用户|如何实现一个跨库连表SQL生成器?( 二 )
消息填充:中间表添加消息队列(中间表更新可以触发下游节点)。
大宽表填充:填充大宽表数据。
连接链对齐:中间表和大宽表连接键对齐。
ETL填充:填充大宽表列的ETL信息。
分区字段填充:填充大宽表分区字段。
SQL填充:填充Flink同步表映射SQL语句, Flink计算SQL语句, Flink结果表映射SQL语句。
保存:把SQL和建表数据存入数据库, 之后的请求可以复用已有的数据, 避免重复建表。
异步发布阶段会把SQL语句发布到Flink。
添加反向索引的原因
假如有A、B两表连接,那么连接方式为A表的非主键连接B表主键。从时序上来说可能有以下三种情况:
B表数据先于A表数据多天产生
B表数据后于A表数据多天产生
B表数据和A表数据同时产生
下面我们就这三种情况逐一分析。
场景1:B表数据先于A表数据多天产生
我们假如B表数据存储于某个支持高qps的数据库内,我们可以直接让A表数据到来时直接连接此表(维表)来实现连表。
场景2:B表数据后于A表数据多天产生
这种场景比较麻烦。A表数据先行产生,因此过早的落库,导致B表数据到来时即使连接B维表也拿不到数据。这种场景还有一个类似的场景:如果AB连接完成后B发生了更新,如何让B的更新体现在宽表中?
为了解决这种问题,我们增加了一个“反向索引表”。假如A的主键是id,连接键是ext_id,那么我们可以将ext_id和id的值存储在一张表内,当B的数据更新时,用B的主键连接这种表的ext_id字段,拉取到所有的A表id字段,并将A表id字段重新流入Flink。
三设计模式
对系统整体流程有了解以后, 我们再来看看系统的设计模式选择,选择设计模式时,我们考虑到数据处理相关的开发工作存在一些共性:
拆解后小功能多
小功能存在复用情况
小功能执行有严格的先后顺序
需要记录小功能运行状态, 流程执行可回滚或者中断可恢复执行
由于数据处理任务的步奏比较冗长,而且由于每个阶段的结果与下阶段的执行有关系,又不能分开。
参考 PipeLine(流水线)设计模式[2],综合考虑后我们系统的整体设计如下图所示: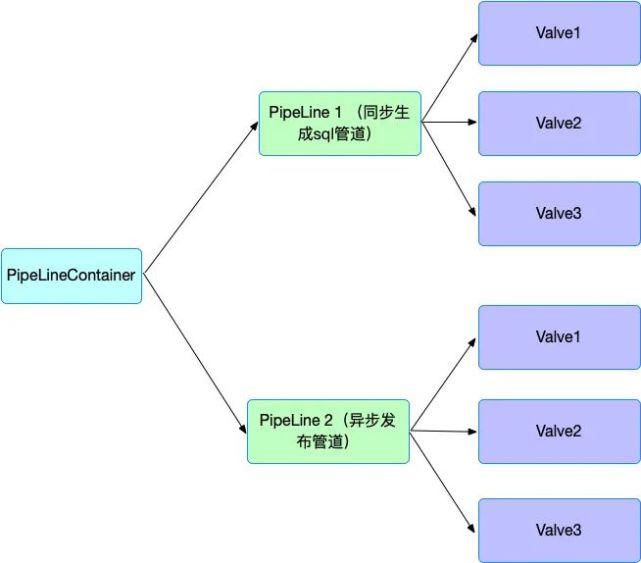
文章图片
首先有一个全局的PipeLineContainer管理多个pipeLine和pipeline context, 每个pipeline可独立执行一个任务, 比如pipeline1执行同步生成sql任务。pipeline2执行异步发布任务。发布必须在生成SQL结束后执行, pipeline有状态并且按一定顺序串联。每个pipeline包含多个可重用的valve(功能)。valve可以重用, 任意组合,方便完成更多的数据处理任务(比如以后如果要支持Tisplus dump平台接入, 则简单拼接现有的valve就可以)。
四数据结构和算法
问题说明
SQL生成器关键点, 就是把各个表(Meta节点)之间的关系表示出来。Meta之间的关系分为两类,分别是全连接关联和左连接关联(因为左连接关联涉及到数据的时序问题, 需要添加反向索引较为复杂, 所以和全连接区分了一下, 为了简化问题我们先执行全连接, 再执行左连接)。
我们要解决的问题是, 多个数据源同步数据进来之后, 按一定的优先级关联, 最终得到一个大宽表并需要自动发布。抽象到数据结构层面就是:
每个同步进来的数据源对应一个叶子节点
节点之间有关联关系,关联关系有多类并有执行优先级
所有节点和关联关系组成一棵树
最终得到一个根节点(大宽表)并发布
算法思路
下面说明下解决该问题的算法思路。
优先级队列
因为叶子节点之间连接执行优先级不同,先放入优先级队列。之后每次取出高优先级任务执行。相同优先级任务可以复用, 连续执行多次。优先级队列示意图如下: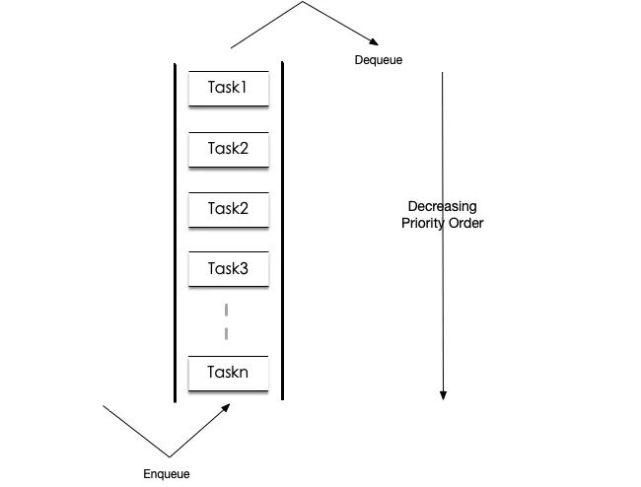
文章图片
构建树
有了优先级队列的概念, 我们来构建树。构建主要分以下步骤:
首先得到四种优先级的任务, 优先级从高到低分别为:
优先级1, 六个节点的同步任务
优先级2,节点1、2、3和节点4、5的Full Join任务
优先级3,节点1、4和节点6的Left Join任务
优先级4, 发布任务
取优先级1的任务执行,同步进来六个数据源对应六个叶子。
取优先级2的任务并执行得到中间表1,2。
取优先级3的任务并执行,发现节点1、4有父节点, 则执行中间节点1、2分别和节点6 Left Join得到根节点。
取优先级4的任务并执行,发布根节点。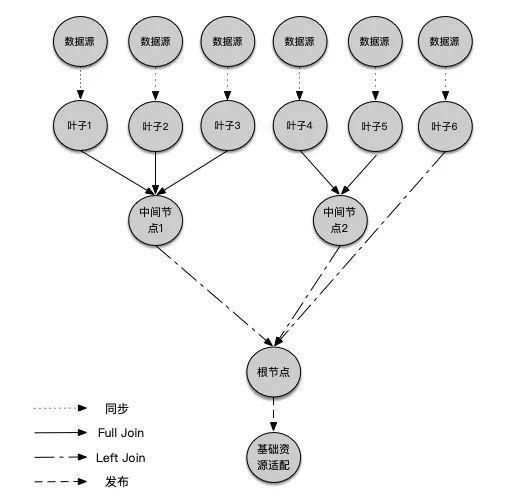
文章图片
可以看到最终的数据结构是一棵树, 通过这种方式我们能支持复杂sql的自动构建。进一步抽象, 这种“一个队列驱动一棵树生成”的模式可以解决一类问题:
问题的解决由一系列不同优先级的任务组成, 任务需要复用。
通过从队列取优先级高的任务的方式构建任务关系树。
最后遍历树完成各个节点任务。
五总结
限于篇幅, 本文重点在于介绍自动生成sql功能开发中运用到的主要数据结构和设计模式思想。
推荐阅读

















- 街舞3|嘉宾频频“串门”,节目实现“双赢”
- 闲置|手机欠费超三个月将上征信,闲置卡以及宽带用户要小心了
- 流感|流感如何应对?听听郑州市九院儿科主任杨平怎么说的
- 蠢萌新闻|《急先锋》成龙的“接棒”杨洋,年轻演员们表现如何?
- 观览天下|一块石头卖到十万,看村民们如何发家致富,你心动了吗?
- 乡村波比|野猪被禁止食用,农村野猪泛滥,糟蹋庄稼,该如何解决?
- 科学|王莽有可能是穿越者吗?穿越时空可以实现吗?
- 气象卫星|一文读懂风云气象卫星50年如何改变中国,未来两次发射“值得期待”
- 科学|世界3大未解之谜:生命起源、地球内核、宇宙之谜,该如何解释?
- 光速|如何超越光速?|No.227