жЁЎеһӢ|жұҮиҒҡ4.5дёҮејҖеҸ‘иҖ…пјҢеҚҺдёәMindSpore 1.0жӯЈејҸеҸ‘еёғ
_еҺҹйўҳдёә жұҮиҒҡ4.5дёҮејҖеҸ‘иҖ… пјҢ еҚҺдёәMindSpore 1.0жӯЈејҸеҸ‘еёғ
жңәеҷЁд№ӢеҝғеҸ‘еёғ
жңәеҷЁд№Ӣеҝғзј–иҫ‘йғЁ

ж–Үз« еӣҫзүҮ
еӣҫ1 MindSpore 1.0жӯЈејҸеҸ‘еёғ
ејҖжәҗ6дёӘжңҲд»ҘжқҘ пјҢ MindSpore收иҺ·дәҶ4.5w+еҗҚејҖеҸ‘иҖ… пјҢ зҙҜи®ЎPRж•°1w+ пјҢ дёӢиҪҪдҪҝз”Ёз”ЁжҲ·йҒҚеёғе…Ёзҗғ пјҢ иҰҶзӣ–дәҡжҙІгҖҒ欧жҙІгҖҒеҚ—зҫҺгҖҒеҢ—зҫҺгҖҒйқһжҙІгҖҒзӯүеҗ„ең°еҢә пјҢ MindSpore Study GroupпјҲдёӢз®Җз§°MSGпјүеҗҜеҠЁ4дёӘжңҲдҫҝеңЁжө·еҶ…еӨ–еӨҡдёӘеҹҺеёӮйЎәеҲ©ејҖеұ• пјҢ ж·ұеңігҖҒжқӯе·һгҖҒиӢҸе·һгҖҒдёҠжө·гҖҒдҝ„зҪ—ж–ҜгҖҒж–°еҠ еқЎгҖҒеҚ°е°јеқҮе·Іе»әз«ӢMSGз»„з»Ү пјҢ еҒҡеҲ°дәҶзңҹжӯЈзҡ„е…ЁзҗғеҢ–зӨҫеҢә гҖӮ
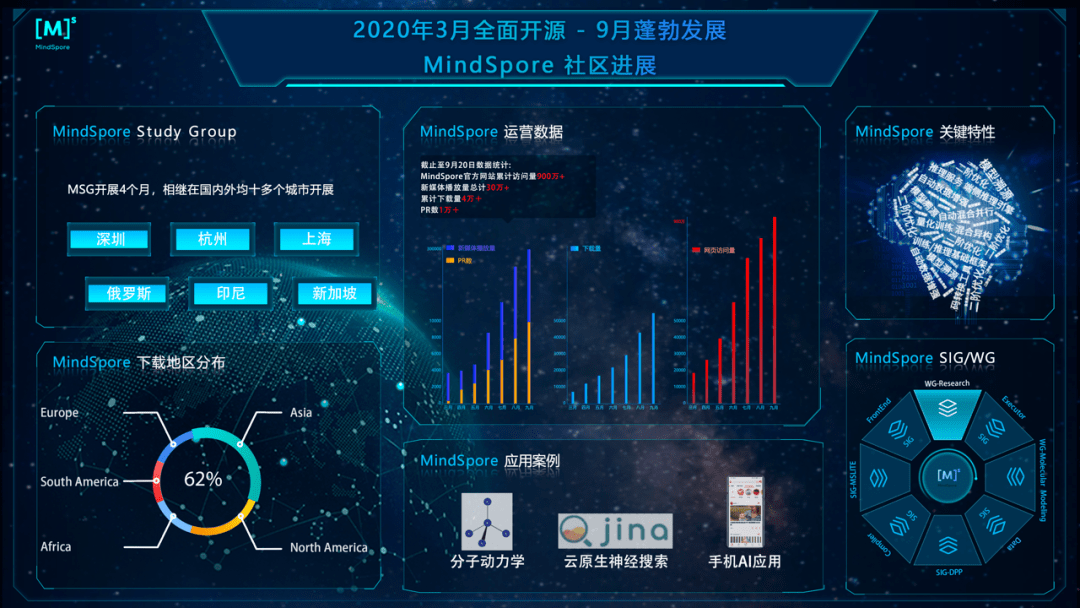
ж–Үз« еӣҫзүҮ
еӣҫ2 MindSporeејҖжәҗж•ҙдҪ“зӨҫеҢәиҝӣеұ•
1.0зүҲжң¬жҳҜдёҖдёӘйҮҢзЁӢзў‘ пјҢ жҳҜalphaгҖҒbetaзүҲжң¬зҡ„дёҖдёӘжІүж·Җ пјҢ д№ҹжҳҜжңӘжқҘзүҲжң¬зҡ„дёҖдёӘж–°иө·зӮ№ гҖӮ дёӢйқўз”Ё1еҲҶй’ҹи§Ҷйў‘еӣһйЎҫдёҖдёӢMindSporeд»ҺеҸ‘еёғгҖҒејҖжәҗеҲ°1.0зүҲжң¬зҡ„ж•ҙдҪ“еҺҶзЁӢе’ҢжҠҖжңҜзү№жҖ§ гҖӮ
и§Ҷйў‘пјҡMindSpore 1.0 зүҲжң¬1еҲҶй’ҹзү№жҖ§жҖ»з»“
дёүеӨ§еҲӣж–°еҠ©еҠӣе…ЁеңәжҷҜAIеә”з”Ё
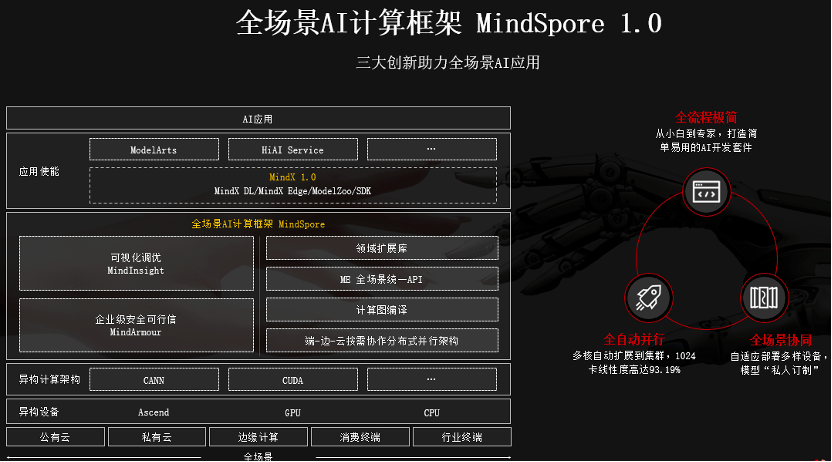
ж–Үз« еӣҫзүҮ
еӣҫ3 MindSpore 1.0е…ЁжҷҜеӣҫд»Ӣз»Қ
еҲӣж–°дёҖпјҡе…ЁжөҒзЁӢжһҒз®Җ пјҢ еӨҡеҘ—件жү“йҖ жһҒиҮҙејҖеҸ‘дҪ“йӘҢ
1. еҚіејҖеҚіз”Ё
еҪ“ејҖеҸ‘иҖ…ејҖеұ•ж–°йЎ№зӣ®ж—¶ пјҢ еҫҖеҫҖйңҖиҰҒд»Һжё…жҙ—ж•°жҚ®ејҖе§Ӣ пјҢ еҲ°и®ӯз»ғжЁЎеһӢ пјҢ жҺЁзҗҶйғЁзҪІзӯүеӨҡдёӘжөҒзЁӢ пјҢ жөҒзЁӢеӨҚжқӮ пјҢ иҖ—ж—¶иҫғд№… гҖӮ еңЁ1.0зүҲжң¬дёӯ пјҢ е®ҳж–№жҸҗдҫӣдәҶ40+дёӘе…ёеһӢзҡ„й«ҳжҖ§иғҪжЁЎеһӢ пјҢ иҰҶзӣ–дәҶCVгҖҒNLPгҖҒжҺЁиҚҗгҖҒиҜӯйҹізӯүеҗ„дёӘйўҶеҹҹ пјҢ еӨ§е®¶еҸҜд»ҘдҪҝз”ЁиҝҷдәӣжЁЎеһӢзӣҙжҺҘжҺЁзҗҶжҲ–иҖ…еҠ иҪҪиҮӘе·ұзҡ„ж•°жҚ®йӣҶеҒҡFine-tuning пјҢ иҝҷж ·еҸҜд»ҘиҠӮзңҒеӨ§йҮҸи®ӯз»ғзҡ„ж—¶й—ҙе’ҢжҲҗжң¬ пјҢ еҝ«йҖҹејҖеҸ‘еҮәжҷәиғҪзҡ„жңҚеҠЎе’Ңеә”з”Ё гҖӮ ејҖеҸ‘иҖ…们еҸҜд»ҘеңЁе®ҳзҪ‘зҡ„HubйЎөйқўдёӯйҖҡиҝҮзӯӣйҖүжқЎд»¶ пјҢ еҝ«йҖҹжүҫеҲ°иҮӘе·ұжғіиҰҒзҡ„йў„и®ӯз»ғжЁЎеһӢ пјҢ е®һзҺ°жЁЎеһӢејҖеҸ‘еҘ—件 пјҢ вҖңеҚіејҖеҚіз”ЁвҖқ гҖӮ
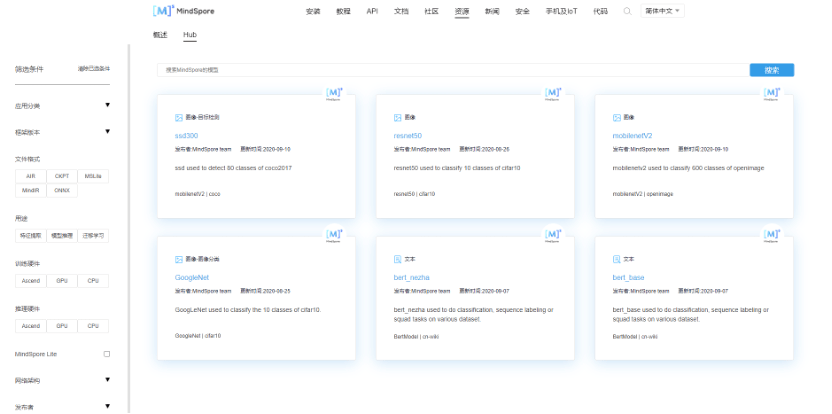
ж–Үз« еӣҫзүҮ
еӣҫ4 MindSpore Hubе®ҳзҪ‘йЎөйқў
2. жүҖи§ҒеҚіжүҖеҫ—
1.0зүҲжң¬дёӯ пјҢ MindSporeжҸҗдҫӣдәҶжүҖи§ҒеҚіжүҖеҫ—зҡ„жЁЎеһӢејҖеҸ‘е’Ңи°ғдјҳеҘ—件 гҖӮ еңЁжЁЎеһӢејҖеҸ‘йҳ¶ж®ө пјҢ MindSporeеҹәдәҺз»ҹдёҖзҡ„иҮӘеҠЁеҫ®еҲҶеј•ж“Һ пјҢ ж”ҜжҢҒз”ЁжҲ·з”ЁдёҖиЎҢд»Јз ҒеҲҮжҚўеҠЁжҖҒеӣҫе’ҢйқҷжҖҒеӣҫжЁЎејҸ пјҢ дҪҝеҫ—е…јйЎҫејҖеҸ‘ж•ҲзҺҮе’Ңжү§иЎҢж•ҲзҺҮ гҖӮ еңЁжЁЎеһӢи°ғдјҳйҳ¶ж®ө пјҢ MindInsightеҸҜи§ҶеҢ–и°ғдјҳе·Ҙе…·её®еҠ©з”ЁжҲ·жұҮжҖ»е’ҢеҲҶжһҗи°ғдјҳиҝҮзЁӢ пјҢ 并且еҗ‘жҺЁиҚҗеҗҲзҗҶзҡ„и°ғдјҳзӯ–з•Ҙ пјҢ еҠ йҖҹжЁЎеһӢи°ғдјҳиҝҮзЁӢ гҖӮ
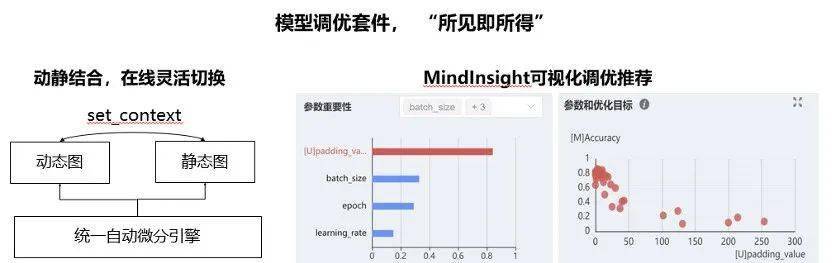
ж–Үз« еӣҫзүҮ
еӣҫ5 MindSpore жЁЎеһӢи°ғдјҳеҘ—件
еҰӮжһңдҪ е·ІдҪҝз”ЁPyTorchи®ӯз»ғжЁЎеһӢ пјҢ еҸҜд»ҘдҪҝз”ЁMindConverterе·Ҙе…·еҠ е°‘йҮҸзҡ„д»Јз ҒејҖеҸ‘ пјҢ еҚіеҸҜж–№дҫҝең°иҝҒ移еҲ°MindSporeжЎҶжһ¶ гҖӮ еҗҢж—¶MindSporeд№ҹж”ҜжҢҒPyTorchгҖҒTensorFlow LiteгҖҒCaffeзҡ„жЁЎеһӢж–Ү件зӣҙжҺҘиҪ¬дёәMindSporeжЁЎеһӢ гҖӮ иҝҷж ·е°ұиғҪйқһеёёж–№дҫҝең°дҪҝз”ЁMindSporeжҸҗдҫӣзҡ„е…ЁиҮӘеҠЁе№¶иЎҢзү№жҖ§ гҖӮ
еҲӣж–°дәҢпјҡе…ЁиҮӘеҠЁе№¶иЎҢ пјҢ жңҖеӨ§йҮҠж”ҫйӣҶзҫӨз®—еҠӣ

ж–Үз« еӣҫзүҮ
еӣҫ6 MindSporeиҮӘеҠЁе№¶иЎҢиҜҰи§Јеӣҫ
еңЁз®—жі•еұӮйқў пјҢ MindSporeжӢҘжңүиҮӘеҠЁе№¶иЎҢиғҪеҠӣ пјҢ еҸҜд»Ҙж №жҚ®йӣҶзҫӨй…ҚзҪ®еҜ№жЁЎеһӢе’Ңеј йҮҸиҮӘеҠЁеҲҮеҲҶ пјҢ е°ҶдёІиЎҢз®—жі•иҝӣиЎҢиҮӘеҠЁе№¶иЎҢ пјҢ еӨ§еӨ§еҮҸе°‘з®—жі•ејҖеҸ‘дәәе‘ҳзҡ„еҲҶеёғејҸд»Јз ҒејҖеҸ‘е’Ңи°ғдјҳзҡ„иҙҹжӢ… пјҢ дҪҝеҫ—з®—жі•и°ғдјҳж—¶й—ҙд»ҺжңҲзә§йҷҚеҲ°еӨ©зә§пјӣ
еңЁз®—еӯҗеұӮйқў пјҢ MindSporeжҸҗдҫӣдәҶз®—еӯҗзә§е№¶иЎҢиҮӘеҠЁиһҚеҗҲ пјҢ йҖҡиҝҮз»ҶзІ’еәҰpipelineзҡ„并иЎҢжү§иЎҢзҡ„ж–№ејҸ пјҢ иҝӣдёҖжӯҘжҸҗй«ҳи®Ўз®—жҖ§иғҪпјӣ
еңЁзЎ¬д»¶еұӮйқў пјҢ MindSporeиҝӣиЎҢж•ҙеӣҫи°ғеәҰ пјҢ еҸҜд»Ҙж №жҚ®и®Ўз®—зү№еҫҒ пјҢ иҮӘеҠЁжҠҠз®—еӯҗи°ғеәҰеҲ°ејӮжһ„и®ҫеӨҮдёҠжү§иЎҢ пјҢ е®һзҺ°ејӮжһ„еӨҡж ёзҡ„й«ҳж•Ҳ并иЎҢжү§иЎҢпјӣ
еңЁжӯӨеҹәзЎҖдёҠ пјҢ MindSporeеҚҸеҗҢAscendеӨ„зҗҶеҷЁ пјҢ еңЁеҲҶеёғејҸйӣҶзҫӨдёҠиҫҫеҲ°дәҶжҺҘиҝ‘зәҝжҖ§еҠ йҖҹжҜ” пјҢ ResNet50зҪ‘з»ңи®ӯз»ғеҗһеҗҗйҮҸжҸҗеҚҮдёӨеҖҚ пјҢ Bert-LargeзҪ‘з»ңи®ӯз»ғеҗһеҗҗйҮҸжҸҗеҚҮ3.2еҖҚ гҖӮ ејҖеҸ‘иҖ…еҸҜд»Ҙж–№дҫҝең°дҪҝз”ЁMindSporeе®һзҺ°еңЁеӨҡи®Ўз®—еҚ•е…ғдёҠ并иЎҢи®Ўз®— пјҢ ж—ўиғҪеӨ§е№…еҮҸе°‘ејҖеҸ‘йҮҸд»ҘеҸҠејҖеҸ‘йҡҫеәҰ пјҢ еҸҲиғҪдҪҝжҖ§иғҪжҢҒе№із”ҡиҮідјҳдәҺжүӢеҠЁи®ҫзҪ® гҖӮ еңЁReIDзҪ‘з»ңдёҠиҝӣиЎҢж··еҗҲ并иЎҢ пјҢ и„ҡжң¬д»Јз ҒйҮҸд»Һ130иЎҢ пјҢ зӣҙжҺҘеҸҳдёә1иЎҢ пјҢ дё”еҠ йҖҹжҜ”иғҪиҫҫеҲ°88%д»ҘдёҠ гҖӮ
еҲӣж–°дёүпјҡе…ЁеңәжҷҜеҚҸеҗҢе…ЁеңәжҷҜеҚҸеҗҢ пјҢ жҷәиғҪеҢ№й…Қз«ҜгҖҒиҫ№гҖҒдә‘еӨҡж ·и®ҫеӨҮMindSpore 1.0жҸҗдҫӣжЁЎеһӢиҮӘйҖӮеә”з”ҹжҲҗиғҪеҠӣ пјҢ йҖҡиҝҮе№іиЎЎжЁЎеһӢзІҫеәҰе’Ңи®ҫеӨҮиө„жәҗзәҰжқҹ пјҢ иҮӘеҠЁжҗңзҙўеҢ№й…Қзҡ„жЁЎеһӢ пјҢ ејҖеҸ‘иҖ…еҸӘйңҖиҰҒеҒҡдёҖж¬Ўи®ӯз»ғ пјҢ еҫ—еҲ°зҡ„жЁЎеһӢе°ұеҸҜд»ҘеңЁз«ҜгҖҒиҫ№гҖҒдә‘зӯүеӨҡеӨ„йғЁзҪІ пјҢ еҸҜдҝқиҜҒз”ҹжҲҗзҡ„зІҫеәҰжҚҹеӨұе°ҸдәҺ1%пјӣеҜ№дәҺе·Із»ҸйғЁзҪІзҡ„жЁЎеһӢ пјҢ MindSporeжҸҗдҫӣдәҶиҪ»йҮҸеҢ–зҡ„з«Ҝдҫ§еӯҰд№ иғҪеҠӣ пјҢ еҸ‘жҢҘз§Ғдәәж•°жҚ®зҡ„д»·еҖј пјҢ жҢҒз»ӯжҸҗеҚҮжЁЎеһӢзІҫеәҰ пјҢ и®©жҷәиғҪи®ҫеӨҮи¶Ҡз”Ёи¶ҠжҮӮдҪ гҖӮ еңЁжЎҶжһ¶ж–№йқў пјҢ дёәдәҶеӨҡж ·еҢ–и®ҫеӨҮзҡ„иө„жәҗзәҰжқҹ пјҢ MindSporeеҸҜд»ҘеҒҡеҲ°KBеҲ°MBзә§зҡ„еј№жҖ§дјёзј© пјҢ ж—ўеҸҜд»ҘйғЁзҪІеҲ°й«ҳз«ҜжүӢжңә пјҢ еҸҲеҸҜд»ҘйғЁзҪІеҲ°жүӢиЎЁзӯүеҜ№иө„жәҗиҰҒжұӮжһҒдёәиӢӣеҲ»зҡ„и®ҫеӨҮ пјҢ д»ҺиҖҢж»Ўи¶іе…ЁеңәжҷҜйғЁзҪІзҡ„йңҖжұӮ гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- зЎ®иҜҠз—…дҫӢ|жҢҒз»ӯжҒ¶еҢ–пјҒеҚҒжңҲ第дёҖе‘ЁзҫҺеӣҪж—ҘеқҮж–°еўһзЎ®иҜҠз—…дҫӢи¶…4.5дёҮ
- ж је…°д»•|ж је…°д»•дёҺеӣҪзҫҺзӯҫзҪІжҲҳз•ҘеҗҲдҪңеҚҸи®® е®һзҺ°ж–°йӣ¶е”®з”ҹжҖҒжЁЎеһӢ
- йЎ¶жөҒ|欧жҙҫж©ұжҹңжҺЁеҠЁдёӯеӣҪеҺЁжҲҝиҝӣе…Ҙ4.0ж—¶д»ЈпјҢжұҮиҒҡе…ЁзҗғйЎ¶жөҒе“ҒзүҢжү“йҖ е…ЁзҗғжҲҳз•ҘиҒ”зӣҹ
- зғӯе°”жӣјВ·жүҳе·ҙе°”|ж—¶й—ҙж—…иЎҢеҸҜд»ҘжңүпјҹеӨ§еӣӣеӯҰз”ҹе»әз«Ӣж•°еӯҰжЁЎеһӢиҜҒжҳҺеҸҜиЎҢжҖ§
- еӨ§зҜ·иҪҰ|и®©зҲұеҝғжұҮиҒҡ еҠ©жўҰжғіеҗҜиҲӘ--вҖңеӨ§зҜ·иҪҰвҖқ驶е…ҘеҚҺи°Ҡе…„ејҹйҮҚеәҶиўҒ家岗еҪұйҷў
- PTM|д№ҳйЈҺз ҙжөӘзҡ„ PTMпјҢж·ұеәҰи§ЈиҜ»йў„и®ӯз»ғжЁЎеһӢзҡ„иҝӣеұ•
- еүҚиҪ®йғҪжңүдёҖе®ҡ|йӯ”еӣўйҳҹгҖҗжЁЎеһӢиҜ„жөӢгҖ‘第еҚҒдәҢжңҹ еӨҡиҠұзҡ„170е…ғеҲ°еә•еҖјдёҚеҖј?йҮҺ马зү№иҫ‘
- еҲҳжӣҷеі°|жҒ’з”ҹз”өеӯҗеҲҳжӣҷеі°пјҡжІЎжңүж•°жҚ®жІүж·ҖпјҢж— жі•и®©AIжЁЎеһӢжңүз”ЁжӯҰд№Ӣең°
- жЁЎеһӢ|DataCanvasпјҲд№қз« дә‘жһҒпјүе…ҘйҖү IDC Fintech 50ејә
- дјҒдёҡ|еҚҒдёҖз§Қе…Ёзҗғи‘—еҗҚе•ҶдёҡеҲҶжһҗжЁЎеһӢ