在不同的学习率经过200轮训练后成本和准确度的图如下:

文章插图

文章插图
4.2. KL散度
KL散度概率分布与另一个概率分布区别的度量 。KL散度为零表示分布相同 。

文章插图
请注意,发散函数不对称 。即:

文章插图
这就是为什么KL散度不能用作距离度量的原因 。
我将描述使用KL散度作为损失函数而不进行数学计算的基本方法 。在给定一些近似分布Q的情况下,我们希望近似关于输入特征的目标变量的真实概率分布P. 由于KL散度不对称,我们可以通过两种方式实现:

文章插图
第一种方法用于监督学习,第二种方法用于强化学习 。KL散度在功能上类似于多分类交叉熵,KL散度也可以称为P相对于Q的相对熵:
我们在compile()函数中指定'kullback_leibler_divergence'作为损失函数,就像我们之前在处理多分类交叉熵损失时所做的那样 。

文章插图
# 导入包from keras.layers import Densefrom keras.models import Sequentialfrom keras.optimizers import adam# alpha设置为0.001,如adam优化器中的lr参数所示# 创建模型model_alpha1 = Sequential()model_alpha1.add(Dense(50, input_dim=2, activation='relu'))model_alpha1.add(Dense(3, activation='softmax'))# 编译模型opt_alpha1 = adam(lr=0.001)model_alpha1.compile(loss='kullback_leibler_divergence', optimizer=opt_alpha1, metrics=['accuracy'])# 拟合模型# dummy_Y是one-hot形式编码的# history_alpha1用于为绘图的验证和准确性评分history_alpha1 = model_alpha1.fit(dataX, dummy_Y, validation_data=https://www.isolves.com/it/ai/2019-08-29/(dataX, dummy_Y), epochs=200, verbose=0)在不同的学习率经过200轮训练后成本和准确度的图如下:

文章插图

文章插图
与多分类分类相比,KL散度更常用于逼近复杂函数 。我们在使用变分自动编码器(VAE)等深度生成模型时经常使用KL散度 。
推荐阅读













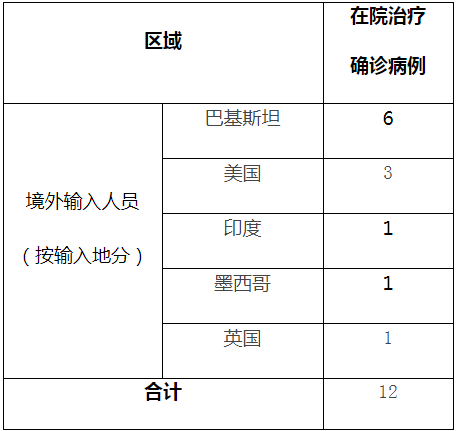

- 官方清粉工具要来?微信新功能曝光:全面学习QQ
- Java小白学习如何打日志
- 高效的动态规划算法
- Dijkstra算法
- 「一图详解」收藏!一份关于小规模纳税人减征增值税的学习笔记
- 收藏这5个学习APP,每天偷偷给自己充电,做更优秀的自己
- 贪心算法
- 算法到底是什么?
- BloomFilter算法知识点
- 机器|什么样的员工,才会更容易被领导提拔和重用