PTM|д№ҳйЈҺз ҙжөӘзҡ„ PTMпјҢж·ұеәҰи§ЈиҜ»йў„и®ӯз»ғжЁЎеһӢзҡ„иҝӣеұ•
жңәеҷЁд№ӢеҝғиҪ¬иҪҪ
жқҘжәҗпјҡзҹҘд№Һ
дҪңиҖ…пјҡеј дҝҠжһ—
иҮӘи°·жӯҢ 2018 е№ҙ 10 жңҲжҺЁеҮә BERT жЁЎеһӢд»ҘжқҘпјҢеҗ„ејҸеҗ„ж ·зҡ„ж”№иҝӣзүҲйў„и®ӯз»ғжЁЎеһӢпјҲPre-Training Model, PTMпјүеұӮеҮәдёҚз©·пјҢдёә NLP йўҶеҹҹжҢҒз»ӯиөӢиғҪгҖӮеңЁиҝ‘дёӨе№ҙзҡ„ж—¶й—ҙйҮҢпјҢеҮәзҺ°дәҶе“Әдәӣд»ӨдәәеҚ°иұЎж·ұеҲ»зҡ„ж–°жЁЎеһӢе‘ўпјҹеҸҲеҰӮдҪ•жү“йҖ жңҖејәзҡ„йў„и®ӯз»ғжЁЎеһӢе‘ўпјҹиҝ‘ж—ҘпјҢдёӯ科йҷўиҪҜ件жүҖеҚҡеЈ«гҖҒж–°жөӘеҫ®еҚҡ AI Lab жӢ…д»»иө„ж·ұз®—жі•дё“е®¶еј дҝҠжһ—д»ҘзҺ°жңүжҠҖжңҜж–ҮзҢ®дёәеҹәзЎҖпјҢиҜ•еӣҫеӣһзӯ”йў„и®ӯз»ғжЁЎеһӢзӣёе…ізҡ„дёҖзі»еҲ—й—®йўҳгҖӮ
д»ҘдёӢжҳҜеј дҝҠжһ—зҡ„еҺҹеё–еҶ…е®№пјҡ
Bert жЁЎеһӢиҮӘ 18 е№ҙ 10 жңҲжҺЁеҮәпјҢеҲ°зӣ®еүҚдёәжӯўеҝ«дёӨе№ҙдәҶгҖӮе®ғеҚңдёҖй—®дё–еҚіеј•иө·иҪ°еҠЁпјҢд№ӢеҗҺпјҢеҗ„з§Қж”№иҝӣзүҲжң¬зҡ„йў„и®ӯз»ғжЁЎеһӢпјҲPre-Training Model, PTMпјүдёҺеә”з”ЁеҰӮиҝҮжұҹд№ӢйІ«пјҢеұӮеҮәдёҚз©·гҖӮBert еҸҠе®ғзҡ„继任иҖ…们пјҢзЎ®е®һд№ҹдёҚеӯҡдј—жңӣпјҢеңЁ NLP еҗ„дёӘйўҶеҹҹж”»еҹҺз•Ҙең°пјҢжүҖеҗ‘жҠ«йқЎпјҢеӨҡз§Қ NLP ж•°жҚ®йӣҶз«һиөӣжҰңеҚ•пјҢиҝһз»ӯеӨҡе№ҙиў«еҗ„з§Қж–°еҮәзҺ°зҡ„йў„и®ӯз»ғжЁЎеһӢйңёжҰңпјҢжңүдәӣжҰңеҚ•пјҢдёӘеҲ«жЁЎеһӢе·Із»ҸжҠҠжҢҮж ҮеҲ·еҲ°и¶…иҝҮдәәзұ»гҖӮ
йӮЈд№ҲпјҢеңЁиҝ‘дёӨе№ҙзҡ„ж—¶й—ҙйҮҢпјҢиҜёеӨҡж”№иҝӣжЁЎеһӢдёӯпјҢжңүе“Әдәӣд»ӨдәәеҚ°иұЎж·ұеҲ»зҡ„ж–°жЁЎеһӢпјҹеңЁйӮЈдәӣиЎЁзҺ°зӘҒеҮәзҡ„ж–°жЁЎеһӢдёӯпјҢжҳҜе“Әдәӣеӣ зҙ еҜјиҮҙе®ғ们зҡ„иүҜеҘҪиЎЁзҺ°пјҹйў„и®ӯз»ғжЁЎеһӢжҠҖжңҜжң¬иә«жңүйҮҚеӨ§зҡ„ж”№еҠЁжҲ–еҲӣж–°д№ҲпјҹжҲ–иҖ…пјҢе…ідәҺйў„и®ӯз»ғжЁЎеһӢпјҢзӣ®еүҚжңүе“ӘдәӣзӣёеҜ№жҳҺзЎ®зҡ„з»“и®әпјҹж №жҚ®зӣ®еүҚзҡ„жҠҖжңҜеҸ‘еұ•ж°ҙеҮҶпјҢеҰӮдҪ•ж №жҚ®зҺ°жңүз»“и®әпјҢжқҘжү“йҖ жңҖејәзҡ„йў„и®ӯз»ғжЁЎеһӢпјҹжң¬ж–ҮйҖҡиҝҮжўізҗҶзҺ°жңүжҠҖжңҜж–ҮзҢ®пјҢиҜ•еӣҫжқҘеӣһзӯ”дёҠиҝ°дёҖзі»еҲ—й—®йўҳгҖӮжң¬ж–Үзҡ„ж•°жҚ®йғҪе®ўи§ӮжңүеҮәеӨ„пјҢдҪҶжҳҜеҜ№ж•°жҚ®зҡ„и§ЈиҜ»пјҢеёҰжңүдёҘйҮҚзҡ„дёӘдәәиүІеҪ©пјҢеҒҸйўҮйҡҫе…ҚпјҢиҝҳиҜ·и°Ёж…ҺеҸӮиҖғгҖӮеҸҰеӨ–пјҢеҰӮиҰҒйҖҸеҪ»зҗҶи§Јжң¬ж–ҮпјҢйңҖиҰҒжңүе…ідәҺйў„и®ӯз»ғжЁЎеһӢзҡ„е…ҲеҜјеҹәзЎҖзҹҘиҜҶпјҢеҜ№иҝҷдёӘдёҚеӨӘдәҶи§Јзҡ„еҗҢеӯҰпјҢе»әи®®е…Ҳйҳ…иҜ»дёӢж–Үжү“дёӘеҹәзЎҖгҖӮ
ж–Үз« ең°еқҖпјҡhttps://zhuanlan.zhihu.com/p/49271699
жҲ‘们зҹҘйҒ“пјҢеңЁйў„и®ӯз»ғжЁЎеһӢжЎҶжһ¶дёӢпјҢи§ЈеҶі NLP й—®йўҳпјҢдјҡеҲ’еҲҶдёәеәҸеҲ—иҝӣиЎҢзҡ„дёӨйҳ¶ж®өпјҡ第дёҖйҳ¶ж®өжҳҜйў„и®ӯз»ғйҳ¶ж®өпјҢ然еҗҺжҳҜ Fine-tuning йҳ¶ж®өпјҢжң¬ж–ҮйӣҶдёӯеңЁйў„и®ӯз»ғйҳ¶ж®өгҖӮ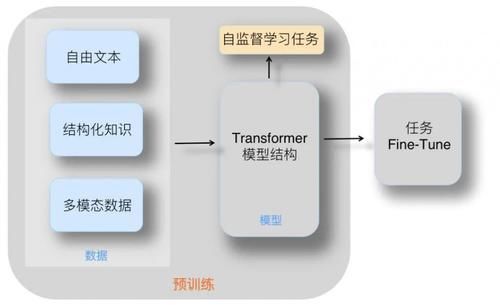
ж–Үз« еӣҫзүҮ
еҰӮжһңжҲ‘们дёҖеҸҘиҜқе®Ҹи§Ӯең°еҪ’зәійў„и®ӯз»ғжЁЎеһӢиҰҒеҒҡзҡ„дәӢжғ…пјҲеҸӮиҖғдёҠеӣҫпјүпјҢе…¶е®һеҫҲеҘҪзҗҶи§ЈпјҢе°ұжҳҜдёӢйқўиҝҷеҸҘиҜқпјҡеңЁ Transformer дҪңдёәзү№еҫҒжҠҪеҸ–еҷЁеҹәзЎҖдёҠпјҢйҖүе®ҡеҗҲйҖӮзҡ„жЁЎеһӢз»“жһ„пјҢйҖҡиҝҮжҹҗз§ҚиҮӘзӣ‘зқЈеӯҰд№ д»»еҠЎпјҢйҖјиҝ« Transformer д»ҺеӨ§йҮҸж— ж ҮжіЁзҡ„иҮӘз”ұж–Үжң¬дёӯеӯҰд№ иҜӯиЁҖзҹҘиҜҶгҖӮиҝҷдәӣиҜӯиЁҖзҹҘиҜҶд»ҘжЁЎеһӢеҸӮж•°зҡ„ж–№ејҸпјҢеӯҳеӮЁеңЁ Transformer з»“жһ„дёӯпјҢд»ҘдҫӣдёӢжёёд»»еҠЎдҪҝз”ЁгҖӮ
жҲ‘们и§ҒеҲ°зҡ„еҪўеҪўиүІиүІзҡ„йў„и®ӯз»ғжЁЎеһӢпјҢж— йқһе°ұжҳҜпјҢе®һзҺ°дёҠиҝ°жҖқи·Ҝзҡ„е…·дҪ“еҒҡжі•иҖҢе·ІгҖӮдҪ еҸҜд»ҘжҚўдёӘжЁЎеһӢз»“жһ„пјҢеҸҜд»ҘжҚўдёӘеӯҰд№ д»»еҠЎпјҢд№ҹеҸҜд»ҘжҚўдёӘе…¶е®ғзҡ„йғЁд»¶пјҢж— йқһе°ұжҳҜеҗ„з§ҚиҜ•пјҢеҪ“然пјҢжңүдәӣеҒҡжі•зӣёеҜ№жңүж•ҲпјҢжңүдәӣеҒҡжі•ж•Ҳжһңе·®дәӣгҖӮдёҖиҲ¬иҖҢиЁҖпјҢйҖҡеёёжүҖиҜҙзҡ„йў„и®ӯз»ғжЁЎеһӢпјҢйғҪжҳҜд»ҺиҮӘз”ұж–Үжң¬дёӯеӯҰд№ иҜӯиЁҖзҹҘиҜҶпјҢеҫҲжҳҺжҳҫпјҢжҲ‘们еҸҜд»Ҙеј•е…Ҙж–°еһӢзҡ„зҹҘиҜҶжҲ–ж•°жҚ®пјҢжҜ”еҰӮдәәзұ»е·Із»ҸжҢ–жҺҳеҘҪзҡ„з»“жһ„еҢ–зҹҘиҜҶгҖҒеӨҡжЁЎжҖҒж•°жҚ®гҖҒеӨҡиҜӯиЁҖж•°жҚ®зӯүпјҢеј•е…ҘиҝҷдәӣзҹҘиҜҶжқҘдҝғиҝӣжЁЎеһӢзҗҶи§ЈиҜӯиЁҖпјҢжҲ–иҖ…и§ЈеҶізү№ж®Ҡзұ»еһӢзҡ„д»»еҠЎгҖӮ
еҗҺж–Үдјҡе…Ҳд»Ӣз»Қйў„и®ӯз»ғжЁЎеһӢдёӯеёёи§Ғзҡ„еҮ з§ҚжЁЎеһӢз»“жһ„пјҢ并з»ҷеҮәзӣ®еүҚиғҪеҫ—еҮәзҡ„з»“и®әгҖӮ然еҗҺпјҢжҲ‘们дјҡжүҫеҮәзӣ®еүҚиЎЁзҺ°жҜ”иҫғеҘҪзҡ„йӮЈдәӣйў„и®ӯз»ғжЁЎеһӢпјҢ并еҲҶжһҗе®ғ们иө·дҪңз”Ёзҡ„дё»иҰҒеӣ зҙ жҳҜд»Җд№ҲгҖӮжҺҘдёӢжқҘпјҢдјҡз®ҖиҰҒд»Ӣз»ҚеҮ з§ҚйқһиҮӘз”ұж–Үжң¬зұ»зҹҘиҜҶеӯҰд№ зҡ„йў„и®ӯз»ғеҹәжң¬ж–№жі•гҖӮ
еңЁи°Ҳиҝҷдәӣд№ӢеүҚпјҢжҲ‘们е…Ҳд»Һ RoBERTa и®Іиө·гҖӮеҰӮжһңж—¶е…үеҖ’йҖҖеҚҠе№ҙеӨҡпјҢдҪ дјҡеҸ‘зҺ°пјҢиҝҷжҳҜдёҖдёӘд»·еҖјиў«дёҘйҮҚдҪҺдј°зҡ„жЁЎеһӢпјҢе…¶е®һпјҢе®ғеҫҲйҮҚиҰҒгҖӮ
йў„и®ӯз»ғжЁЎеһӢдёӯзҡ„ејәеҹәеҮҶпјҡRoBERTa
дёҘж јжқҘиҜҙпјҢеҺҹе§Ӣзҡ„ Bert жЁЎеһӢжҳҜдёӘжңӘе®ҢжҲҗзҡ„еҚҠжҲҗе“ҒпјҢиҖҢ RoBERTa жүҚжҳҜйҒөеҫӘ Bert жҖқи·Ҝзҡ„е®ҢжҲҗе“ҒпјҢжҲ–иҖ…иҜҙпјҢBert жҳҜиҝӣиЎҢж—¶дёӯзҡ„ RoBERTaпјҢд№ҹе°ұжҳҜиҜҙдёӢеҲ—зӯүејҸжҲҗз«Ӣ Bert=RoBERTingгҖӮдёәд»Җд№Ҳиҝҷд№ҲиҜҙе‘ўпјҹеӣ дёәпјҢжҲ‘们еҸҜд»ҘжҠҠ RoBERTa зңӢдҪңжҳҜеҫ—еҲ°е……еҲҶи®ӯз»ғзҡ„ Bert жЁЎеһӢпјҢиҖҢеҺҹе§ӢзүҲжң¬зҡ„ Bert жЁЎеһӢи®ӯз»ғдёҚеӨҹе……еҲҶпјҢиҝҷз§ҚжЁЎеһӢжҳҜеҗҰеҫ—еҲ°е……еҲҶи®ӯз»ғзҡ„еҫ®е°Ҹе·®ејӮпјҢиғҪеӨҹжһҒеӨ§жҸҗеҚҮеҺҹе§ӢзүҲжң¬ Bert жЁЎеһӢзҡ„ж•ҲжһңгҖӮ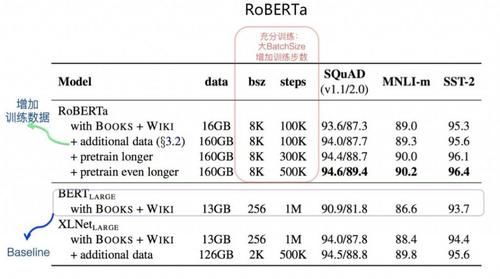
ж–Үз« еӣҫзүҮ
еңЁеҺҹе§Ӣ Bert жЁЎеһӢзҡ„еҹәзЎҖдёҠпјҢRoBERTa йҖҡиҝҮе®һйӘҢпјҢиҜҒжҳҺдәҶеҰӮдёӢеҮ зӮ№пјҡиҝӣдёҖжӯҘеўһеҠ йў„и®ӯз»ғж•°жҚ®ж•°йҮҸпјҢиғҪеӨҹж”№е–„жЁЎеһӢж•Ҳжһңпјӣ
延й•ҝйў„и®ӯз»ғж—¶й—ҙжҲ–еўһеҠ йў„и®ӯз»ғжӯҘж•°пјҢиғҪеӨҹж”№е–„жЁЎеһӢж•Ҳжһңпјӣ
жҖҘеү§ж”ҫеӨ§йў„и®ӯз»ғзҡ„жҜҸдёӘ Batch зҡ„ Batch SizeпјҢиғҪеӨҹжҳҺжҳҫж”№е–„жЁЎеһӢж•Ҳжһңпјӣ
жӢҝжҺүйў„и®ӯз»ғд»»еҠЎдёӯзҡ„ Next Sentence Prediction еӯҗд»»еҠЎпјҢе®ғдёҚеҝ…иҰҒеӯҳеңЁпјӣ
иҫ“е…Ҙж–Үжң¬зҡ„еҠЁжҖҒ Masking зӯ–з•Ҙжңүеё®еҠ©гҖӮ
дёҠйқўеҲ—еҮәзҡ„дә”йЎ№ж”№иҝӣдёӯпјҢ第еӣӣйЎ№е’Ң第дә”йЎ№ж”№еҠЁпјҢеҜ№жңҖз»Ҳзҡ„жЁЎеһӢж•ҲжһңеҪұе“ҚдёҚеӨ§пјҢжҡӮж—¶еҸҜеҝҪз•ҘгҖӮ第дёҖзӮ№ж”№иҝӣеўһеҠ йў„и®ӯз»ғж•°жҚ®еҜ№жЁЎеһӢж•Ҳжһңжңүеё®еҠ©пјҢиҝҷдёӘз¬ҰеҗҲзӣҙи§үгҖӮ第дәҢйЎ№е’Ң第дёүйЎ№еҲҷж¶үеҸҠеҲ°жЁЎеһӢжҳҜеҗҰеҫ—еҲ°е……еҲҶи®ӯз»ғпјҢжң¬иҙЁдёҠиҝҷдёӨйЎ№зӣёз»“еҗҲпјҢд»ЈиЎЁдәҶжӣҙе……еҲҶи®ӯз»ғзҡ„ Bert жЁЎеһӢгҖӮеҰӮдёҠйқўзҡ„жҖ§иғҪеҜ№жҜ”еӣҫжүҖзӨәпјҢеҰӮжһңд»Ҙ Bert Large дҪңдёәеҜ№жҜ”еҹәеҮҶпјҢеҸҜд»ҘеҸ‘зҺ°пјҡд»…д»…е°Ҷ Batch Size ж”ҫеӨ§пјҢдёүдёӘж•°жҚ®йӣҶдёҠзҡ„ж•Ҳжһңе°ұиҺ·еҫ—дәҶжҳҺжҳҫжҸҗеҚҮпјҢеҰӮжһңеҶҚеҠ е…Ҙж–°зҡ„ж•°жҚ®пјҢд»ҘеҸҠдёҚж–ӯеўһеҠ и®ӯз»ғжӯҘж•°пјҢиҝҳиғҪжҢҒз»ӯиҺ·еҫ—ж•Ҳжһңзҡ„иҝӣдёҖжӯҘжҸҗеҚҮгҖӮеҸҜд»ҘзңӢеҮәпјҢRoBERTa ж•ҲжһңжҳҺжҳҫжҜ” Bert large еҘҪпјҢеңЁзӣёеҗҢж•°жҚ®жғ…еҶөдёӢпјҢз”ҡиҮіи¶…иҝҮдәҶзҹҘеҗҚеәҰеҫҲй«ҳзҡ„ XLNetгҖӮиҝҷдё»иҰҒеҪ’еҠҹдәҺж•°жҚ®и§„жЁЎзҡ„еўһеҠ пјҢд»ҘеҸҠжӣҙе……еҲҶзҡ„и®ӯз»ғиҝҮзЁӢпјҢе…¶дёӯжӣҙе……еҲҶзҡ„и®ӯз»ғиҝҮзЁӢеҸ‘жҢҘзҡ„дҪңз”ЁжӣҙеӨ§дәӣгҖӮиҝҷжҳҜдёәдҪ•иҜҙ RoBERTa еңЁжҹҗз§Қж„Ҹд№үдёҠпјҢе…¶е®һжҳҜдёҖдёӘе®ҢжҲҗзүҲжң¬жҲ–иҖ…еҠ ејәзүҲжң¬зҡ„ Bert жЁЎеһӢгҖӮ
жҺЁиҚҗйҳ…иҜ»














- йҳҹеҸӢ|жІҲжўҰиҫ°жӣқе…үйҳҹеҸӢвҖңдё‘з…§вҖқпјҢдҪҶжҳҫзӨәеҮәиүҜеҘҪзҡ„дәәж°”
- е…¬жј”|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢ第дә”ж¬Ўе…¬жј”зҺ°еңәпјҢжқҺж–Ҝдё№еҰ®з»„гҖҠжғ…дәәгҖӢеӨӘжғҠиүі
- зјәдҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- ж—¶е°ҡзӢӮжғіжӣІ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еҲ¶еӣўз»јпјҢеј йӣЁз»®з«ҷпјЈдҪҚпјҢз®ҖзәҰиЎ¬иЎЈзҪ•и§Ғз§ҖзҹҘжҖ§
- еҪ’дҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- 10жңҲ|еҚ°еәҰеҸ‘з”ҹ5.1зә§ең°йңҮпјҢйңҮжәҗж·ұеәҰ40еҚғзұі
- йҷҲиө«|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢжҲҗеӣўеӨңиҜ·дәҶ17дҪҚз”·еҳүе®ҫпјҢйҷҲиө«жғ№жқҘдёҖзүҮдәүи®®
- иҠӮзӣ®з»„|еӯҹдҪіпјҢеҲ«жҢЈжүҺдәҶпјҢгҖҠд№ҳйЈҺз ҙжөӘгҖӢиҠӮзӣ®з»„жҳҺж‘ҶзқҖжғіжҠҠдҪ ж·ҳжұ°
- е®Ғйқҷ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еӣўз»јпјҢе®ҒйқҷдёҮиҢңз ҙдёҚе’Ңдј й—»пјҢи·Ҝжј”и§Ҷйў‘ж¬ўд№җеӨҡ
- ж¶ҲжҒҜиө„и®Ҝ|д№ҳйЈҺз ҙжөӘ | еҸҳйқ©иҪ¬еһӢпјҡдәәжүҚеҹ№е…»вҖ”вҖ”дјҒдёҡиҪ¬еһӢдёҺеҲӣж–°зҡ„ж ёеҝғй©ұеҠЁеҠӣ