҠе…іжҺүжүӢжңәпјҢе°ҸеҝғдҪ зҡ„й’ұиў«еҜ№ж–№иҪ¬иө°
- дёӯж¶ҲеҚҸзӮ№еҗҚеӨ§ж•°жҚ®зҪ‘з»ңжқҖзҶҹ еҸҚеҜ№еҲ©з”Ёж¶Ҳиҙ№иҖ…дёӘдәәж•°жҚ®з”»еғҸ





![жҳҹе·ҙе…ӢзәўиҢ¶жӢҝй“ҒжҖҺд№ҲеҒҡпјҹ[зәўиҢ¶]](http://img.jiangsulong.com/220415/0151436496-0-lp.png)