「linkedin」百万年薪架构师告诉你:什么kafka? 为什么选择kafka?
文章图片
1. 什么是kafka?Kafka是由LinkedIn开发的一个分布式的消息系统 , 使用Scala编写 , 它以可水平扩展和高吞吐率而被广泛使用 。 目前越来越多的开源分布式处理系统如Storm , Spark , Flink都支持与Kafka集成 。 现在我们的数据实时处理平台也使用到了kafka 。 现在它已被多家不同类型的公司作为多种类型的数据管道和消息系统使用 。
2. 为什么使用消息系统?上面我们提到kafka是一个分布式的消息系统 。 那为什么要在我们的数据处理平台中使用这样的一个消息系统呢?消息系统能给我们带来什么样的好处呢?
(1) 解耦
在项目启动之初来预测将来项目会碰到什么需求 , 是极其困难的 。 消息系统在处理过程中间插入了一个隐含的、基于数据的接口层 , 两边的处理过程都要实现这一接口 。 这允许你独立的扩展或修改两边的处理过程 , 只要确保它们遵守同样的接口约束 。
(2) 冗余
有些情况下 , 处理数据的过程会失败 。 除非数据被持久化 , 否则将造成丢失 。 消息队列把数据进行持久化直到它们已经被完全处理 , 通过这一方式规避了数据丢失风险 。 许多消息队列所采用的\"插入-获取-删除\"范式中 , 在把一个消息从队列中删除之前 , 需要你的处理系统明确的指出该消息已经被处理完毕 , 从而确保你的数据被安全的保存直到你使用完毕 。
(3) 扩展性
因为消息队列解耦了你的处理过程 , 所以增大消息入队和处理的频率是很容易的 , 只要另外增加处理过程即可 。 不需要改变代码、不需要调节参数 。 扩展就像调大电力按钮一样简单 。
(4) 灵活性 & 峰值处理能力
【「linkedin」百万年薪架构师告诉你:什么kafka? 为什么选择kafka?】在访问量剧增的情况下 , 应用仍然需要继续发挥作用 , 但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费 。 使用消息队列能够使关键组件顶住突发的访问压力 , 而不会因为突发的超负荷的请求而完全崩溃 。
(5) 顺序保证
在大多使用场景下 , 数据处理的顺序都很重要 。 大部分消息队列本来就是排序的 , 并且能保证数据会按照特定的顺序来处理 。 Kafka保证一个Partition内的消息的有序性 。
(6) 缓冲
在任何重要的系统中 , 都会有需要不同的处理时间的元素 。 例如 , 加载一张图片比应用过滤器花费更少的时间 。 消息队列通过一个缓冲层来帮助任务最高效率的执行———写入队列的处理会尽可能的快速 。 该缓冲有助于控制和优化数据流经过系统的速度 。
3. 为什么是kafka?上面我们知道我们有必要在数据处理系统中使用一个消息系统 , 但是我们为什么一定要选kafka呢?现在的消息系统可不只有kafka , 俗话说得好 , 货比三家 , 我们看一下kafka与其他消息系统的区别 。
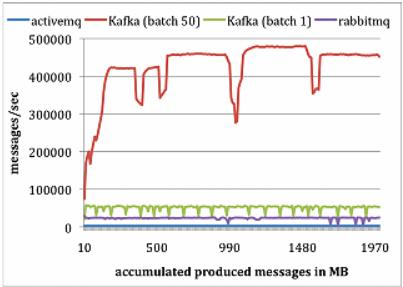
LinkedIn团队做了个实验研究 , 对比Kafka与Apache ActiveMQ V5.4和RabbitMQ V2.4的性能 。 LinkedIn在两台Linux机器上运行他们的实验 , 每台机器的配置为8核2GHz、16GB内存 , 6个磁盘使用RAID10 。 两台机器通过1GB网络连接 。 一台机器作为代理 , 另一台作为生产者或者消费者 。
3.1 生产者测试
对每个系统 , 运行一个生产者 , 总共发布1000万条消息 , 每条消息200字节 。 Kafka生产者以1和50批量方式发送消息 。 ActiveMQ和RabbitMQ似乎没有简单的办法来批量发送消息 , LinkedIn假定它的批量值为1 。 结果如下图所示:
Kafka性能要好很多的主要原因包括:
(1) Kafka不等待代理的确认 , 以代理能处理的最快速度发送消息 。
(2)Kafka有更高效的存储格式 。 平均而言 , Kafka每条消息有9字节的开销 , 而ActiveMQ有144字节 。 其原因是JMS所需的沉重消息头 , 以及维护各种索引结构的开销 。 LinkedIn注意到ActiveMQ一个最忙的线程大部分时间都在存取B-Tree以维护消息元数据和状态 。
推荐阅读














- 大众网@陪伴百万女性终身学习,简知书院:打造专业的女性成长平台
- 金牌娱乐▲销售额破亿!罗永浩的带货首秀其实差强人意,吸粉上百万
- 天不生我泽泽▲科学家预言:未来还有可能再次重演,两亿年前持续百万年的大雨
- 「产业气象站」又拒绝马云的人,如今过的怎么样?,曾拒绝王健林800万年薪
- 极速聊科技:34岁时年薪千万,现在她做了滴滴的总裁,她18岁考入北大
- 「毒眸」“人均网红”的时代,百万大号是如何运作的?,原创
- 蓝媒汇:小米:手握660亿现金113亿房产,人均年薪46万
- 黑科技篮子▲可年薪才20来万,我是他们的3倍,腾讯员工:都羡慕体制内
- 看剧场的桃花可■就连米粉也表示:早该整了,小米再次被“约谈”!涉及上百万用户
- 「太平洋电脑网」罗永浩直播带货第一件商品公布:几百万人看老罗卖笔