技嘉RTX 3060 Ti GAMING OC PRO 魔鹰显卡评测:性能飞跃 温度更“嘉”( 三 )
而光线追踪最耗时的正是求交计算 , 因此 , 要提升光线追踪性能 , 主要是对两种求交(BVH/三角形求交)进行加速 。
 文章插图
文章插图
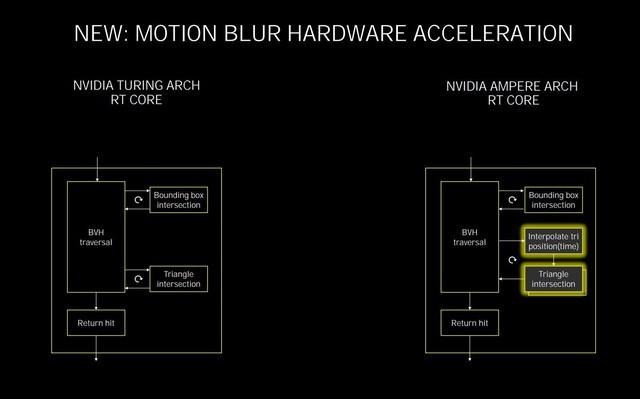
RT Core的变化
在Turing的RT Core中 , 可以每个周期完成5次BVH遍历、4次BVH求交以及一次三角形求交 , 在第二代RT Core 里 , NVIDIA增加了一个新的三角形位置插值模块以及一个的额外的三角形求交模块 , 这样做的目的是为了提升诸如运动模糊特效时候的光线追踪性能 。
 文章插图
文章插图
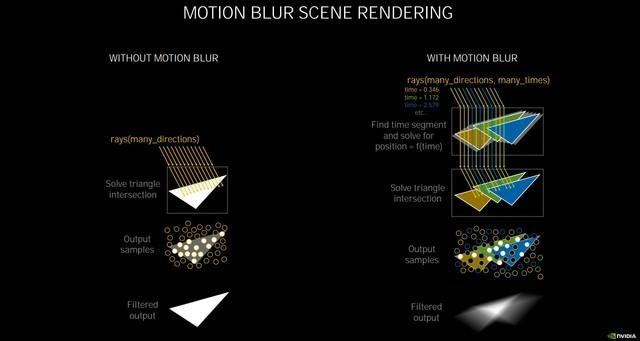
运动模糊渲染原理
第二代RT Core可以让光线追踪与着色同时进行 , 进行的光线追踪越多 , 加速就越快 , 它将光线相交的处理性能提升了一倍 , 在渲染有动态模糊的影像时 , 按照NVIDIA自己的实测 , 比Turing快8倍 。
 文章插图
文章插图
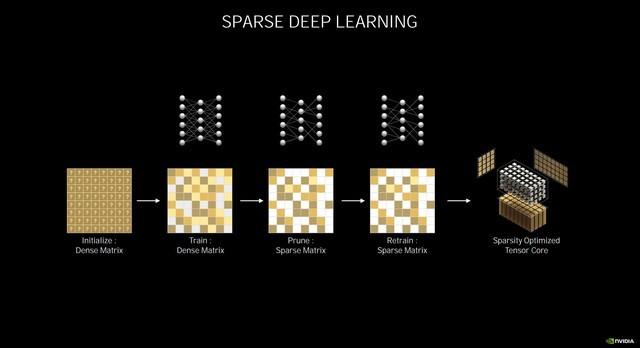
稀疏深度学习
Tensor Core可以看作是GeForce RTX GPU上的AI大脑 。 可加速用于深度神经网络处理功能的线性代数 , 这是现代AI的基础 。 例如用于AI超分辨率的NVIDIA DLSS和用于AI增强的声画处理技术NVIDIA Broadcast应用 。
在本次的NVIDIA Ampere架构的Tensor Core也得到了极大地加强 , 在第三代Tensor Core中 , NVIDIA引入了稀疏化加速 , 可自动识别并消除不太重要的DNN(深度神经网络)权重 , 同时依然能保持不错的精度 。
首先原始的密集矩阵会经过训练 , 删除掉稀疏矩阵 , 再经过训练稀疏矩阵 , 从而实现稀疏优化 , 进而提高Tensor Core的性能 。
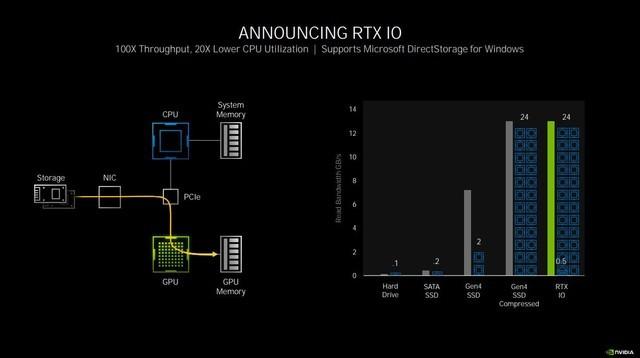
与此次RTX 30系显卡一同发布的还有一项新技术——RTX IO 。 目前很多游戏动辄几十G甚至百G的安装空间 , 对于存储空间的负担暂且不提 , 但存放在硬盘中的数据 , 如果显卡想要读取到 , 需要先由CPU从硬盘中读取压缩过的数据 , 经过解压缩再发送到显存中 。
虽然随着NVMe SSD的推出 , 读取速度相较机械硬盘能够快20倍 , 但受制于传统I/O限制 , NVMe高达7GB/秒的高速读写对于CPU是极大的负担 。
 文章插图
文章插图
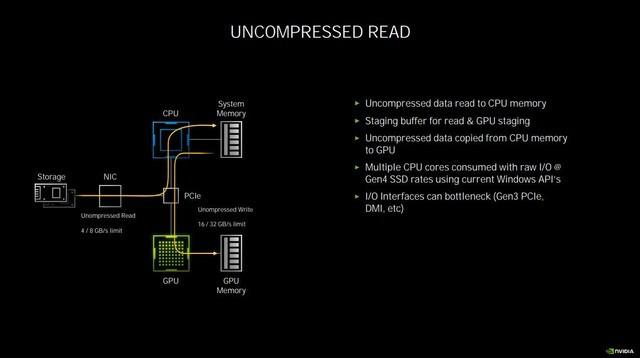
传统的数据交换
在这个过程中 , 会占用多个CPU核心 , 压力急剧增大 , 占用较多的内存 , 而此时其实GPU是处于闲置状态的 。 RTX IO的作用就是越过CPU解压再传输数据这一步 , 直接从PCIE总线读取硬盘上经过压缩的数据 , 并且完成无损GPU解压 , 降低CPU占用 , 变向提升了性能 。
 文章插图
文章插图
RTX IO可以极大解放CPU负担
当然这项技术作为系统底层的运行方式改变 , 还需要借助微软发布的DirectStorage来实现 , 对于目前容量的游戏来说 , RTX IO的改善效果有限 , 但假以时日等游戏容量上百G成为常态的时候 , 这项技术将会发挥巨大的功效 。
03 测试平台简介
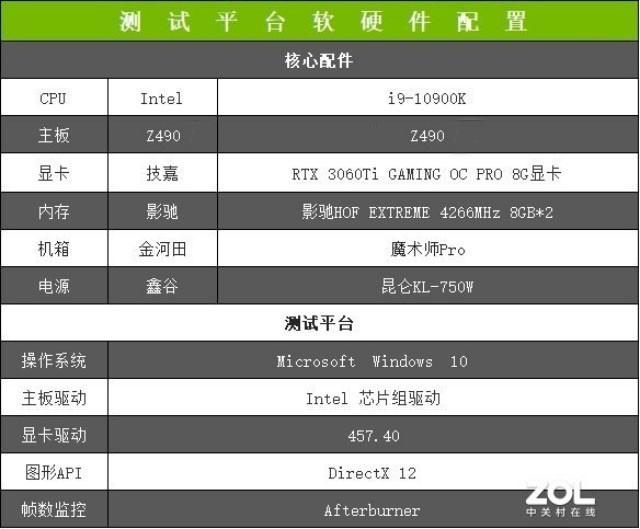
首先介绍一下测试平台 , 为了保证此次评测能够发挥技嘉RTX 3060 Ti GAMING OC PRO 魔鹰显卡的最佳性能 , 主板和CPU采用了目前桌面旗舰级配置 , 具体如下 。
 文章插图
文章插图
配置信息
在测试成绩上 , 基准测试采用3D MARK , 游戏性能测试使用游戏自带Benchmark取游戏平均帧数 。
 文章插图
文章插图
GPU-Z
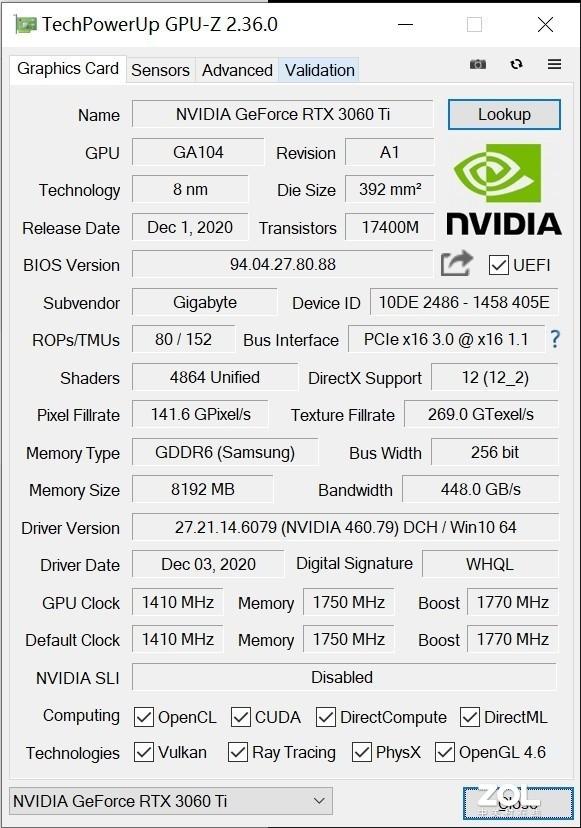
首先看一下GPU-Z的参数 , 软件更新到2.36已经可以正确显示核心并修复了纹理单元识别错误的情况 。 RTX 3060 Ti采用GA104核心 , 三星8nm工艺 , 芯片面积392平方毫米 , 拥有4864个CUDA , 技嘉RTX 3060 Ti GAMING OC PRO 魔鹰显卡的频率为1410-1770MHz 。 频率相较于公版要更高一些 , 显卡采用8GB GDDR6显存 , 位宽为256bit , 显存带宽达到了448GB/s , 光栅单元和纹理单元为80和152 。
推荐阅读








![[豪情NBA]詹姆斯又有夺冠帮手,爵士双核关系破裂!15分13篮板悍将或去湖人](https://imgcdn.toutiaoyule.com/20200413/20200413134117924521a_t.jpeg)







- 华硕RTX 3060 Ultra 12GB GDDR6显卡曝光 或售449美元
- RTX 3060突然改名RTX 3060 Ultra!12GB显存超过RTX 3080
- 微星预热新一代游戏本:RTX 30系显卡王者降临
- TACHY披露Vortex 15游戏笔记本:R7-5800H与RTX 3060加持
- 微星倾全力打造的旗舰!微星RTX 3080超龙评测:4K追平RX 6900 XT
- 爽玩光追大作,RTX 3060Ti性价比电脑推荐
- RTX 3080/3070笔记本显卡规格实锤:大幅阉割
- 妈妈心灵手巧 为儿子制作RTX3080造型生日蛋糕
- 威刚联手技嘉、微星调试DDR5内存:单条64GB、频率8400MHz
- 技嘉新发H470主板:明确支持11代酷睿