用户|如何实现一个跨库连表SQL生成器?

文章图片
阿里妹导读:用户只需在前端简单配置下指标,系统即可自动生成大宽表,让用户查询到他所需要的实时数据,数据源支持跨库并支持多种目标介质。这样的数据全局实时可视化如何实现?本文从需求分析开始,分享自动生成SQL功能开发中运用到的设计模式和数据结构算法设计。
文末福利:藏经阁100本电子书免费下载。
一概述
ADC(Alibaba DChain Data Converger)项目的主要目的是做一套工具,用户在前端简单配置下指标后,就能在系统自动生成的大宽表里面查询到他所需要的实时数据,数据源支持跨库并支持多种目标介质。说的更高层次一点, 数据的全局实时可视化这个事情本身就是解决供应链数据“神龙效应”的有效措施(参考施云老师的《供应链架构师》[1]一书)。做ADC也是为了这个目标,整个ADC系统架构如下图所示: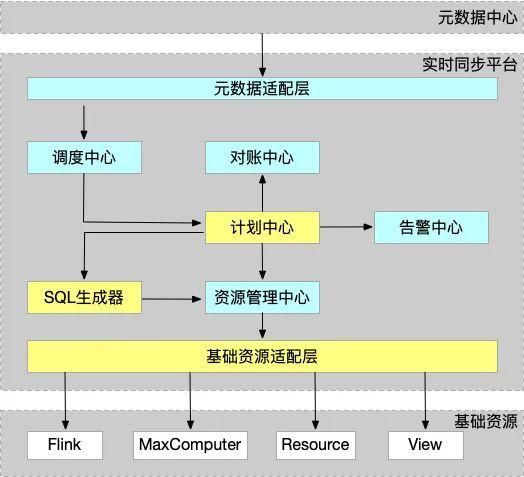
文章图片
架构解析:
初始数据来自于元数据中心。
经过元数据适配层后转换为内部格式数据。
调度中心把内部格式的数据传到计划中心,计划中心分析数据需求并建模,通过SQL生成器生成资源和SQL,分别通过告警中心、对账中心设定监控标准和对账标准。
对账中心定时对账,查看数据的对齐情况。
告警中心可以针对任务错误、延迟高等情况发送报警。
资源的生命周期管控在资源管理中心下,view删除时资源管理中心负责回收资源。
基础资源适配层主要借助集团基础资源管理能力串联阿里各类数据服务, 比如阿里云MaxComputer、Flink、阿里云AnalyticDB等。
其中,SQL生成器的上游和下游主要涉及:
上游计划中心
配置指标:用户在前端配置他想看的数据有哪些。
生产原始数据:根据用户输入得到哪些表作为数据源, 以及它们之间的连接关系。
下游Metric适配器
把SQL发布到Flink, 根据建表数据建物理表。
本文主要从技术角度介绍下SQL生成器相关的内容。
二技术实现
在项目实施阶段,需要从需求分析、技术方案设计、测试联调几个步骤展开工作。本文重点不放在软件开发流程上, 而是就设计模式选择和数据结构算法设计做下重点讲解。
需求分析
在需求分析阶段, 我们明确了自动生成SQL模块所需要考虑的需求点, 主要包含如下几点:
需要支持多个事实表(流表)、多个维度表连表,其中一个事实表是主表,其他的均为辅助表。
维表变动也应当引起最终数据库更新。
主表对辅助表为1:1或N1,也就是说主表的粒度是最细的, 辅表通过唯一键来和主表连接。
流表中可能存在唯一键一致的多张流表, 需要通过全连接关联。唯一键不同的表之间通过左连接关联。
只有连表和UDF,没有groupby操作。
要求同步延时较小,支持多种源和目标介质。由于查询压力在目标介质,所以查询qps没有要求。
系统流程图
明确需求后, 我们把SQL生成器总体功能分为两块:
同步生成SQL和建表数据
异步发布SQL和建表
之所以把生成SQL阶段做成同步是因为同步阶段内存操作为主,如果发现数据有问题无法生成SQL能做到快速失败。发布阶段调用Metrics需要同步等待较长时间, 每个发布步骤要做到有状态记录, 可回滚或者重试。所以异步实现。SQL生成器同步阶段的整体功能细化到小模块,如下图所示: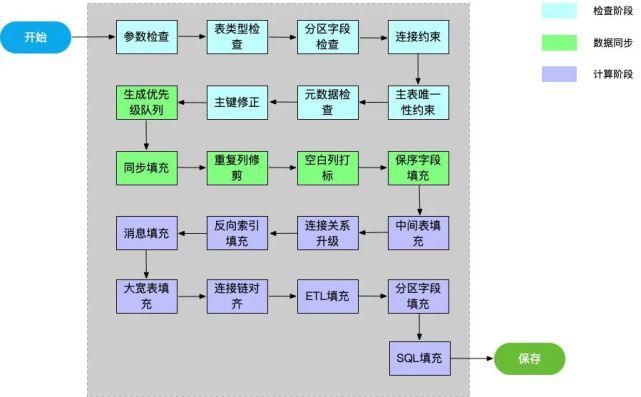
文章图片
检查阶段
检查原始数据是否有问题, 无法生成SQL则快速失败。
参数检查:检查上游是否提供了基本的参数, 比如事实表信息(可以没有维表, 但是必须有事实表)。
表类型检查:检查数据来源类型是否支持。
分区字段检查:是否提供了大宽表分区字段。
连接约束:检查流表,维表连接信息是否正确。
主表唯一性约束:检查主表是否含连接信息,唯一键是否有ETL信息。
元数据检查:检查是否包含HBase配置信息。
主键修正:修正维表连接键, 必须是维表的唯一键。
数据同步
同步所有原始表和原始表的连接数据(比如源表同步进来, 生成1:1的HBase表)。
生成优先级队列:生成连接和发布等任务的执行优先级。
同步填充:填充源表对应的同步阶段HBase表数据,和对应的配置项, 类型转换(比如源表是MySQL表,字段类型要转换为HBase的类型), ETL填充, 添加消息队列(通过发送消息的方式通知下游节点运行)。
重复列修剪:删除重复的列。
空白列打标:对于满足一定条件(比如不需要在大宽表展示, 不是唯一键列, 连接键列, 保序列)的列打上空白列标识。
保序字段填充:如果上游提供了表示数据创建时间的字段, 则用该字段作为数据保序字段, 没有则填充系统接收到数据的时间作为保序字段。
计算阶段
生成大宽表,填充SQL。
中间表填充:填充全连接产生的中间表。
连接关系升级:会在本文后面说明。
反向索引填充:填充“反向索引”信息。
推荐阅读


















- 街舞3|嘉宾频频“串门”,节目实现“双赢”
- 闲置|手机欠费超三个月将上征信,闲置卡以及宽带用户要小心了
- 流感|流感如何应对?听听郑州市九院儿科主任杨平怎么说的
- 蠢萌新闻|《急先锋》成龙的“接棒”杨洋,年轻演员们表现如何?
- 观览天下|一块石头卖到十万,看村民们如何发家致富,你心动了吗?
- 乡村波比|野猪被禁止食用,农村野猪泛滥,糟蹋庄稼,该如何解决?
- 科学|王莽有可能是穿越者吗?穿越时空可以实现吗?
- 气象卫星|一文读懂风云气象卫星50年如何改变中国,未来两次发射“值得期待”
- 科学|世界3大未解之谜:生命起源、地球内核、宇宙之谜,该如何解释?
- 光速|如何超越光速?|No.227