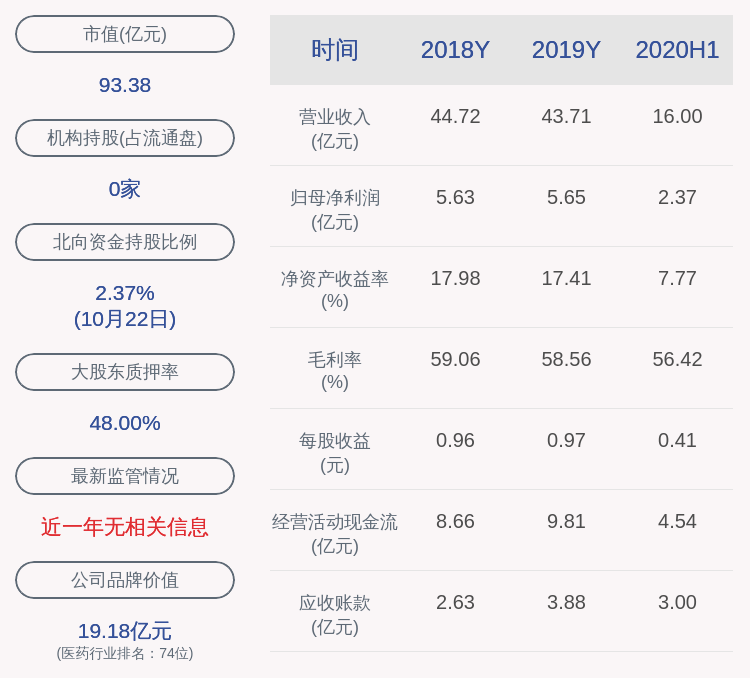
жҲ‘们дәҶи§ЈеҲ°еңЁдё»д»Һеә“йӣҶзҫӨжЁЎејҸдёӢпјҢеҰӮжһңд»Һеә“еҸ‘з”ҹж•…йҡң пјҢ е®ўжҲ·з«ҜеҸҜд»Ҙ继з»ӯеҗ‘дё»еә“жҲ–е…¶д»–д»Һеә“еҸ‘йҖҒиҜ·жұӮпјҢжү§иЎҢзӣёеә”зҡ„ж“ҚдҪң гҖӮ然иҖҢпјҢеҪ“дё»еә“еҸ‘з”ҹж•…йҡңж—¶пјҢдјҡзӣҙжҺҘеҪұе“Қд»Һеә“зҡ„еҗҢжӯҘпјҢеӣ дёәжӯӨж—¶д»Һеә“еӨұеҺ»дәҶеҸҜз”Ёзҡ„дё»еә“иҝӣиЎҢж•°жҚ®еӨҚеҲ¶ гҖӮ
иҖҢдё”пјҢеҰӮжһңе®ўжҲ·з«ҜеҸ‘йҖҒзҡ„йғҪжҳҜиҜ»ж“ҚдҪңиҜ·жұӮ пјҢ йӮЈиҝҳеҸҜд»Ҙз”ұд»Һеә“继з»ӯжҸҗдҫӣжңҚеҠЎ пјҢ иҝҷеңЁзәҜиҜ»зҡ„дёҡеҠЎеңәжҷҜдёӢиҝҳиғҪиў«жҺҘеҸ— гҖӮдҪҶжҳҜпјҢдёҖж—ҰжңүеҶҷж“ҚдҪңиҜ·жұӮдәҶпјҢжҢүз…§дё»д»Һеә“жЁЎејҸдёӢзҡ„иҜ»еҶҷеҲҶзҰ»иҰҒжұӮпјҢйңҖиҰҒз”ұдё»еә“жқҘе®ҢжҲҗеҶҷж“ҚдҪң гҖӮжӯӨж—¶пјҢд№ҹжІЎжңүе®һдҫӢеҸҜд»ҘжқҘжңҚеҠЎе®ўжҲ·з«Ҝзҡ„еҶҷж“ҚдҪңиҜ·жұӮдәҶ пјҢ еҰӮдёӢеӣҫжүҖзӨәпјҡ

ж–Үз« жҸ’еӣҫ
еӣҫзүҮ
дё»еә“ж•…йҡңеҗҺпјҢеҜјиҮҙд»Һеә“ж— жі•жҸҗдҫӣеҶҷж“ҚдҪңзҡ„жңҚеҠЎпјҢиҝҷз§Қжғ…еҶөжҳҜдёҚеҸҜжҺҘеҸ—зҡ„ гҖӮеӣ жӯӨпјҢеңЁдё»еә“еҸ‘з”ҹж•…йҡңж—¶пјҢжҲ‘们йңҖиҰҒеҗҜеҠЁдёҖдёӘж–°зҡ„дё»еә“пјҢйҖҡеёёжҳҜе°ҶдёҖдёӘд»Һеә“еҚҮзә§дёәдё»еә“并е°Ҷе…¶дҪңдёәж–°зҡ„дё»еә“ гҖӮ然иҖҢ пјҢ иҝҷж¶үеҸҠеҲ°и§ЈеҶідёүдёӘж ёеҝғй—®йўҳпјҡ
- еҰӮдҪ•зЎ®е®ҡдё»еә“е·Із»Ҹе®•жңәдәҶпјҹ
- д»Һдј—еӨҡд»Һеә“дёӯйҖүжӢ©е“ӘдёҖдёӘдҪңдёәж–°зҡ„дё»еә“пјҹ
- еҰӮдҪ•йҖҡзҹҘд»Һеә“е’Ңе®ўжҲ·з«Ҝе…ідәҺж–°дё»еә“зҡ„еҸҳеҢ–пјҹ
е“Ёе…өжңәеҲ¶зҡ„еҹәжң¬жөҒзЁӢе“Ёе…өе…¶е®һе°ұжҳҜдёҖдёӘиҝҗиЎҢеңЁзү№ж®ҠжЁЎејҸдёӢзҡ„ Redis иҝӣзЁӢ пјҢ дё»д»Һеә“е®һдҫӢиҝҗиЎҢзҡ„еҗҢж—¶ пјҢ е®ғд№ҹеңЁиҝҗиЎҢ гҖӮе“Ёе…өдё»иҰҒиҙҹиҙЈзҡ„е°ұжҳҜдёүдёӘд»»еҠЎпјҡзӣ‘жҺ§гҖҒйҖүдё»пјҲйҖүжӢ©дё»еә“пјүе’ҢйҖҡзҹҘ гҖӮ
жҲ‘们е…ҲзңӢзӣ‘жҺ§ гҖӮзӣ‘жҺ§жҳҜжҢҮе“Ёе…өиҝӣзЁӢеңЁиҝҗиЎҢж—¶пјҢе‘ЁжңҹжҖ§ең°з»ҷжүҖжңүзҡ„дё»д»Һеә“еҸ‘йҖҒ PING е‘Ҫд»ӨпјҢжЈҖжөӢе®ғ们жҳҜеҗҰд»Қ然еңЁзәҝиҝҗиЎҢ гҖӮеҰӮжһңд»Һеә“жІЎжңүеңЁи§„е®ҡж—¶й—ҙеҶ…е“Қеә”е“Ёе…өзҡ„ PING е‘Ҫд»ӨпјҢе“Ёе…өе°ұдјҡжҠҠе®ғж Үи®°дёә“дёӢзәҝзҠ¶жҖҒ”пјӣеҗҢж ·пјҢеҰӮжһңдё»еә“д№ҹжІЎжңүеңЁи§„е®ҡж—¶й—ҙеҶ…е“Қеә”е“Ёе…өзҡ„ PING е‘Ҫд»ӨпјҢе“Ёе…өе°ұдјҡеҲӨе®ҡдё»еә“дёӢзәҝпјҢ然еҗҺејҖе§ӢиҮӘеҠЁеҲҮжҚўдё»еә“зҡ„жөҒзЁӢ гҖӮ
иҝҷдёӘжөҒзЁӢйҰ–е…ҲжҳҜжү§иЎҢе“Ёе…өзҡ„第дәҢдёӘд»»еҠЎпјҢйҖүдё» гҖӮдё»еә“жҢӮдәҶд»ҘеҗҺпјҢе“Ёе…өе°ұйңҖиҰҒд»ҺеҫҲеӨҡдёӘд»Һеә“йҮҢпјҢжҢүз…§дёҖе®ҡзҡ„规еҲҷйҖүжӢ©дёҖдёӘд»Һеә“е®һдҫӢпјҢжҠҠе®ғдҪңдёәж–°зҡ„дё»еә“ гҖӮиҝҷдёҖжӯҘе®ҢжҲҗеҗҺпјҢзҺ°еңЁзҡ„йӣҶзҫӨйҮҢе°ұжңүдәҶж–°дё»еә“ гҖӮ
然еҗҺпјҢе“Ёе…өдјҡжү§иЎҢжңҖеҗҺдёҖдёӘд»»еҠЎпјҡйҖҡзҹҘ гҖӮеңЁжү§иЎҢйҖҡзҹҘд»»еҠЎж—¶пјҢе“Ёе…өдјҡжҠҠж–°дё»еә“зҡ„иҝһжҺҘдҝЎжҒҜеҸ‘з»ҷе…¶д»–д»Һеә“пјҢи®©е®ғ们жү§иЎҢ replicaof е‘Ҫд»ӨпјҢе’Ңж–°дё»еә“е»әз«ӢиҝһжҺҘпјҢ并иҝӣиЎҢж•°жҚ®еӨҚеҲ¶ гҖӮеҗҢж—¶пјҢе“Ёе…өдјҡжҠҠж–°дё»еә“зҡ„иҝһжҺҘдҝЎжҒҜйҖҡзҹҘз»ҷе®ўжҲ·з«ҜпјҢи®©е®ғ们жҠҠиҜ·жұӮж“ҚдҪңеҸ‘еҲ°ж–°дё»еә“дёҠ гҖӮ
жҲ‘з”»дәҶдёҖеј еӣҫзүҮ пјҢ еұ•зӨәдәҶиҝҷдёүдёӘд»»еҠЎд»ҘеҸҠе®ғ们еҗ„иҮӘзҡ„зӣ®ж Ү гҖӮ

ж–Үз« жҸ’еӣҫ
е“Ёе…өжңәеҲ¶зҡ„дёүйЎ№д»»еҠЎдёҺзӣ®ж Ү
еңЁиҝҷдёүдёӘд»»еҠЎдёӯ пјҢ йҖҡзҹҘд»»еҠЎзӣёеҜ№жқҘиҜҙжҜ”иҫғз®ҖеҚ•пјҢе“Ёе…өеҸӘйңҖиҰҒжҠҠж–°дё»еә“дҝЎжҒҜеҸ‘з»ҷд»Һеә“е’Ңе®ўжҲ·з«ҜпјҢи®©е®ғ们е’Ңж–°дё»еә“е»әз«ӢиҝһжҺҘе°ұиЎҢ пјҢ 并дёҚж¶үеҸҠеҶізӯ–зҡ„йҖ»иҫ‘ гҖӮдҪҶжҳҜ пјҢ еңЁзӣ‘жҺ§е’ҢйҖүдё»иҝҷдёӨдёӘд»»еҠЎдёӯпјҢе“Ёе…өйңҖиҰҒеҒҡеҮәдёӨдёӘеҶізӯ–пјҡ
еңЁзӣ‘жҺ§д»»еҠЎдёӯпјҢе“Ёе…өйңҖиҰҒеҲӨж–ӯдё»еә“жҳҜеҗҰеӨ„дәҺдёӢзәҝзҠ¶жҖҒпјӣ
еңЁйҖүдё»д»»еҠЎдёӯпјҢе“Ёе…өд№ҹиҰҒеҶіе®ҡйҖүжӢ©е“ӘдёӘд»Һеә“е®һдҫӢдҪңдёәдё»еә“ гҖӮ
жҺҘдёӢжқҘпјҢжҲ‘们е°ұе…ҲиҜҙиҜҙеҰӮдҪ•еҲӨж–ӯдё»еә“зҡ„дёӢзәҝзҠ¶жҖҒ гҖӮ
дҪ йҰ–е…ҲиҰҒзҹҘйҒ“зҡ„жҳҜпјҢе“Ёе…өеҜ№дё»еә“зҡ„дёӢзәҝеҲӨж–ӯжңү“дё»и§ӮдёӢзәҝ”е’Ң“е®ўи§ӮдёӢзәҝ”дёӨз§Қ гҖӮйӮЈд№ҲпјҢдёәд»Җд№ҲдјҡеӯҳеңЁдёӨз§ҚеҲӨж–ӯе‘ўпјҹе®ғ们зҡ„еҢәеҲ«е’ҢиҒ”зі»жҳҜд»Җд№Ҳе‘ўпјҹ
дё»и§ӮдёӢзәҝе’Ңе®ўи§ӮдёӢзәҝжҲ‘е…Ҳи§ЈйҮҠдёӢд»Җд№ҲжҳҜ“дё»и§ӮдёӢзәҝ” гҖӮ
е“Ёе…өиҝӣзЁӢдјҡдҪҝз”Ё PING е‘Ҫд»ӨжЈҖжөӢе®ғиҮӘе·ұе’Ңдё»гҖҒд»Һеә“зҡ„зҪ‘з»ңиҝһжҺҘжғ…еҶөпјҢз”ЁжқҘеҲӨж–ӯе®һдҫӢзҡ„зҠ¶жҖҒ гҖӮеҰӮжһңе“Ёе…өеҸ‘зҺ°дё»еә“жҲ–д»Һеә“еҜ№ PING е‘Ҫд»Өзҡ„е“Қеә”и¶…ж—¶дәҶпјҢйӮЈд№ҲпјҢе“Ёе…өе°ұдјҡе…ҲжҠҠе®ғж Үи®°дёә“дё»и§ӮдёӢзәҝ” гҖӮ
еҰӮжһңжЈҖжөӢзҡ„жҳҜд»Һеә“пјҢйӮЈд№ҲпјҢе“Ёе…өз®ҖеҚ•ең°жҠҠе®ғж Үи®°дёә“дё»и§ӮдёӢзәҝ”е°ұиЎҢдәҶ пјҢ еӣ дёәд»Һеә“зҡ„дёӢзәҝеҪұе“ҚдёҖиҲ¬дёҚеӨӘеӨ§пјҢйӣҶзҫӨзҡ„еҜ№еӨ–жңҚеҠЎдёҚдјҡй—ҙж–ӯ гҖӮ
дҪҶжҳҜпјҢеҰӮжһңжЈҖжөӢзҡ„жҳҜдё»еә“пјҢйӮЈд№Ҳ пјҢ е“Ёе…өиҝҳдёҚиғҪз®ҖеҚ•ең°жҠҠе®ғж Үи®°дёә“дё»и§ӮдёӢзәҝ” пјҢ ејҖеҗҜдё»д»ҺеҲҮжҚў гҖӮеӣ дёәеҫҲжңүеҸҜиғҪеӯҳеңЁиҝҷд№ҲдёҖдёӘжғ…еҶөпјҡйӮЈе°ұжҳҜе“Ёе…өиҜҜеҲӨдәҶпјҢе…¶е®һдё»еә“并没жңүж•…йҡң гҖӮеҸҜжҳҜпјҢдёҖж—ҰеҗҜеҠЁдәҶдё»д»ҺеҲҮжҚўпјҢеҗҺз»ӯзҡ„йҖүдё»е’ҢйҖҡзҹҘж“ҚдҪңйғҪдјҡеёҰжқҘйўқеӨ–зҡ„и®Ўз®—е’ҢйҖҡдҝЎејҖй”Җ гҖӮ
дёәдәҶйҒҝе…ҚиҝҷдәӣдёҚеҝ…иҰҒзҡ„ејҖй”ҖпјҢжҲ‘们иҰҒзү№еҲ«жіЁж„ҸиҜҜеҲӨзҡ„жғ…еҶө гҖӮ
йҰ–е…ҲпјҢжҲ‘们иҰҒзҹҘйҒ“е•ҘеҸ«иҜҜеҲӨ гҖӮеҫҲз®ҖеҚ•пјҢе°ұжҳҜдё»еә“е®һйҷ…并没жңүдёӢзәҝпјҢдҪҶжҳҜе“Ёе…өиҜҜд»Ҙдёәе®ғдёӢзәҝдәҶ гҖӮиҜҜеҲӨдёҖиҲ¬дјҡеҸ‘з”ҹеңЁйӣҶзҫӨзҪ‘з»ңеҺӢеҠӣиҫғеӨ§гҖҒзҪ‘з»ңжӢҘеЎһпјҢжҲ–иҖ…жҳҜдё»еә“жң¬иә«еҺӢеҠӣиҫғеӨ§зҡ„жғ…еҶөдёӢ гҖӮ
жҺЁиҚҗйҳ…иҜ»
















- MySQL 5.7еҒңжңҚе°ұдёҠ8.0пјҹиҝҷдәӣж•°жҚ®еә“жӣҝд»Јд№ҹжқ жқ зҡ„
- жҠҠжҸЎж•ҲзҺҮдёҺжңҖдјҳжҖ§пјҡDijkstraз®—жі•зҡ„жҺўзҙў
- GoдёӯдҪҝз”Ёsync.Mapе®һзҺ°зәҝзЁӢе®үе…Ёзҡ„зј“еӯҳ
- RedisдёӯдёҮйҮ‘жІ№зҡ„StringпјҢдёәд»Җд№ҲдёҚеҘҪз”ЁдәҶпјҹ
- C++дёӯзҡ„еӨҡзәҝзЁӢзј–зЁӢпјҡдёҖз§Қй«ҳж•Ҳзҡ„并еҸ‘еӨ„зҗҶж–№ејҸ
- HTTPеҚҸи®®дёӯCookieе’ҢSessionзҡ„еҢәеҲ«жҳҜд»Җд№Ҳпјҹ
- ж— ж•ҢеҲ°еҜӮеҜһпјҒRedisиҝӣеҶӣзЈҒзӣҳеӯҳеӮЁпјҒ
- To B дјҒдёҡзҪ‘з»ңиҗҘй”Җж•Ҳжһңе·®пјҢи°Ғзҡ„вҖңй”…вҖқпјҹ
- е…«ж¬ҫж—ЁеңЁзӘғеҸ–ж•°жҚ®зҡ„еҒҮеҶ’ChatGPTжҒ¶ж„Ҹеә”з”Ё
- еҰӮдҪ•зЎ®е®ҡApache Kafkaзҡ„еӨ§е°Ҹе’Ң规模