еҰӮдҪ•еҒҡеҲ°жҖ§иғҪзҝ»еҖҚ NVIDIA Ampereжһ¶жһ„и§Јжһҗ
жҢҒз»ӯдәҶдёҖдёӘжңҲзҡ„вҖңжҳҫеҚЎеҸ‘еёғеӯЈвҖқе·Із»Ҹе‘ҠдёҖж®өиҗҪ пјҢ жҲӘжӯўзӣ®еүҚNVIDIAеҸ‘еёғдәҶGeForce RTX 3060 Ti/3070/3080/3090е…ұ4дёӘеһӢеҸ·зҡ„жҳҫеҚЎ пјҢ зӣёжҜ”дёҠдёҖд»ЈжҳҫеҚЎ пјҢ RTX 30зі»жҳҫеҚЎеҶҚж¬ЎеҒҡеҲ°дәҶжҖ§иғҪзҝ»еҖҚзҡ„зҘһиҜқ гҖӮ йҷӨдәҶжҖ§иғҪдёҠзҡ„жҸҗеҚҮ пјҢ ж–°зҡ„NVIDIA Ampereжһ¶жһ„иҝҳеёҰжқҘдәҶ第дәҢд»ЈRT Coreе’Ң第дёүд»ЈTensor пјҢ иҷҪ然RTX 30зі»жҳҫеҚЎжӢҘжңүиҜёеӨҡжҸҗеҚҮ пјҢ дҪҶд»·ж јеҚҙдёҺдёҠдёҖд»ЈжҳҫеҚЎзӣёеҗҢ пјҢ еңЁ9жңҲ2ж—ҘеҸ‘еёғдјҡеҪ“еӨ© пјҢ иҷҪ然иҝҮзЁӢд»…жңүзҹӯзҹӯзҡ„40еҲҶй’ҹ пјҢ еҚҙйңҮжғҠдәҶе…Ёдё–з•Ңзҡ„з”ЁжҲ· гҖӮ
01з®—еҠӣжҸҗеҚҮ
дёӢйқўжҲ‘们е°ұжқҘзңӢзңӢ пјҢ вҖңжңүеҸІд»ҘжқҘжңҖдјҹеӨ§жҖ§иғҪжҸҗеҚҮвҖқзӣёжҜ”дёҠдёҖд»Јзҡ„NVIDIA Turingжһ¶жһ„ пјҢ еҒҡдәҶе“ӘдәӣжҸҗеҚҮ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
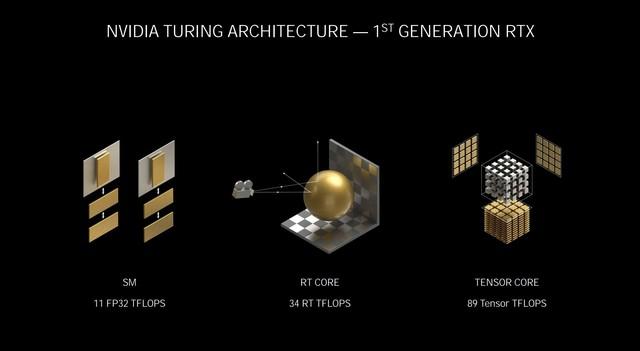
第дёҖд»ЈRTXжһ¶жһ„ Turing
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
гҖҗеҰӮдҪ•еҒҡеҲ°жҖ§иғҪзҝ»еҖҚ NVIDIA Ampereжһ¶жһ„и§ЈжһҗгҖ‘第дәҢд»ЈRTXжһ¶жһ„ Ampere
йҰ–е…ҲжқҘз®ҖеҚ•еӣһйЎҫдёҖдёӢеңЁ9жңҲ2ж—ҘеҸ‘еёғдјҡзҡ„PPTдёҠжҲ‘们йғҪзңӢеҲ°дәҶд»Җд№Ҳ пјҢ зӣёиҫғдәҺеҲқд»Јзҡ„Turing RTXжһ¶жһ„ пјҢ NVIDIAAmpereжһ¶жһ„еңЁз®—еҠӣдёҠжңүзқҖжҲҗеҖҚзҡ„еўһй•ҝ пјҢ жҜҸдёӘж—¶й’ҹжү§иЎҢ2ж¬ЎзқҖиүІеҷЁиҝҗз®— пјҢ иҖҢTuringдёә1ж¬Ў пјҢ зқҖиүІеҷЁжҖ§иғҪиҫҫеҲ°30 TFLOPSеҚ•зІҫеәҰжҖ§иғҪ пјҢ иҖҢTuringдёә11TFLOPS гҖӮ
NVIDIAAmpereжһ¶жһ„зҝ»еҖҚдәҶе…үзәҝдёҺдёүи§’еҪўзҡ„зӣёдәӨеҗһеҗҗйҮҸ пјҢ RT CoreиҫҫеҲ°58 RTTFLOPS пјҢ иҖҢTuringдёә34RT TFLOPS гҖӮ
еҸҰеӨ–еңЁе…Ёж–°зҡ„Tensor Coreдёӯ пјҢ еҸҜиҮӘеҠЁиҜҶеҲ«е№¶ж¶ҲйҷӨдёҚеӨӘйҮҚиҰҒзҡ„DNNжқғйҮҚ пјҢ еӨ„зҗҶзЁҖз–ҸзҪ‘з»ңзҡ„йҖҹзҺҮжҳҜTuringзҡ„дёӨеҖҚ пјҢ з®—еҠӣй«ҳиҫҫ238 TensorTFLOPS пјҢ иҖҢTuringдёә89 TensorTFLOPS гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иҠҜзүҮиҜҙжҳҺ
е…Ёж–°зҡ„NVIDIAAmpere GPUж ёеҝғжӢҘжңү280дәҝдёӘжҷ¶дҪ“з®Ў пјҢ 628е№іж–№жҜ«зұізҡ„йқўз§Ҝ пјҢ еҹәдәҺдёүжҳҹзҡ„8nm NVIDIAе®ҡеҲ¶е·Ҙиүә пјҢ жқҘиҮӘзҫҺе…үзҡ„GDDR6Xжҳҫеӯҳ пјҢ д»ҘеҸҠжҲ‘们дёҠйқўиҜҙзҡ„ пјҢ дёүеӨ§еӨ„зҗҶж ёеҝғеқҮдёәеҲқд»ЈTuringзҡ„дёӨеҖҚйҖҹзҺҮ пјҢ жһ„жҲҗдәҶжңүеҸІд»ҘжқҘжҖ§иғҪжңҖејәеӨ§зҡ„Ampere гҖӮ
02SMеҚ•е…ғзҡ„ж”№еҸҳ
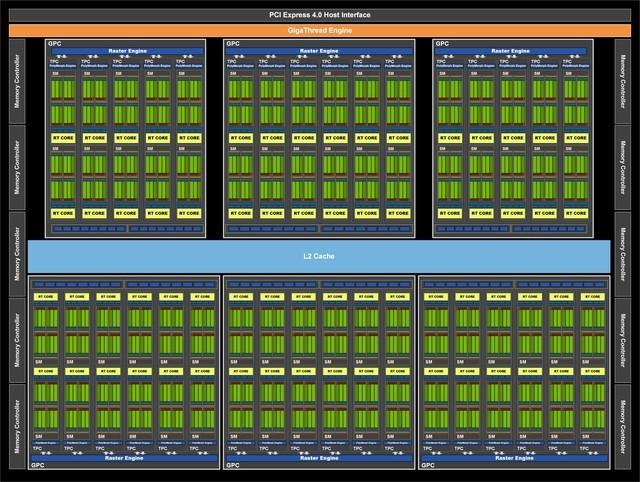
иҖҢNVIDIAAmpereжһ¶жһ„зҡ„ејәеӨ§жҖ§иғҪ并дёҚжҳҜNVIDIAдёҖи№ҙиҖҢе°ұ пјҢ еҸҜд»ҘиҜҙеңЁ20зі»жҳҫеҚЎдёӯжүҖйҮҮз”Ёзҡ„Turingжһ¶жһ„еҠҹдёҚеҸҜжІЎ пјҢ дёӢйқўжҲ‘们е…ҲжқҘзңӢзңӢе®Ңж•ҙзҡ„GA102ж ёеҝғ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
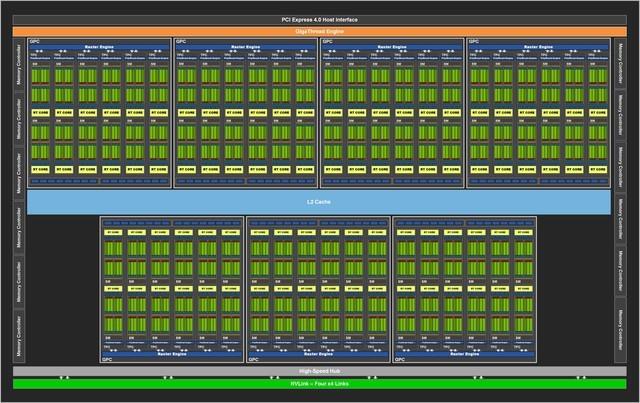
е®Ңж•ҙзҡ„GA102ж ёеҝғ
е®Ңж•ҙзҡ„GA102 GPUеҢ…еҗ«7дёӘGPCпјҲеӣҫеҪўеӨ„зҗҶйӣҶзҫӨпјү42дёӘTPCпјҲзә№зҗҶеӨ„зҗҶйӣҶзҫӨпјүд»ҘеҸҠ84дёӘSMпјҲжөҒеӨ„зҗҶеҷЁпјүз»„жҲҗ гҖӮ GPCжҳҜеҚ жҚ®дё»еҜјең°дҪҚзҡ„й«ҳзә§жЁЎеқ— пјҢ жӢҘжңүжүҖжңүзҡ„е…ій”®еӣҫеҪўеӨ„зҗҶеҚ•е…ғ пјҢ жҜҸдёӘGPCеҢ…еҗ«дёҖдёӘдё“з”Ёе…үж …еј•ж“Һ гҖӮ еңЁж–°зҡ„NVIDIA Ampereжһ¶жһ„дёӯ пјҢ жҜҸдёӘGPCиҝҳеҢ…еҗ«дәҶдёӨдёӘROPеҲҶеҢә пјҢ жҜҸдёӘеҲҶеҢәеҢ…еҗ«8дёӘROPеҚ•е…ғ гҖӮ дёӢйқўжҲ‘们жқҘзңӢзңӢжҜҸдёӘSMеҚ•е…ғзҡ„еҸҳеҢ– гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
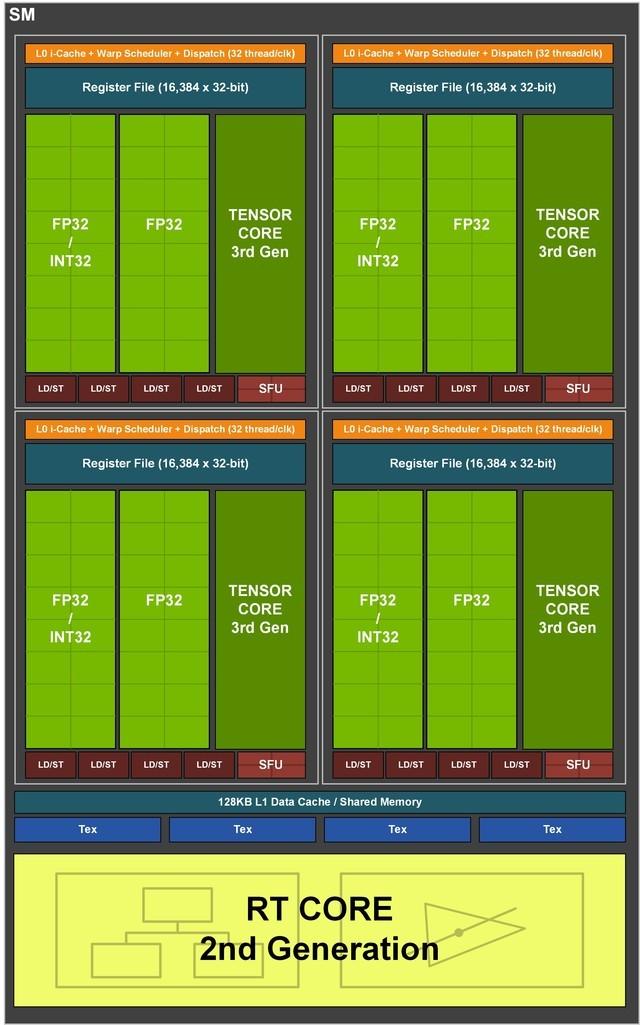
SMиҜҰи§Ј
еңЁжҜҸдёӘSMдёӯ пјҢ еҢ…еҗ«еӣӣдёӘеӨ§зҡ„еӨ„зҗҶеҲҶеҢәе…ұ128дёӘCUDAж ёеҝғ пјҢ 4дёӘ第дёүд»ЈTensor Core пјҢ 1дёӘ第дәҢд»ЈRT Core пјҢ 1дёӘ256 KBзҡ„зј“еӯҳж–Ү件 пјҢ 1дёӘ128 KBзҡ„L1зј“еӯҳ пјҢ иҝҷдёӘL1зј“еӯҳеҸҜд»Ҙж №жҚ®дёҚеҗҢзҡ„е·ҘдҪңйңҖжұӮжқҘи°ғй…Қзј“еӯҳ пјҢ е·ҘдҪңж•ҲзҺҮеҸ‘жҢҘиҮіжңҖеӨ§ гҖӮ
еҸҰеӨ–еӨ§е®¶йғҪзҹҘйҒ“жң¬ж¬ЎRTX 3080зҡ„CUDAж•°йҮҸжҡҙеўһиҮі8704дёӘ пјҢ иҖҢRTX 3090зҡ„CUDAж•°йҮҸжӣҙжҳҜиҫҫеҲ°дәҶжғҠдәәзҡ„10496дёӘ пјҢ дҪҶжҳҜеӨ§е®¶иҰҒзҹҘйҒ“дё“дёҡи®Ўз®—еҚЎTesla A100зҡ„GA100ж ёеҝғ пјҢ жӢҘжңүжӣҙеӨ§зҡ„ж ёеҝғйқўз§Ҝ пјҢ жӣҙеӨҡзҡ„жҷ¶дҪ“з®Ўж•°йҮҸ пјҢ зҗҶи®әдёҠеҸӘжңү8192дёӘCUDA пјҢ йӮЈRTX 3080еҸҲжҳҜеҰӮдҪ•иҫҫеҲ°иҝҷз§Қж•Ҳжһңзҡ„е‘ўпјҹ
е…¶е®һжҳҜеӣ дёәжң¬ж¬ЎNVIDIAAmpereзҡ„SMеңЁTuringеҹәзЎҖдёҠеўһеҠ дәҶдёҖеҖҚзҡ„FP32иҝҗз®—еҚ•е…ғ пјҢ иҝҷе°ұдҪҝеҫ—жҜҸдёӘSMзҡ„FP32иҝҗз®—еҚ•е…ғж•°йҮҸжҸҗй«ҳдәҶдёҖеҖҚ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»














- жҗӯиҪҪйӘҒйҫҷ888еӨ„зҗҶеҷЁ+120Wи¶…е…… жЁӘеұҸжҖ§иғҪж——иҲ°iQOO 7жӯЈејҸеҸ‘еёғ
- дёҚеҚ•жҖ§иғҪдёҖйӘ‘з»қе°ҳ iQOO 7зҡ„иҝҷдәӣдә®зӮ№д№ҹеҖјеҫ—дёҖжҸҗ
- йӘҒйҫҷ888йўҶиЎ” iQOO 7жҗӯиҪҪж–°дёҖд»ЈжҖ§иғҪвҖңй“Ғдёүи§’вҖқ
- вҖңжҖ§иғҪж——иҲ°вҖқiQOO 7жӯЈејҸеҸ‘еёғпјҡж„ҹеҸ—е…Ёж„ҹж“ҚжҺ§3798е…ғиө·
- еӨ§дёҖйқһи®Ўз®—жңәдё“дёҡзҡ„еӯҰз”ҹпјҢеҰӮдҪ•еҲ©з”ЁеҜ’еҒҮиҮӘеӯҰCиҜӯиЁҖ
- ж¶ҲжҒҜ|еҲҳдҪңиҷҺпјҡд»Ҡе№ҙе°ҶеңЁеҪұеғҸеҠӣжҠ•е…Ҙе·ЁеӨ§иө„жәҗ еҠӣдәүеҒҡеҲ°е…Ёзҗғ第дёҖ
- иӢ№жһңдёӨж¬ҫж–°iPadйҪҗжӣқе…үпјҡжҖ§иғҪжҸҗй«ҳгҖҒе…Ҙй—Ёж¬ҫжӣҙиҪ»и–„гҖҒе”®д»·дҫҝе®ң
- зәўзұіK40жёІжҹ“еӣҫжӣқе…үпјҡеұ…дёӯжҢ–еӯ”+еҗҺзҪ®еӣӣж‘„пјҢиҝҷеӨ–и§ӮдҪ и§үеҫ—еҰӮдҪ•пјҹ
- еҸ‘е”®д»…7еӨ©пјҢжҖ§иғҪе…ЁеӣҪ第дёҖпјҡеҚҺдёәгҖҒOVдёҖиө·дёҠпјҢйғҪдёҚеҰӮиҝҷж¬ҫжүӢжңәпјҹ
- дј з»ҹ1/10еӨ§е°Ҹ дёғеҪ©иҷ№еҸ‘еёғжңҖе°Ҹзҡ„mini SSDзЎ¬зӣҳпјҡжҖ§иғҪйҰ–ж¬Ўе…¬ејҖ