жЁЎеһӢ|8.6Mи¶…иҪ»йҮҸдёӯиӢұж–ҮOCRжЁЎеһӢејҖжәҗпјҢи®ӯз»ғйғЁзҪІдёҖжқЎйҫҷ | DemoеңЁзәҝеҸҜзҺ©( дәҢ )
ж–Үз« еӣҫзүҮ
йҷӨжӯӨд№ӢеӨ– пјҢ ејҖеҸ‘дәәе‘ҳиҝҳйҮҮз”ЁеҮҸе°Ҹзү№еҫҒйҖҡйҒ“ж•°зӯүзӯ–з•Ҙ пјҢ иҝӣдёҖжӯҘеҜ№жЁЎеһӢеӨ§е°ҸиҝӣиЎҢдәҶеҺӢзј© гҖӮ
жЁЎеһӢиҷҪе°Ҹ пјҢ дҪҶжҳҜи®ӯз»ғз”ЁеҲ°зҡ„ж•°жҚ®йӣҶеҚҙдёҖзӮ№д№ҹдёҚе°‘ пјҢ ж №жҚ®йЎ№зӣ®ж–№з»ҷеҮәзҡ„ж•°жҚ® пјҢ жЁЎеһӢз”ЁеҲ°зҡ„ж•°жҚ®йҮҸпјҲеҢ…жӢ¬еҗҲжҲҗж•°жҚ®пјүеӨ§зәҰеңЁзҷҫдёҮеҲ°еҚғдёҮйҮҸзә§ гҖӮ

ж–Үз« еӣҫзүҮ
дҪҶжҳҜд№ҹжңүејҖеҸ‘иҖ…еҸҜиғҪдјҡй—® пјҢ еңЁжҹҗдәӣеһӮзұ»еңәжҷҜ пјҢ йҖҡз”ЁOCRжЁЎеһӢзҡ„зІҫеәҰеҸҜиғҪдёҚиғҪж»Ўи¶ійңҖжұӮ пјҢ иҖҢдё”з®—жі•жЁЎеһӢеңЁе®һйҷ…йЎ№зӣ®йғЁзҪІд№ҹдјҡйҒҮеҲ°еҗ„з§Қй—®йўҳ пјҢ еә”иҜҘжҖҺд№ҲеҠһе‘ўпјҹ

ж–Үз« еӣҫзүҮ
PaddleOCRд»Һи®ӯз»ғеҲ°йғЁзҪІ пјҢ жҸҗдҫӣдәҶйқһеёёе…Ёйқўзҡ„дёҖжқЎйҫҷжҢҮеј• пјҢ е Әз§°гҖҢжңҖе…ЁOCRејҖеҸ‘иҖ…еӨ§зӨјеҢ…гҖҚ гҖӮ
гҖҢжңҖе…ЁOCRејҖеҸ‘иҖ…еӨ§зӨјеҢ…гҖҚ

ж–Үз« еӣҫзүҮ
в–ізӨјеҢ…зӣ®еҪ• пјҢ е Әз§°дёҡз•ҢжңҖе…Ё
ж”ҜжҢҒиҮӘе®ҡд№үи®ӯз»ғ
OCRдёҡеҠЎе…¶е®һжңүзү№ж®ҠжҖ§ пјҢ з”ЁжҲ·зҡ„йңҖжұӮеҫҲйҡҫйҖҡиҝҮдёҖдёӘйҖҡз”ЁжЁЎеһӢжқҘж»Ўи¶і пјҢ д№ӢеүҚејҖжәҗзҡ„Chineseocr_Liteд№ҹжҳҜдёҚж”ҜжҢҒз”ЁжҲ·и®ӯз»ғзҡ„ гҖӮ
дёәдәҶж–№дҫҝејҖеҸ‘иҖ…дҪҝз”ЁиҮӘе·ұзҡ„ж•°жҚ®иҮӘе®ҡд№үи¶…иҪ»йҮҸжЁЎеһӢ пјҢ йҷӨдәҶ8.6Mи¶…иҪ»йҮҸжЁЎеһӢеӨ– пјҢ PaddleOCRеҗҢж—¶жҸҗдҫӣдәҶ2з§Қж–Үжң¬жЈҖжөӢз®—жі•пјҲEASTгҖҒDBпјүгҖҒ4з§Қж–Үжң¬иҜҶеҲ«з®—жі•пјҲCRNNгҖҒRossetaгҖҒSTAR-NetгҖҒRAREпјү пјҢ еҹәжң¬еҸҜд»ҘиҰҶзӣ–еёёи§ҒOCRд»»еҠЎзҡ„йңҖжұӮ пјҢ 并且算法иҝҳеңЁжҢҒз»ӯдё°еҜҢдёӯ гҖӮ
зү№еҲ«жҳҜгҖҢжЁЎеһӢи®ӯз»ғ/иҜ„дј°гҖҚдёӯзҡ„гҖҢдёӯж–ҮOCRи®ӯз»ғйў„жөӢжҠҖе·§гҖҚ пјҢ жӣҙжҳҜи®©дәәзңјеүҚдёҖдә® пјҢ зӮ№иҝӣеҺ»еҸҜд»ҘзңӢеҲ°гҖҢдёӯж–Үй•ҝж–Үжң¬иҜҶеҲ«зҡ„зү№ж®ҠеӨ„зҗҶгҖҒеҰӮдҪ•жӣҙжҚўдёҚеҗҢзҡ„backboneзӯүдёҡеҠЎе®һжҲҳжҠҖе·§гҖҚ пјҢ зӣёеҪ“з¬ҰеҗҲејҖеҸ‘иҖ…йЎ№зӣ®е®һжҲҳдёӯзҡ„зӮјдё№йңҖжұӮ гҖӮ

ж–Үз« еӣҫзүҮ
жү“йҖҡйў„жөӢйғЁзҪІе…ЁжөҒзЁӢ
еҜ№ејҖеҸ‘иҖ…жӣҙеҸӢеҘҪзҡ„жҳҜ пјҢ PaddleOCRжҸҗдҫӣдәҶжүӢжңәз«ҜпјҲеҗ«iOSгҖҒAndroid DemoпјүгҖҒеөҢе…ҘејҸз«ҜгҖҒеӨ§и§„жЁЎж•°жҚ®зҰ»зәҝйў„жөӢгҖҒеңЁзәҝжңҚеҠЎеҢ–йў„жөӢзӯүеӨҡз§Қйў„жөӢе·Ҙ具组件зҡ„ж”ҜжҢҒ пјҢ иғҪеӨҹж»Ўи¶іеӨҡж ·еҢ–зҡ„е·Ҙдёҡзә§еә”з”ЁеңәжҷҜ гҖӮ
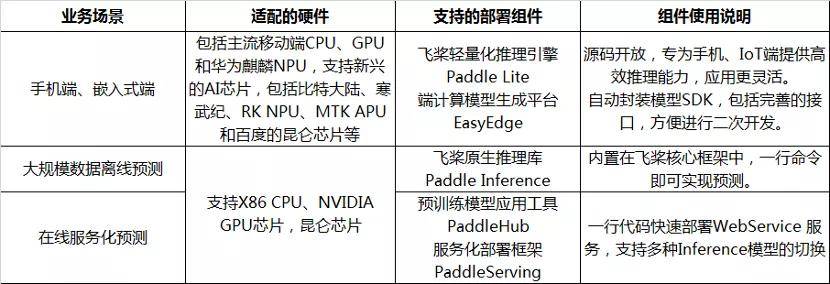
ж–Үз« еӣҫзүҮ
ж•°жҚ®йӣҶжұҮжҖ»
йЎ№зӣ®её®ејҖеҸ‘иҖ…ж•ҙзҗҶдәҶеёёз”Ёзҡ„дёӯж–Үж•°жҚ®йӣҶгҖҒж ҮжіЁе’ҢеҗҲжҲҗе·Ҙе…· пјҢ 并еңЁжҢҒз»ӯжӣҙж–°дёӯ гҖӮ
зӣ®еүҚеҢ…еҗ«зҡ„ж•°жҚ®йӣҶеҢ…жӢ¬пјҡ
- 5дёӘеӨ§и§„жЁЎйҖҡз”Ёж•°жҚ®йӣҶпјҲICDAR2019-LSVT пјҢ ICDAR2017-RCTW-17 пјҢ дёӯж–ҮиЎ—жҷҜж–Үеӯ—иҜҶеҲ« пјҢ дёӯж–Үж–ҮжЎЈж–Үеӯ—иҜҶеҲ« пјҢ ICDAR2019-ArTпјү
- еӨ§и§„жЁЎжүӢеҶҷдёӯж–Үж•°жҚ®йӣҶпјҲдёӯ科йҷўиҮӘеҠЁеҢ–з ”з©¶жүҖ-жүӢеҶҷдёӯж–Үж•°жҚ®йӣҶпјү
- еһӮзұ»еӨҡиҜӯиЁҖOCRж•°жҚ®йӣҶпјҲдёӯеӣҪеҹҺеёӮиҪҰзүҢж•°жҚ®йӣҶгҖҒ银иЎҢдҝЎз”ЁеҚЎж•°жҚ®йӣҶгҖҒйӘҢиҜҒз Ғж•°жҚ®йӣҶ-CaptchaгҖҒеӨҡиҜӯиЁҖж•°жҚ®йӣҶпјү
并且ејҖжәҗд»ҘжқҘ пјҢ еҸ—еҲ°ејҖеҸ‘иҖ…зҡ„е№ҝжіӣе…іжіЁ пјҢ е·Із»ҸжңүеӨ§йҮҸејҖеҸ‘иҖ…жҠ•е…ҘеҲ°йЎ№зӣ®зҡ„е»әи®ҫдёӯ并且иҙЎзҢ®еҶ…е®№ гҖӮ
ж–Үз« еӣҫзүҮ
зңҹВ·е№Іиҙ§ж»Ўж»Ў гҖӮ

ж–Үз« еӣҫзүҮ
дҪ“йӘҢдёҖдёӢпјҹ
зңӢеҲ°иҝҷйҮҢ пјҢ дҪ еҝғеҠЁдәҶеҗ—пјҹеҰӮжһңиҝҳжғізңји§Ғдёәе®һ пјҢ PaddleOCRе·Із»ҸжҸҗдҫӣдәҶеңЁзәҝDemo пјҢ зҪ‘йЎөзүҲгҖҒжүӢжңәз«ҜеқҮеҸҜе°қиҜ• гҖӮ
ж„ҹе…ҙи¶Јзҡ„иҜқ收еҘҪдёӢйқўзҡ„дј йҖҒй—Ё пјҢ дәІиҮӘдҪ“йӘҢиө·жқҘеҗ§~
дј йҖҒй—Ёпјҡ
йЎ№зӣ®ең°еқҖпјҡ
https://github.com/PaddlePaddle/PaddleOCR
зҪ‘йЎөзүҲDemoпјҡ
https://www.paddlepaddle.org.cn/hub/scene/ocr
移еҠЁз«ҜDemoпјҡ
йЎ№зӣ®з»„дёәејҖеҸ‘иҖ…еңЁзҷҫеәҰеӨ§и„‘EasyEdgeдёҠејҖж”ҫдәҶеҹәдәҺйЈһжЎЁиҪ»йҮҸеҢ–жҺЁзҗҶеј•ж“ҺPaddle Liteе®һзҺ°зҡ„APP demo гҖӮ
гҖҗжЁЎеһӢ|8.6Mи¶…иҪ»йҮҸдёӯиӢұж–ҮOCRжЁЎеһӢејҖжәҗпјҢи®ӯз»ғйғЁзҪІдёҖжқЎйҫҷ | DemoеңЁзәҝеҸҜзҺ©гҖ‘iOSзүҲжң¬з”ұдәҺиҜҒд№ҰйҷҗеҲ¶ пјҢ йңҖиҰҒзҷ»еҪ•зҷҫеәҰEasyEdgeзҪ‘йЎөжү«з ҒдҪ“йӘҢпјҡhttps://ai.baidu.com/easyedge/app/openSource?from=paddlelite
жҺЁиҚҗйҳ…иҜ»











![[е®қе®қ,еӨӘйҳій•ң,е®қе®қ,еӨӘйҳій•ң]е°Ҹд№ҲиҜҫе Ӯпјҡ6еІҒд»ҘдёӢзҡ„е®қе®қдёҚиғҪеёҰеӨӘйҳій•ңпјҒ](http://img.jiangsulong.com/200324/8_0324235Z3bX.jpg)


- еҺЁеёҲе»әз«Ӣ|зҺӢиҖ…иҚЈиҖҖпјҡеӨҸжҙӣзү№зҡ®иӮӨжЁЎеһӢйў„и§ҲпјҢи”Ўж–Ү姬з№Ғжҳҹеҗҹжёёзҡ®иӮӨдјҳеҢ–еҚҮзә§пјҒ
- зӣёдәІ|ж•°еӯҰ家зҡ„зӣёдәІжЁЎеһӢпјҢдҪ жҲ–и®ёеҸҜд»Ҙз”ЁеҲ°пјҢзӣёдәІдёҚеӨҹжңүж•Ҳзҡ„еҺҹеӣ еңЁжӯӨ
- йЈҺйҷ©жЁЎеһӢ|зәҝдёҠз”іиҜ·ж¶Ҳиҙ№дҝЎз”Ёиҙ·пјҹ新规жҳҺзЎ®еҚ•жҲ·йўқеәҰдёҚи¶…20дёҮе…ғ
- зӣёдәІ|ж•°еӯҰ家зҡ„зӣёдәІжЁЎеһӢпјҢдҪ жҲ–и®ёеҸҜд»Ҙз”ЁеҲ°пјҢзӣёдәІдёҚеӨҹжңүж•Ҳзҡ„еҺҹеӣ еңЁжӯӨ
- еҶізӯ–жЁЎеһӢ|дёәд»Җд№ҲеӨ§еӨҡж•°дәәзҡ„е»әи®®пјҢйғҪжІЎжңүеҸӮиҖғд»·еҖјпјҹ
- жҲ‘д№°еҲ°дәҶiPhone12е’Ң12 ProзңҹжңәжЁЎеһӢ д»Ҡе№ҙзЎ®е®һеҸҳеҢ–еҫҲеӨ§
- е’Ңзҡ®зҡ®йҫҷдёҖиө·зңӢи§Ҷйў‘еӣһзӯ”й—®йўҳпјҢжңүжңәдјҡиҺ·еҫ—еҠЁзү©жЁЎеһӢе‘ўпјҒ
- гҖҢж–°жөӘ科жҠҖгҖҚж–°жЁЎеһӢжҸӯзӨәең°зЈҒеңәеҸҳеҢ–йҖҹзҺҮжҜ”йў„и®Ўзҡ„еҝ«10еҖҚж–°жөӘ科жҠҖ2020-07-15 09:14:370йҳ…
- еҸҰиҫҹи№Ҡеҫ„|й…ҚеҒ¶жӣҝиә«гҖҒеҒҮдәәжЁЎеһӢ з–«жғ…дёӢпјҢеҘҪиҺұеқһеҸҰиҫҹи№Ҡеҫ„жӢҚеҗ»жҲҸ
- еү§з»„|й…ҚеҒ¶жӣҝиә«гҖҒеҒҮдәәжЁЎеһӢ з–«жғ…дёӢпјҢеҘҪиҺұеқһеҸҰиҫҹи№Ҡеҫ„жӢҚеҗ»жҲҸ