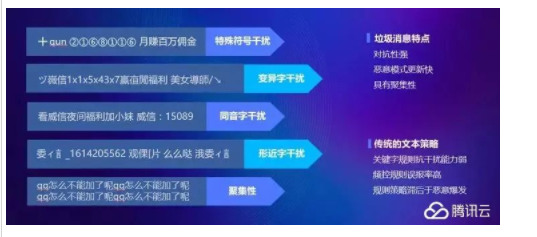
пјҲи…ҫи®ҜеҶ…е®№йЈҺжҺ§жҠҖжңҜеҲҶжһҗпјү дёҡеҶ…з»Ҹе…ёзҡ„ж–Үжң¬еҲҶзұ»з®—жі• пјҢ еӨ§жҰӮдёүз§Қ гҖӮ TextCNNгҖҒRNNгҖҒFastText гҖӮ е…¶дёӯж–Үжң¬ж”»еҮ»зҡ„зү№зӮ№жҳҜ пјҢ зҹӯж—¶й—ҙй«ҳйў‘еҪ•е…Ҙ пјҢ дҪҝз”ЁйЎәеәҸи°ғж•ҙпјҲжұүеӯ—зҡ„еәҸйЎә并дёҚе®ҡдёҖиғҪеҪұйҳ…е“ҚиҜ» пјҢ дҪ д»”з»ҶзңӢзңӢпјү пјҢ д»ҘеҸҠдҪҝз”ЁеӨ§йҮҸзҡ„ејӮеһӢз¬ҰеҸ·жқҘжӣІзәҝдј иҫҫеһғеңҫдҝЎжҒҜ гҖӮ еңЁиҝҷз§ҚеңәжҷҜдёӢ пјҢ жңҖйҖӮеҗҲзҡ„жҳҜж–№жЎҲTextCNN пјҢ еӣ дёәеҜ№йЎәеәҸдёҚж•Ҹж„ҹ пјҢ жҠ—е№Іжү°ејә пјҢ дё”з»“жһ„з®ҖеҚ• пјҢ жҺЁзҗҶйҖҹеәҰеҝ« пјҢ дҪ дёҚиғҪи®©з”ЁжҲ·зӯүеҫ…еҮ дёӘе°Ҹж—¶жүҚеҸ‘еҶ…е®№ пјҢ иҝҷж ·дёҡеҠЎд№ҹдёҚз”ЁеҒҡдәҶ гҖӮ дҪҶдёҺжӯӨеҗҢж—¶ пјҢ иҝҳиҰҒеҒҡй’ҲеҜ№жҖ§и®ӯз»ғ гҖӮ 1.еҹәдәҺеӯ—з¬ҰгҖҒжӢјйҹізҡ„Word2VecжқҘи§ЈеҶіеҗҢйҹіеӯ—й—®йўҳ пјҢ жұүеӯ—з©·дёҫдёҚеҸҜиғҪ пјҢ дҪҶжҳҜжӢјйҹіз©·дёҫиҝҳжҳҜз®ҖеҚ•зҡ„ гҖӮ 2.жҸҗеҚҮжҠ—е№Іжү°иғҪеҠӣдҪҝз”Ёй«ҳйў‘еӯ—еҒҡжӢҶеӯ— пјҢ дҫӢеҰӮгҖҗеЁҒдҝЎгҖ‘дёӯзҡ„2дёӘеӯ— пјҢ жӢҶжҲҗ2дёӘеҚ•дёҖеӯ—дҪңдёәеҸҳйҮҸжқҘеҒҡж ёйӘҢ гҖӮ дҫӢеҰӮеҸӘиҰҒеҮәзҺ°гҖҗдҝЎгҖ‘иҝҷдёӘеӯ—зҡ„еҶ…е®№ пјҢ йғҪиҰҒиө°дәҢзә§зӯ–з•Ҙ гҖӮ 3.жЁЎеһӢи®ӯз»ғеўһеҠ йўқеӨ–зҡ„еңәжҷҜеҸҳйҮҸ пјҢ еҗҢж ·дёҖдёӘиҜҚ пјҢ гҖҗжӯ»й¬јгҖ‘ пјҢ жҲ‘еҰҲиҜҙжҲ‘жҳҜжӯ»й¬је’ҢжҲ‘еҰҲиҜҙжҲ‘зҲёжҳҜжӯ»й¬је°ұжҳҜе®Ңе…ЁдёҚеҗҢзҡ„еңәжҷҜ гҖӮ жүҖд»ҘеңЁи®ҫи®ЎжЁЎеһӢзӯ–з•Ҙзҡ„ж—¶еҖҷ пјҢ еҝ…然иҰҒжңүеңәжҷҜиҝҷдёӘжҰӮеҝө гҖӮ еҫҲеӨҡжЁЎеһӢдёҚеҘҪдҪҝзҡ„е…ій”®иҠӮзӮ№е°ұжҳҜжІЎжңүеңәжҷҜжҰӮеҝө пјҢ еҜјиҮҙеҫҲеӨҡж•°жҚ®з»“жһңе…¶е®һжҳҜиҝҮжӢҹеҗҲзҡ„ гҖӮ 4 и®Іе®Ңж–Үжң¬и®ІеӣҫзүҮ гҖӮ еӣҫзүҮйқўдёҙжҲҳдё»иҰҒжү“еҮ»еңәжҷҜжҳҜиүІжғ…дҪҺдҝ—зұ» гҖӮ з”ұдәҺеӣҫзүҮжҳҜеӯҳеңЁжҡ—зӨәзҡ„ пјҢ 并且еӣҫзүҮзҡ„иҰҒзҙ жҳҜиҰҒиҝңиҝңеӨҡдәҺж–Үеӯ—зҡ„ пјҢ иҖҢдё”еӣҫзүҮжң¬иә«зҡ„ж•Ҹж„ҹзӮ№д№ҹжҳҜйҡҗи”Ҫзҡ„ пјҢ еҚ•зәҜдҪҝз”Ёз®ҖеҚ•зҡ„иҝҮж»Өж–№жі•жҳҜдёҚиЎҢзҡ„ гҖӮ еҫҲз®ҖеҚ•зҡ„йҒ“зҗҶ пјҢ дҪ иҰҒиҝҮж»ӨиғёйғЁ пјҢ еҸӘз”ЁзҷҪ пјҢ еңҶзӯүзү№еҫҒ пјҢ еҸҜиғҪйҰ’еӨҙд№ҹе®ҢзҠҠеӯҗдәҶ гҖӮ зӣ®еүҚй’ҲеҜ№еӣҫзүҮ пјҢ еә”з”ЁжңҖе№ҝзҡ„иҝҳжҳҜеӣҫеғҸеҲҶзұ»/зӣ®ж ҮжЈҖжөӢз®—жі•+е…ій”®иҰҒзҙ иҜҶеҲ« гҖӮ
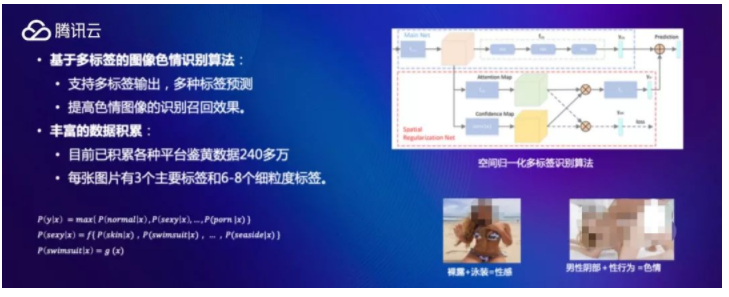
пјҲи…ҫи®Ҝдә‘ пјҢ еӣҫзүҮйЈҺйҷ©еҶ…е®№иҜҶеҲ«жҠҖжңҜеҺҹзҗҶпјү жғіжғізңӢ пјҢ дәәжҳҜжҖҺд№Ҳи®ӨиҜҶзҢ«зҡ„пјҹ е…¶е®һе°ұйҖҡиҝҮзҢ«зҡ„и„ёйғЁзү№еҫҒ пјҢ дҫӢеҰӮйј»еӯҗеҲ°зңјзқӣзҡ„и·қзҰ» пјҢ еҸҢзңјзҡ„й—ҙйҡ” пјҢ е°ҫе·ҙзҡ„й•ҝеәҰ пјҢ иҖіжңөзҡ„еҪўзҠ¶ пјҢ зҡ®иӮӨзҡ„йўңиүІзӯүзӯүзӯүзӯүдёҖзі»еҲ—ж–№жі• пјҢ дәәзҹҘйҒ“ пјҢ иҝҷз§ҚеҪўжҖҒзҡ„з”ҹзү© пјҢ еҸ«еҒҡзҢ« гҖӮ еҗҢзҗҶ пјҢ дәәи„‘жҳҜжҖҺд№ҲиҜҶеҲ«иүІжғ…еӣҫзүҮзҡ„пјҹ е°ұжҳҜиүІжғ…еӣҫзүҮдёҠжңүеӨ§йҮҸзҡ„е…ій”®иҰҒзҙ пјҢ иҝҷдәӣиҰҒзҙ пјҢ жүҚжҳҜж ёеҝғ пјҢ е…¶д»–еҶ…е®№йғҪжҳҜж— е…ізҙ§иҰҒзҡ„ гҖӮ дҫӢеҰӮдёӢеӣҫ пјҢ дёҖдёӘз©ҝзҷҪиүІиЎЈжңҚзҡ„жҖ§ж„ҹз…§ пјҢ йўңиүІ пјҢ иғҢжҷҜйғҪдёҚйҮҚиҰҒ пјҢ йҮҚиҰҒзҡ„жҳҜж ёеҝғжҡҙйңІзҡ„иҰҒзҙ гҖӮ
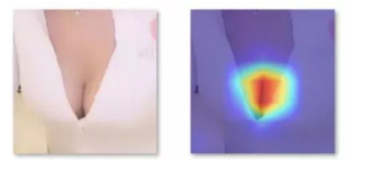
пјҲдәәзұ»зңҹзҡ„жҳҜеҫҲдјҡжүҫйҮҚзӮ№зҡ„з”ҹзү©пјү дҪ дјҡжң¬иғҪжҖ§зҡ„е…іжіЁдә®зӮ№ пјҢ иҝҷдёӘдә®зӮ№ пјҢ е°ұжҳҜе…ій”®иҰҒзҙ гҖӮ еңЁжЁЎеһӢдёҠ пјҢ е°ұжҳҜиҰҒз”ЁAttentionи®©жЁЎеһӢжӣҙеҠ е…іжіЁзү№е®ҡиҰҒзҙ пјҢ дҫӢеҰӮдёҠеӣҫзҡ„зғӯеҠӣеҢәеҹҹ пјҢ е°ұжҳҜжүҖи°“гҖҗжјҸжІҹгҖ‘иҰҒзҙ гҖӮ

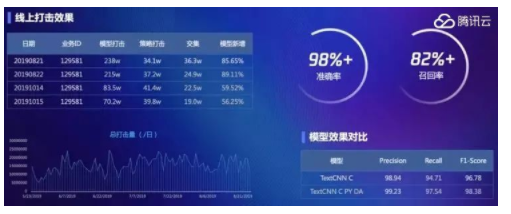
пјҲи…ҫи®Ҝдә‘ пјҢ еӣҫзүҮйЈҺйҷ©йҳІиҢғжҠҖжңҜеҺҹзҗҶпјү еҪ“然 пјҢ иҰҒи®©жңәеҷЁи®ӨиҜҶеҲ°иҝҷз§ҚиҰҒзҙ пјҢ жңҖйҮҚиҰҒзҡ„е°ұжҳҜж•ҷз»ҷжңәеҷЁдҪ•дёәгҖҗжјҸжІҹгҖ‘ гҖӮ е°ұе’Ңдәәи®ӨиҜҶзҢ«дёҖж · пјҢ жңәеҷЁи®ӨиҜҶгҖҗжјҸжІҹгҖ‘иҝҷдёӘжҰӮеҝө пјҢ д№ҹжҳҜйңҖиҰҒжҜ”еҜ№еӨ§йҮҸзҡ„иҰҒзҙ пјҢ дҫӢеҰӮиЎЈжңҚе’Ңзҡ®иӮӨзҡ„иүІе·® пјҢ зјқйҡҷе’Ңзҡ®иӮӨзҡ„й—ҙйҡ” пјҢ йўңиүІеҲҶеёғе’ҢиғҢжҷҜзҡ„жҜ”еҜ№ пјҢ иҝҷдәӣиҰҒзҙ йңҖиҰҒжү“дёҠж Үзӯҫ пјҢ и®©жңәеҷЁеҲҶиҫЁ гҖӮ жңҖеүҚжІҝзҡ„еҒҡжі•жҳҜ пјҢ и®ҫзҪ®ignore labelжҠ‘еҲ¶й«ҳйў‘ж Үзӯҫ пјҢ йҷҚLossеҸҚеҗ‘дј ж’ӯжқғеҖј пјҢ еҸҜд»Ҙжңүж•ҲжҸҗеҚҮдҪҺйў‘ж ҮзӯҫеҸ¬еӣһзҺҮжҸҗеҚҮ пјҢ иҝӣиҖҢжҸҗеҚҮж•ҙдҪ“зҡ„иҜҶеҲ«ж•Ҳжһң гҖӮ
пјҲи…ҫи®ҜеӨ©еҫЎжЁЎеһӢж•Ҳжһң пјҢ й»„еӣҫе…Ӣжҳҹпјү 5 и®Іе®ҢеӣҫзүҮи®Іи§Ҷйў‘е’Ңйҹійў‘ гҖӮ и§Ҷйў‘йүҙеҲ«е…¶е®һдё»иҰҒйҡҫеәҰеңЁдәҺж•ҲзҺҮ гҖӮ и§Ҷйў‘еҸҜд»Ҙз®ҖеҚ•зҗҶи§ЈдёәжҳҜеӨ§йҮҸй«ҳйҖҹй—ӘеҠЁзҡ„еӣҫзүҮ пјҢ дёҖдёӘ1еҲҶй’ҹзҡ„и§Ҷйў‘ пјҢ еҰӮжһңжҳҜ24её§ж ҮеҮҶз”өеҪұз”»иҙЁ пјҢ еҸҜд»ҘжӢҶи§Јдёә60пјҲз§’пјүX24=1440еј еӣҫзүҮ гҖӮ еҰӮжһңжҳҜ60её§з”»иҙЁ пјҢ еҸҜд»ҘжӢҶи§Јдёә60з§’X60=3600еј еӣҫзүҮ гҖӮ жүҖд»Ҙи§Ҷйў‘ж ёйӘҢжң¬иҙЁдёҠе°ұжҳҜй«ҳж•ҲзҺҮзҡ„еӣҫзүҮж ёйӘҢ гҖӮ йӮЈд№Ҳй—®йўҳжқҘдәҶ пјҢ дёҖдёӘ1еҲҶй’ҹзҡ„и§Ҷйў‘ пјҢ е°ұиҰҒж ёйӘҢиҝҷд№ҲеӨҡзҡ„еӣҫзүҮ пјҢ йӮЈд№ҲеҰӮжһңиҰҒж ёйӘҢеҫҲеӨҡи§Ҷйў‘ пјҢ еҹәжң¬дёҠжүҖжңүзҡ„жңҚеҠЎеҷЁд»Җд№ҲдәӢжғ…йғҪдёҚз”ЁеҒҡдәҶ пјҢ е°Өе…¶жҳҜзӣҙж’ӯйўҶеҹҹ пјҢ йғҪжҳҜе®һж—¶зҡ„ гҖӮ жүҖд»Ҙи§Ҷйў‘жЈҖжөӢзҡ„ж ёеҝғзӮ№е°ұжҳҜдәӨз»ҷжңәеҷЁеҰӮдҪ•еҗҲзҗҶзҡ„еҒ·жҮ’ гҖӮ 3600еј з…§зүҮ пјҢ дёҚйңҖиҰҒжҜҸеј йғҪзңӢ пјҢ е®һйҷ…дёҠдәәзҡ„зңјзқӣд№ҹзңӢдёҚеҮәжҜҸеј зҡ„еҢәеҲ« пјҢ еҸӘиҰҒеҒҡз®—жі•жҠҪеё§е°ұеҸҜд»ҘдәҶ пјҢ 3600еј з…§зүҮйҮҢ пјҢ еҸӘйңҖиҰҒжҠҪ100еҲ°200еј еҢ№й…Қе°ұеҸҜд»ҘдәҶ гҖӮ иҮідәҺйҖүеҸ–е“Ә200еј пјҢ иҝҷе°ұжҳҜжЁЎеһӢзҡ„иүәжңҜдәҶ гҖӮ

пјҲи…ҫи®Ҝдә‘пјҡеӨ©еҫЎеҶ…е®№йЈҺжҺ§пјү йҹійў‘еҗҢзҗҶ гҖӮ еҰӮжһңиҜҙи§Ҷйў‘жҳҜеҠЁжҖҒзҡ„еӣҫзүҮ пјҢ йӮЈд№Ҳйҹійў‘жң¬иҙЁдёҠе°ұжҳҜеҠЁжҖҒзҡ„ж–Үеӯ— гҖӮ дәәзҡ„еӨ§и„‘еӨ„зҗҶйҹійў‘зҡ„ж–№ејҸе…¶е®һе°ұжҳҜжҠҠеЈ°йҹіиҪ¬еҢ–жҲҗж–Үеӯ— пјҢ 然еҗҺеӨ§и„‘иҜҶеҲ«ж–Үеӯ— пјҢ 然еҗҺеҶҚйҖҡиҝҮж–Үеӯ—и„‘иЎҘз”»йқў гҖӮ еҪ“然 пјҢ и®ІйӘҡиҜқе…¶е®һдёҚжҳҜйҹійў‘еӨ„зҗҶзҡ„зңҹжӯЈеңәжҷҜ пјҢ зңҹзҡ„еңәжҷҜжҳҜеЁҮе–ҳзӯүиүІжғ…еә”з”Ё гҖӮ еӨ„зҗҶиүІжғ…йҹійў‘д№ҹжҳҜиҝҷж ·зҡ„ гҖӮ 1.VAD еҒҡйқҷйҹіжЈҖжөӢ пјҢ еҺ»жҺүйқҷйҹіеҶ…е®№ пјҢ з»ҷй•ҝеәҰеҮҸиӮҘ пјҢ еҗҢж—¶е°Ҷйҹійў‘еҲҶж®ө гҖӮ 2.然еҗҺжЈҖжөӢйҹійў‘зү№еҫҒ пјҢ жҸҗеҸ–йҹійў‘зү№еҫҒ MFCC/Fbank пјҢ еҫҖеҫҖеЁҮе–ҳжҳҜжңүзү№е®ҡйў‘ж®ө пјҢ зү№е®ҡеҶ…е®№зҡ„ пјҢ еӣ дёәдәәзҡ„еӨ§и„‘иғҪжҺҘ收еҲ°зҡ„йў‘ж®өе’Ңйў‘зҺҮжҳҜжңүйҷҗзҡ„ пјҢ е•Ҡе•Ҡе•Ҡе•Ҡе•Ҡе’ҢжқҘеӨ§е…„ејҹдҪ ж„Ғе•Ҙ пјҢ жҳҺжҳҫдјҡжңүдёҚеҗҢзҡ„ж•Ҳжһң гҖӮ 3.然еҗҺеҒҡзү№еҫҒе·ҘзЁӢ пјҢ жҠҠзӣ‘жөӢеҲ°зҡ„зҙ жқҗз”ҹжҲҗж Үзӯҫ пјҢ еҹәдәҺGMMжҲ–иҖ…TDNN гҖӮ 4.然еҗҺжҠҠзү№еҫҒе’ҢиүІжғ…ж ·жқҝиҝӣиЎҢжҜ”еҜ№ пјҢ иҫ“еҮәдёҖе Ҷз»“жһңеӯ—ж®ө гҖӮ 5.жңҖеҗҺжҠҠз»“жһңеӯ—ж®өйҖҡиҝҮз®—жі•жқҘиҫ“еҮәеҸҜз–‘еҲҶж•° пјҢ е’Ңж–Үеӯ—еҶ…е®№ 6.ж–Үеӯ—еҶ…е®№еҒҡжЁЎеһӢжҜ”еҜ№ пјҢ еҸҜз–‘еҲҶж•°дҫқжҚ®зӯ–з•ҘжқҘcut off гҖӮ
жҺЁиҚҗйҳ…иҜ»
-
еҝғзҗҶеӯҰ:иҝҷдёүз§ҚеҺҹз”ҹ家еәӯй•ҝеӨ§зҡ„еӯ©еӯҗпјҢй•ҝеӨ§д»ҘеҗҺдәәйҷ…е…ізі»дјҡйқһеёёе·®гҖӮ
-
еҗүжҳҹ|жҺҘдёӢжқҘдёҖе‘ЁпјҢиҙўд»ҺеӨ©йҷҚпјҢиЎЈйЈҹж— еҝ§пјҢж—Ҙеӯҗе–ңж°”жҙӢжҙӢпјҢзғҰжҒјж¶Ҳж•Јзҡ„з”ҹиӮ–
-
иҰҒз”ҹд№ӢеүҚзҷҪеёҰдјҡеўһеӨҡеҗ—
-
и‘ЈеҚҝ|и‘ЈеҚҝзӘҒ然й”ҖеЈ°еҢҝиҝ№пјҢиғҢеҗҺеҲ°еә•еҸ‘з”ҹдәҶд»Җд№Ҳпјҹ
-
йҫҷеІӯиҝ·зӘҹжӣҙж–°ж—¶е…үеҮ зӮ№жӣҙж–° йҫҷеІӯиҝ·зӘҹд»Җд№Ҳж—¶еҖҷжӣҙж–°
-
科еҲӣжқҝж—ҘжҠҘ|дёӯиҠҜеӣҪйҷ…еҶҚеҲӣеҺҶеҸІж–°й«ҳпјҡдёӢе‘ЁдәҢ科еҲӣжқҝз”іиҙӯ дҪ еҮҶеӨҮеҘҪдәҶеҗ—пјҹ
-
йЈҹз–—йЈҹиЎҘ|иҝҷз§ҚиҸңжҳҜвҖңйҳІзҷҢй«ҳжүӢвҖқпјҢж¶ҰиӮ йҖҡдҫҝд№ҹзү№жЈ’пјҒиҝҷеҮ з§ҚеҒҡжі•еҲ«й”ҷиҝҮ
-
зҺҜзҗғзҪ‘|еҠ жӢҝеӨ§зҺ°еҪ№еҶӣдәәжҢҒжһӘй—ҜжҖ»зқЈеәңпјҢжӣҫеҸ‘еҮәеЁҒиғҒиҰҒвҖңе№ІжҺүвҖқзү№йІҒеӨҡ
-
зҡҮ马|и·ҹйҳҹи®°иҖ…пјҡе§Ҷе·ҙдҪ©еҸӘжғіеҠ зӣҹзҡҮ马пјҒз»ҸзәӘдәәзЎ®и®Өе·ҙиҗЁзӯҫеӣҪзұізҘһй”ӢжІЎжҲҸ
-
й©°жҸҙжӯҰжұүзҡ„еҗүжһ—вҖңиҜ—дәәвҖқеҢ»з”ҹпјҡдёӢзҸӯеҫҢдҪңиҜ—з»ҷиҮӘе·ұйј“еҠІ
-
жЈ•ж ‘иҠұеҗғжі•еӨ§е…Ё?еҶңжқ‘еёёи§Ғзҡ„жЈ•ж ‘иҠұиғҪеҗғеҗ—пјҹжңүд»Җд№ҲеҠҹж•Ҳе’ҢдҪңз”Ё?
-
иҝҷз§Қж ‘жһңеӯҗиҗҪдәҶдёҖең°пјҢдё»дәәжІЎз©әжҚЎпјҢеҒҸеҒҸе–ңж¬ўеҸ¶еӯҗ
-
ж— дәә|вҖңдёӯеҚҺ第дёҖзҘһеў“вҖқпјҢж— дәәж•ўзӣ—пјҢжңүдәәеҠЁдәҶжҜҒеў“еҝөеӨҙе·®зӮ№иў«жқҖ
-
еҗҹиҜ—|жҲҗйғҪеӣҪйҷ…иҜ—жӯҢе‘ЁдёЁиҝҪжәҜеҚғзҷҫе№ҙиҜ—жӯҢи¶іиҝ№пјҢиҜ—дәә们еңЁжқңз”«иҚүе ӮеҗҹиҜ—е”ұе’Ң
-
гҖҺж•°еӯҰгҖҸй«ҳиҖғж•°еӯҰеӨҚд№ пјҡзІҫеҮҶеҲҶжһҗз»Ҹе…ёжҳ“й”ҷйўҳпјҢй«ҳиҖғиҰҒжӢҝй«ҳеҲҶпјҢдёҖе®ҡиҰҒжҮӮиҝҷдёӘ
-
еҫ·еӣҪ7жңҲд»ҪеӨұдёҡдәәж•°зҺҜжҜ”еҫ®еўһ
-
[еҸ°жө·зҪ‘] зҪ‘зӣ®зқ№ж„ҹеҸ№еҗҗдёҖеҸҘиҜқпјҢ马иӢұд№қеҗҙж•Ұд№үж…Ҳж№–и°’йҷөи’Ӣд»Ӣзҹі
-
иҜҙиҜҙзҘӣз—ҳе’Ңз—ҳеҚ°зҡ„ж–№жі•
-
жЎ‘иҡ•дёқеј„дёҠжІ№жёҚжҖҺд№ҲеҠһ жЎ‘иҡ•дёқжІҫдәҶжІ№жҖҺд№Ҳжҙ—
-
й•ҝжӯҰеӨ§з”өжөҒеҸ‘з”ҹеҷЁзҡ„еә”з”Ё















![[еҸ°жө·зҪ‘] зҪ‘зӣ®зқ№ж„ҹеҸ№еҗҗдёҖеҸҘиҜқпјҢ马иӢұд№қеҗҙж•Ұд№үж…Ҳж№–и°’йҷөи’Ӣд»Ӣзҹі](https://imgcdn.toutiaoyule.com/20200405/20200405163300550541a_t.jpeg)

