иҜҰи§Је·ҘзЁӢеёҲдёҚеҸҜдёҚдјҡзҡ„LRUзј“еӯҳж·ҳжұ°з®—жі•( дәҢ )
жҲ‘们жҠҠдёҠйқўзҡ„еҶ…е®№ж•ҙзҗҶдёҖдёӢ пјҢ еҸҜд»Ҙеҫ—еҲ°еҮ зӮ№иҰҒжұӮпјҡ
- дҝқиҜҒзј“еӯҳзҡ„иҜ»еҶҷж•ҲзҺҮ пјҢ жҜ”еҰӮиҜ»еҶҷзҡ„еӨҚжқӮеәҰйғҪжҳҜO(1)
- еҪ“дёҖжқЎзј“еӯҳеҪ“дёӯзҡ„ж•°жҚ®иў«иҜ»еҸ– пјҢ е°Ҷе®ғжңҖиҝ‘дҪҝз”Ёзҡ„ж—¶й—ҙжӣҙж–°
- еҪ“жҸ’е…ҘдёҖжқЎж–°ж•°жҚ®зҡ„ж—¶еҖҷ пјҢ еј№еҮәжӣҙж–°ж—¶й—ҙжңҖиҝңзҡ„ж•°жҚ®
еҰӮжһңжҳҜеңЁйқўиҜ•еҪ“дёӯиў«й—®еҲ°жғіеҲ°иҝҷйҮҢзҡ„ж—¶еҖҷ пјҢ еҸҜиғҪеҫҲеӨҡдәәйғҪе·Із»ҸжқҹжүӢж— зӯ–дәҶ гҖӮ дҪҶжҳҜе…ҲеҲ«зқҖжҖҘ пјҢ жҲ‘们еҶ·йқҷдёӢжқҘжғіжғідјҡеҸ‘зҺ°й—®йўҳе…¶е®һ并没жңүйӮЈд№ҲжЁЎзіҠ гҖӮ йҰ–е…ҲHashMapжҳҜдёҖе®ҡиҰҒз”Ёзҡ„ пјҢ еӣ дёәеҸӘжңүHashMapжүҚеҸҜд»ҘеҒҡеҲ°O(1)ж—¶й—ҙеҶ…зҡ„иҜ»еҶҷ пјҢ е…¶д»–зҡ„ж•°жҚ®з»“жһ„еҮ д№ҺйғҪдёҚеҸҜиЎҢ гҖӮ дҪҶжҳҜеҸӘжңүHashMapи§ЈеҶідёҚдәҶжӣҙж–°д»ҘеҸҠж·ҳжұ°зҡ„й—®йўҳ пјҢ еҝ…йЎ»иҰҒй…ҚеҗҲе…¶д»–ж•°жҚ®з»“жһ„иҝӣиЎҢ гҖӮ иҝҷдёӘж•°жҚ®з»“жһ„йңҖиҰҒиғҪеӨҹеҒҡеҲ°еҝ«йҖҹең°жҸ’е…Ҙе’ҢеҲ йҷӨ пјҢ е…¶е®һжҲ‘иҝҷд№ҲдёҖиҜҙе·Із»ҸеҫҲжҳҺжҳҫдәҶ пјҢ еҸӘжңүдёҖдёӘж•°жҚ®з»“жһ„еҸҜд»ҘеҒҡеҲ° пјҢ е°ұжҳҜй“ҫиЎЁ гҖӮ
й“ҫиЎЁжңүдёҖдёӘй—®йўҳжҳҜжҲ‘们жғіиҰҒжҹҘиҜўй“ҫиЎЁеҪ“дёӯзҡ„жҹҗдёҖдёӘиҠӮзӮ№йңҖиҰҒO(n)зҡ„ж—¶й—ҙ пјҢ иҝҷд№ҹжҳҜжҲ‘д»¬ж— жі•жҺҘеҸ—зҡ„ гҖӮ дҪҶиҝҷдёӘй—®йўҳ并йқһж— жі•и§ЈеҶі пјҢ е®һйҷ…дёҠи§ЈеҶід№ҹеҫҲз®ҖеҚ• пјҢ жҲ‘们еҸӘйңҖиҰҒжҠҠй“ҫиЎЁеҪ“дёӯзҡ„иҠӮзӮ№дҪңдёәHashMapдёӯзҡ„valueиҝӣиЎҢеӮЁеӯҳеҚіеҸҜ пјҢ жңҖеҗҺеҫ—еҲ°зҡ„зі»з»ҹжһ¶жһ„еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
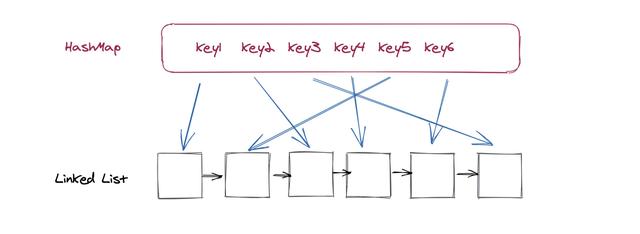
ж–Үз« жҸ’еӣҫеҜ№дәҺзј“еӯҳжқҘиҜҙе…¶е®һеҸӘжңүдёӨз§ҚеҠҹиғҪ пјҢ 第дёҖз§ҚеҠҹиғҪе°ұжҳҜжҹҘжүҫ пјҢ 第дәҢз§ҚжҳҜжӣҙж–° гҖӮ
жҹҘжүҫжҹҘжүҫдјҡеҲҶдёәдёӨз§Қжғ…еҶө пјҢ 第дёҖз§ҚжҳҜжІЎжҹҘеҲ° пјҢ иҝҷз§ҚжІЎд»Җд№ҲеҘҪиҜҙзҡ„ пјҢ зӣҙжҺҘиҝ”еӣһз©әеҚіеҸҜ гҖӮ еҰӮжһңиғҪжҹҘеҲ°иҠӮзӮ№ пјҢ еңЁжҲ‘们иҝ”еӣһз»“жһңзҡ„еҗҢж—¶ пјҢ жҲ‘们йңҖиҰҒе°ҶжҹҘеҲ°зҡ„иҠӮзӮ№еңЁй“ҫиЎЁеҪ“дёӯ移еҠЁдҪҚзҪ® гҖӮ жҲ‘们еҒҮи®ҫи¶Ҡйқ иҝ‘й“ҫиЎЁеӨҙйғЁиЎЁзӨәж•°жҚ®и¶Ҡж—§ пјҢ и¶Ҡйқ иҝ‘й“ҫиЎЁе°ҫйғЁж•°жҚ®и¶Ҡж–° пјҢ йӮЈд№ҲеҪ“жҲ‘们жҹҘжүҫз»“жқҹд№ӢеҗҺ пјҢ жҲ‘们йңҖиҰҒжҠҠиҠӮзӮ№з§»еҠЁеҲ°й“ҫиЎЁзҡ„е°ҫйғЁ гҖӮ
移еҠЁеҸҜд»ҘйҖҡиҝҮдёӨдёӘжӯҘйӘӨжқҘе®ҢжҲҗ пјҢ 第дёҖдёӘжӯҘйӘӨжҳҜеңЁй“ҫиЎЁдёҠеҲ йҷӨиҜҘиҠӮзӮ№ пјҢ 第дәҢдёӘжӯҘйӘӨжҳҜжҸ’е…ҘеҲ°е°ҫйғЁпјҡ
 ж–Үз« жҸ’еӣҫ
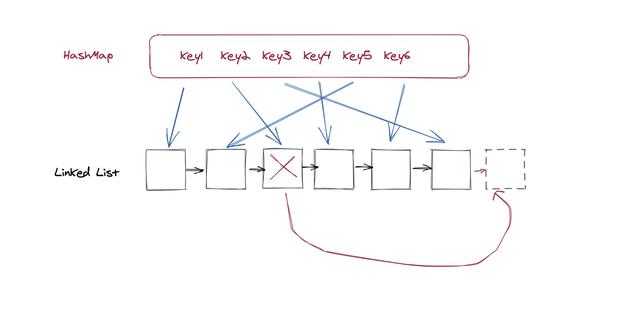
ж–Үз« жҸ’еӣҫжӣҙж–°жӣҙж–°д№ҹеҗҢж ·еҲҶдёәдёӨз§Қжғ…еҶө пјҢ 第дёҖз§Қжғ…еҶөе°ұжҳҜжӣҙж–°зҡ„keyе·Із»ҸеңЁHashMapеҪ“дёӯдәҶ пјҢ йӮЈд№ҲжҲ‘们еҸӘйңҖиҰҒжӣҙж–°е®ғеҜ№еә”зҡ„Value пјҢ 并且е°Ҷе®ғ移еҠЁеҲ°й“ҫиЎЁе°ҫйғЁ гҖӮ еҜ№еә”зҡ„ж“ҚдҪңе’ҢдёҠйқўзҡ„жҹҘжүҫжҳҜдёҖж ·зҡ„ пјҢ еҸӘдёҚиҝҮеӨҡдәҶдёҖдёӘжӣҙж–°HashMapзҡ„жӯҘйӘӨ пјҢ иҝҷжІЎд»Җд№ҲеҘҪиҜҙзҡ„ пјҢ еӨ§е®¶еә”иҜҘйғҪиғҪжғіжҳҺзҷҪ гҖӮ
第дәҢз§Қжғ…еҶөе°ұжҳҜиҰҒжӣҙж–°зҡ„еҖјеңЁй“ҫиЎЁеҪ“дёӯдёҚеӯҳеңЁ пјҢ иҝҷд№ҹдјҡжңүдёӨз§Қжғ…еҶө пјҢ 第дёҖдёӘжғ…еҶөжҳҜзј“еӯҳеҪ“дёӯзҡ„ж•°йҮҸиҝҳжІЎжңүиҫҫеҲ°йҷҗеҲ¶ пјҢ йӮЈд№ҲжҲ‘们зӣҙжҺҘж·»еҠ еңЁй“ҫиЎЁз»“е°ҫеҚіеҸҜ гҖӮ 第дәҢз§Қжғ…еҶөжҳҜй“ҫиЎЁзҺ°еңЁе·Із»Ҹж»ЎдәҶ пјҢ жҲ‘们йңҖиҰҒ移йҷӨжҺүдёҖдёӘе…ғзҙ жүҚеҸҜд»Ҙж”ҫе…Ҙж–°зҡ„ж•°жҚ® гҖӮ иҝҷдёӘж—¶еҖҷжҲ‘们йңҖиҰҒеҲ йҷӨй“ҫиЎЁзҡ„第дёҖдёӘе…ғзҙ пјҢ дёҚд»…д»…жҳҜй“ҫиЎЁеҪ“дёӯеҲ йҷӨе°ұеҸҜд»ҘдәҶ пјҢ иҝҳйңҖиҰҒеңЁHashMapеҪ“дёӯд№ҹеҲ йҷӨеҜ№еә”зҡ„еҖј пјҢ еҗҰеҲҷиҝҳжҳҜдјҡеҚ жҚ®дёҖд»ҪеҶ…еӯҳ гҖӮ
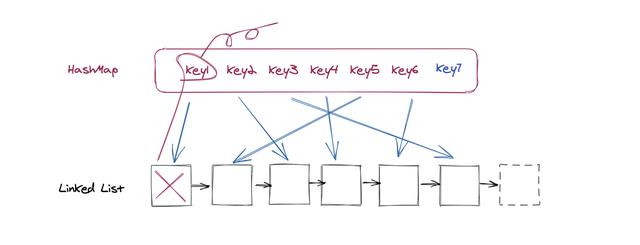
еӣ дёәжҲ‘们иҰҒиҝӣиЎҢй“ҫиЎЁеҲ°HashMapзҡ„еҸҚеҗ‘еҲ йҷӨж“ҚдҪң пјҢ жүҖд»Ҙй“ҫиЎЁеҪ“дёӯзҡ„иҠӮзӮ№дёҠд№ҹйңҖиҰҒи®°еҪ•дёӢKeyеҖј пјҢ еҗҰеҲҷзҡ„иҜқеҲ йҷӨе°ұжІЎеҠһжі•дәҶ гҖӮ еҲ йҷӨд№ӢеҗҺеҶҚеҠ е…Ҙж–°зҡ„иҠӮзӮ№ пјҢ иҝҷдёӘйғҪеҫҲз®ҖеҚ•пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫжҲ‘们зҗҶйЎәдәҶж•ҙдёӘиҝҮзЁӢд№ӢеҗҺжқҘзңӢд»Јз Ғпјҡ
class Node:def __init__(self, key, val, prev=None, succ=None):self.key = keyself.val = val# еүҚй©ұself.prev = prev# еҗҺ继self.succ = succdef __repr__(self):return str(self.val)class LinkedList:def __init__(self):self.head = Node(None, 'header')self.tail = Node(None, 'tail')self.head.succ = self.tailself.tail.prev = self.headdef append(self, node):# е°ҶnodeиҠӮзӮ№ж·»еҠ еңЁй“ҫиЎЁе°ҫйғЁprev = self.tail.prevnode.prev = prevnode.succ = prev.succprev.succ = nodenode.succ.prev = nodedef delete(self, node):# еҲ йҷӨиҠӮзӮ№prev = node.prevsucc = node.succsucc.prev, prev.succ = prev, succdef get_head(self):# иҝ”еӣһ第дёҖдёӘиҠӮзӮ№return self.head.succclass LRU:def __init__(self, cap=100):# capеҚіcapacity пјҢ е®№йҮҸself.cap = capself.cache = {}self.linked_list = LinkedList()def get(self, key):if key not in self.cache:return Noneself.put_recently(key)return self.cache[key]def put_recently(self, key):# жҠҠиҠӮзӮ№жӣҙж–°еҲ°й“ҫиЎЁе°ҫйғЁnode = self.cache[key]self.linked_list.delete(node)self.linked_list.append(node)def put(self, key, value):# иғҪжҹҘеҲ°зҡ„иҜқе…ҲеҲ йҷӨеҺҹж•°жҚ®еҶҚжӣҙж–°if key in self.cache:self.linked_list.delete(self.cache[key])self.cache[key] = Node(key, value)self.linked_list.append(self.cache[key])returnif len(self.cache) >= self.cap:# еҰӮжһңе®№йҮҸе·Із»Ҹж»ЎдәҶ пјҢ еҲ йҷӨжңҖж—§зҡ„иҠӮзӮ№node = self.linked_list.get_head()self.linked_list.delete(node)del self.cache[node.key]u = Node(key, value)self.linked_list.append(u)self.cache[key] = u
жҺЁиҚҗйҳ…иҜ»
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- жһҒйҖҹйІЁиҜҫе Ӯ85пјҡжҳҫеҚЎжҖҺд№ҲжөӢиҜ• 3DMARKиҜҰи§Ј
- йӣ·еҶӣпјҡ2021е№ҙзҡ„第дёҖ件еӨ§дәӢпјҢз»ҷе·ҘзЁӢеёҲеҸ‘зҷҫдёҮзҫҺйҮ‘еӨ§еҘ–
- ж—Ҙжң¬е·ҘзЁӢеёҲпјҡжҪҳеӨҡжӢүйӯ”зӣ’иў«зҫҺеӣҪжү“ејҖпјҢдёӯеӣҪеҠһиҠҜзүҮеӨ§еӯҰеҸӘдёәжү“з ҙзҰҒд»Ө
- жҖ§иғҪзҝ»еҖҚпјҒйЈһи…ҫйҰ–ж¬ҫ8ж ёжЎҢйқўеӨ„зҗҶеҷЁи…ҫй”җD2000иҜҰи§Ј
- д»Һе·ҘзЁӢеёҲеҲ°вҖңж°ҙжһңзҢҺдәәвҖқд»–еңЁзҷҫеәҰеҒҡ科жҷ®
- е№ҙд»Јж„ҹеҚҒи¶іпјҒеүҚиӢ№жһңе·ҘзЁӢеёҲж”ҫеҮәеҲқд»ЈiPhoneз”ҹдә§зәҝз…§зүҮ
- иғҪиЈ…иҝӣеҸЈиўӢзҡ„е·ҘзЁӢеёҲиҝҗз»ҙ笔记жң¬пјҡеЈ№еҸ·жң¬еЈ№еҸ·е·ҘзЁӢеёҲPC A1
- еёғеұҖAIиҚҜзү©з ”еҸ‘пјҒеҚҺдёәжӢӣиҒҳиҚҜзү©з ”еҸ‘з®—жі•е·ҘзЁӢеёҲпјҢж—©жңүеҮҶеӨҮиҝӣеҶӣеҢ»з–—иЎҢдёҡпјҹ
- зҪ‘йҖҹеҶҚзҝ»еҖҚпјҢе®ҳж–№иҜҰи§Је°Ҹзұі 11 жҗӯиҪҪзҡ„ WiFi 6 еўһејәзүҲжҠҖжңҜ
- и…ҫи®Ҝж•°жҚ®е·ҘзЁӢеёҲжҺЁиҚҗзҡ„Pythonж–°жүӢе…Ҙй—Ёд№ҰзұҚпјҢиҝҳжҳҜйҰ–еҸ‘з”өеӯҗзүҲ














